Trend analysis#
Packages#
import ee
import geemap
import pandas as pd
import numpy as np
import geopy_ee_ts_fun as geopy
try:
ee.Initialize(project="ee-pflugmacher")
except Exception as e:
ee.Authenticate()
ee.Initialize(project="ee-pflugmacher")
Set up map window#
In this exercise, we are going to map trends. First, we define a region, a coordinate reference system crs, and a scale(pixel size) or affine transformation crsTransform.
region = ee.Geometry.Polygon(
[[[12.901495385988614, 53.14672196059798],
[12.901495385988614, 52.850010520689125],
[13.426092553957364, 52.850010520689125],
[13.426092553957364, 53.14672196059798]]])
scale = 20
crs = 'EPSG:3035'
Map = geemap.Map()
Map.centerObject(region, zoom=11)
Map
Visualization parameters#
# Sentinel-2 surface reflectance
s2Vis = {"bands": ["B4", "B3", "B2"], "min":0, "max": 1200}
# NDVI color palette
ndviVis = {"palette": ['white', 'green'], "min":0.2, "max": 1}
Sentinel-2 data#
The code block below filters the Sentinel-2 collection, masks clouds and calculats NDVI. The cloud masking approach uses the AI-based Cloud Score+ available in the Cloud Score+ Harmonized-S2 dataset. The Sentinel-2 harmonized dataset fixes different scaling factors in the original Sentinel-2 dataset.
dateFilter = ee.Filter.And(ee.Filter.dayOfYear(200, 365),
ee.Filter.date(ee.Date.fromYMD(2018, 1, 1),
ee.Date.fromYMD(2021, 12, 31)))
# Harmonized Sentinel-2 Level 2A collection.
s2 = ee.ImageCollection('COPERNICUS/S2_SR_HARMONIZED')
# Cloud Score+ image collection. Note Cloud Score+ is produced from Sentinel-2
# Level 1C data and can be applied to either L1C or L2A collections.
csPlus = ee.ImageCollection('GOOGLE/CLOUD_SCORE_PLUS/V1/S2_HARMONIZED')
# Use 'cs' or 'cs_cdf', depending on your use case; see docs for guidance.
QA_BAND = 'cs_cdf'
# The threshold for masking; values between 0.50 and 0.65 generally work well.
# Higher values will remove thin clouds, haze & cirrus shadows.
CLEAR_THRESHOLD = 0.60
def mask_s2(image):
return image.updateMask(image.select(QA_BAND).gte(CLEAR_THRESHOLD))
s2m = s2.filterBounds(region) \
.filter(dateFilter) \
.linkCollection(csPlus, [QA_BAND]) \
.map(mask_s2)
# Create NDVI Collection from masked Sentinel-2 data
ndviS2 = s2m.map(geopy.calcNdviS2)
ndviS2
- type:ImageCollection
- id:COPERNICUS/S2_SR_HARMONIZED
- version:1737911578969955
- 0:1490659200000
- 1:1647907200000
- description:
Sentinel-2 is a wide-swath, high-resolution, multi-spectral imaging mission supporting Copernicus Land Monitoring studies, including the monitoring of vegetation, soil and water cover, as well as observation of inland waterways and coastal areas.
The Sentinel-2 L2 data are downloaded from scihub. They were computed by running sen2cor. WARNING: ESA did not produce L2 data for all L1 assets, and earlier L2 coverage is not global.
The assets contain 12 UINT16 spectral bands representing SR scaled by 10000 (unlike in L1 data, there is no B10). There are also several more L2-specific bands (see band list for details). See the Sentinel-2 User Handbook for details. In addition, three QA bands are present where one (QA60) is a bitmask band with cloud mask information. For more details, see the full explanation of how cloud masks are computed.
EE asset ids for Sentinel-2 L2 assets have the following format: COPERNICUS/S2_SR/20151128T002653_20151128T102149_T56MNN. Here the first numeric part represents the sensing date and time, the second numeric part represents the product generation date and time, and the final 6-character string is a unique granule identifier indicating its UTM grid reference (see MGRS).
Clouds can be removed by using COPERNICUS/S2_CLOUD_PROBABILITY. See this tutorial explaining how to apply the cloud mask.
For more details on Sentinel-2 radiometric resolution, see this page.
Provider: European Union/ESA/Copernicus
Revisit Interval
5 daysBands
Name Description B1 Aerosols
B2 Blue
B3 Green
B4 Red
B5 Red Edge 1
B6 Red Edge 2
B7 Red Edge 3
B8 NIR
B8A Red Edge 4
B9 Water vapor
B11 SWIR 1
B12 SWIR 2
AOT Aerosol Optical Thickness
WVP Water Vapor Pressure. The height the water would occupy if the vapor were condensed into liquid and spread evenly across the column.
SCL Scene Classification Map (The "No Data" value of 0 is masked out)
TCI_R True Color Image, Red channel
TCI_G True Color Image, Green channel
TCI_B True Color Image, Blue channel
MSK_CLDPRB Cloud Probability Map (missing in some products)
MSK_SNWPRB Snow Probability Map (missing in some products)
QA10 Always empty
QA20 Always empty
QA60 Cloud mask
Bitmask for QA60 -
Bit 10: Opaque clouds
- 0: No opaque clouds
- 1: Opaque clouds present
-
Bit 11: Cirrus clouds
- 0: No cirrus clouds
- 1: Cirrus clouds present
Image Properties
Name Type Description AOT_RETRIEVAL_ACCURACY DOUBLE Accuracy of Aerosol Optical thickness model
CLOUDY_PIXEL_PERCENTAGE DOUBLE Granule-specific cloudy pixel percentage taken from the original metadata
CLOUD_COVERAGE_ASSESSMENT DOUBLE Cloudy pixel percentage for the whole archive that contains this granule. Taken from the original metadata
CLOUDY_SHADOW_PERCENTAGE DOUBLE Percentage of pixels classified as cloud shadow
DARK_FEATURES_PERCENTAGE DOUBLE Percentage of pixels classified as dark features or shadows
DATASTRIP_ID STRING Unique identifier of the datastrip Product Data Item (PDI)
DATATAKE_IDENTIFIER STRING Uniquely identifies a given Datatake. The ID contains the Sentinel-2 satellite, start date and time, absolute orbit number, and processing baseline.
DATATAKE_TYPE STRING MSI operation mode
DEGRADED_MSI_DATA_PERCENTAGE DOUBLE Percentage of degraded MSI and ancillary data
FORMAT_CORRECTNESS STRING Synthesis of the On-Line Quality Control (OLQC) checks performed at granule (Product_Syntax) and datastrip (Product Syntax and DS_Consistency) levels
GENERAL_QUALITY STRING Synthesis of the OLQC checks performed at the datastrip level (Relative_Orbit_Number)
GENERATION_TIME DOUBLE Product generation time
GEOMETRIC_QUALITY STRING Synthesis of the OLQC checks performed at the datastrip level (Attitude_Quality_Indicator)
GRANULE_ID STRING Unique identifier of the granule PDI (PDI_ID)
HIGH_PROBA_CLOUDS_PERCENTAGE DOUBLE Percentage of pixels classified as high probability clouds
MEAN_INCIDENCE_AZIMUTH_ANGLE_B1 DOUBLE Mean value containing viewing incidence azimuth angle average for band B1 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B2 DOUBLE Mean value containing viewing incidence azimuth angle average for band B2 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B3 DOUBLE Mean value containing viewing incidence azimuth angle average for band B3 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B4 DOUBLE Mean value containing viewing incidence azimuth angle average for band B4 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B5 DOUBLE Mean value containing viewing incidence azimuth angle average for band B5 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B6 DOUBLE Mean value containing viewing incidence azimuth angle average for band B6 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B7 DOUBLE Mean value containing viewing incidence azimuth angle average for band B7 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B8 DOUBLE Mean value containing viewing incidence azimuth angle average for band B8 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B8A DOUBLE Mean value containing viewing incidence azimuth angle average for band B8a and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B9 DOUBLE Mean value containing viewing incidence azimuth angle average for band B9 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B10 DOUBLE Mean value containing viewing incidence azimuth angle average for band B10 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B11 DOUBLE Mean value containing viewing incidence azimuth angle average for band B11 and for all detectors
MEAN_INCIDENCE_AZIMUTH_ANGLE_B12 DOUBLE Mean value containing viewing incidence azimuth angle average for band B12 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B1 DOUBLE Mean value containing viewing incidence zenith angle average for band B1 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B2 DOUBLE Mean value containing viewing incidence zenith angle average for band B2 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B3 DOUBLE Mean value containing viewing incidence zenith angle average for band B3 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B4 DOUBLE Mean value containing viewing incidence zenith angle average for band B4 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B5 DOUBLE Mean value containing viewing incidence zenith angle average for band B5 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B6 DOUBLE Mean value containing viewing incidence zenith angle average for band B6 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B7 DOUBLE Mean value containing viewing incidence zenith angle average for band B7 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B8 DOUBLE Mean value containing viewing incidence zenith angle average for band B8 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B8A DOUBLE Mean value containing viewing incidence zenith angle average for band B8a and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B9 DOUBLE Mean value containing viewing incidence zenith angle average for band B9 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B10 DOUBLE Mean value containing viewing incidence zenith angle average for band B10 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B11 DOUBLE Mean value containing viewing incidence zenith angle average for band B11 and for all detectors
MEAN_INCIDENCE_ZENITH_ANGLE_B12 DOUBLE Mean value containing viewing incidence zenith angle average for band B12 and for all detectors
MEAN_SOLAR_AZIMUTH_ANGLE DOUBLE Mean value containing sun azimuth angle average for all bands and detectors
MEAN_SOLAR_ZENITH_ANGLE DOUBLE Mean value containing sun zenith angle average for all bands and detectors
MEDIUM_PROBA_CLOUDS_PERCENTAGE DOUBLE Percentage of pixels classified as medium probability clouds
MGRS_TILE STRING US-Military Grid Reference System (MGRS) tile
NODATA_PIXEL_PERCENTAGE DOUBLE Percentage of No Data pixels
NOT_VEGETATED_PERCENTAGE DOUBLE Percentage of pixels classified as non-vegetated
PROCESSING_BASELINE STRING Configuration baseline used at the time of the product generation in terms of processor software version and major Ground Image Processing Parameters (GIPP) version
PRODUCT_ID STRING The full id of the original Sentinel-2 product
RADIATIVE_TRANSFER_ACCURACY DOUBLE Accuracy of radiative transfer model
RADIOMETRIC_QUALITY STRING Based on the OLQC reports contained in the Datastrips/QI_DATA with RADIOMETRIC_QUALITY checklist name
REFLECTANCE_CONVERSION_CORRECTION DOUBLE Earth-Sun distance correction factor
SATURATED_DEFECTIVE_PIXEL_PERCENTAGE DOUBLE Percentage of saturated or defective pixels
SENSING_ORBIT_DIRECTION STRING Imaging orbit direction
SENSING_ORBIT_NUMBER DOUBLE Imaging orbit number
SENSOR_QUALITY STRING Synthesis of the OLQC checks performed at granule (Missing_Lines, Corrupted_ISP, and Sensing_Time) and datastrip (Degraded_SAD and Datation_Model) levels
SOLAR_IRRADIANCE_B1 DOUBLE Mean solar exoatmospheric irradiance for band B1
SOLAR_IRRADIANCE_B2 DOUBLE Mean solar exoatmospheric irradiance for band B2
SOLAR_IRRADIANCE_B3 DOUBLE Mean solar exoatmospheric irradiance for band B3
SOLAR_IRRADIANCE_B4 DOUBLE Mean solar exoatmospheric irradiance for band B4
SOLAR_IRRADIANCE_B5 DOUBLE Mean solar exoatmospheric irradiance for band B5
SOLAR_IRRADIANCE_B6 DOUBLE Mean solar exoatmospheric irradiance for band B6
SOLAR_IRRADIANCE_B7 DOUBLE Mean solar exoatmospheric irradiance for band B7
SOLAR_IRRADIANCE_B8 DOUBLE Mean solar exoatmospheric irradiance for band B8
SOLAR_IRRADIANCE_B8A DOUBLE Mean solar exoatmospheric irradiance for band B8a
SOLAR_IRRADIANCE_B9 DOUBLE Mean solar exoatmospheric irradiance for band B9
SOLAR_IRRADIANCE_B10 DOUBLE Mean solar exoatmospheric irradiance for band B10
SOLAR_IRRADIANCE_B11 DOUBLE Mean solar exoatmospheric irradiance for band B11
SOLAR_IRRADIANCE_B12 DOUBLE Mean solar exoatmospheric irradiance for band B12
SNOW_ICE_PERCENTAGE DOUBLE Percentage of pixels classified as snow or ice
SPACECRAFT_NAME STRING Sentinel-2 spacecraft name: Sentinel-2A, Sentinel-2B
THIN_CIRRUS_PERCENTAGE DOUBLE Percentage of pixels classified as thin cirrus clouds
UNCLASSIFIED_PERCENTAGE DOUBLE Percentage of unclassified pixels
VEGETATION_PERCENTAGE DOUBLE Percentage of pixels classified as vegetation
WATER_PERCENTAGE DOUBLE Percentage of pixels classified as water
WATER_VAPOUR_RETRIEVAL_ACCURACY DOUBLE Declared accuracy of the Water Vapor model
Terms of Use
The use of Sentinel data is governed by the Copernicus Sentinel Data Terms and Conditions.
-
Bit 10: Opaque clouds
- 0:copernicus
- 1:esa
- 2:eu
- 3:msi
- 4:reflectance
- 5:sentinel
- 6:sr
- period:0
- 0:msi
- 1:sr
- 2:reflectance
- provider:European Union/ESA/Copernicus
- provider_url:https://earth.esa.int/web/sentinel/user-guides/sentinel-2-msi/product-types/level-2a
- sample:https://mw1.google.com/ges/dd/images/COPERNICUS_S2_SR_sample.png
- 0:eu
- 1:esa
- 2:copernicus
- 3:sentinel
- system:visualization_0_bands:B4,B3,B2
- system:visualization_0_max:3000.0
- system:visualization_0_min:0.0
- system:visualization_0_name:RGB
- 0:copernicus
- 1:esa
- 2:eu
- 3:msi
- 4:reflectance
- 5:sentinel
- 6:sr
- thumb:https://mw1.google.com/ges/dd/images/COPERNICUS_S2_SR_thumb.png
- title:Sentinel-2 MSI: MultiSpectral Instrument, Level-2A
- type_name:ImageCollection
- visualization_0_bands:B4,B3,B2
- visualization_0_max:3000.0
- visualization_0_min:0.0
- visualization_0_name:RGB
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.960614330786171
- 1:52.71941017785326
- 0:11.927708666887291
- 1:52.22676773255406
- 0:11.92776272005845
- 1:52.226727015499065
- 0:11.927801734701827
- 1:52.22668035483143
- 0:11.927831370915506
- 1:52.22667526830674
- 0:11.934838000824039
- 1:52.22614078659454
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55607952975316
- 1:52.42114486164029
- 0:13.58161886561859
- 1:52.66660123084141
- 0:13.607530553427937
- 1:52.91203851049146
- 0:13.633822764151054
- 1:53.15746474773156
- 0:13.633437765554566
- 1:53.159467177813276
- 0:13.633376785483945
- 1:53.1595000467366
- 0:13.633335209232591
- 1:53.15954237174533
- 0:13.633298339580875
- 1:53.159546662810676
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- system:index:20180721T102021_20180721T102024_T32UQD
- system:time_start:1532168424461
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.732624889894508
- 1:54.05503236114704
- 0:13.732587170485852
- 1:54.055036657003576
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058830880593415
- 1:54.10924624101911
- 0:12.023102399744792
- 1:53.617011798023775
- 0:11.988417187439408
- 1:53.12474100027239
- 0:11.988437052914845
- 1:53.12468925907736
- 0:11.989043589160126
- 1:53.124292576739364
- 0:11.989085677924557
- 1:53.124279125904785
- 0:11.991757239427336
- 1:53.12366774291128
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651119865829472
- 1:53.31698147337989
- 0:13.678068770139987
- 1:53.56250194965098
- 0:13.70541805236422
- 1:53.808002686223396
- 0:13.733176833261805
- 1:54.05349478945699
- 0:13.732727818511293
- 1:54.05496281312874
- 0:13.732665295836037
- 1:54.054991926224425
- 0:13.732624889894508
- 1:54.05503236114704
- system:index:20180721T102021_20180721T102024_T32UQE
- system:time_start:1532168424461
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.071442264024093
- 1:52.227213600836116
- 0:12.071475022533464
- 1:52.2272035469364
- 0:12.07371320152927
- 1:52.22671722029191
- 0:12.0755026698015
- 1:52.226489110350975
- 0:12.076550058001837
- 1:52.226423629512674
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663542716795288
- 1:52.74767893267264
- 0:13.64825426394492
- 1:53.23999286369247
- 0:13.647590132118513
- 1:53.24197110817552
- 0:13.647524717437888
- 1:53.242000839041744
- 0:13.64747394699918
- 1:53.24204369275026
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004609348085067
- 1:53.211994482054486
- 0:12.038479201644694
- 1:52.719657353548314
- 0:12.071377414326003
- 1:52.22728471412834
- 0:12.071424874526578
- 1:52.22725430367287
- 0:12.071442264024093
- 1:52.227213600836116
- system:index:20180721T102021_20180721T102024_T33UUU
- system:time_start:1532168424461
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.616537365236661
- 1:54.14024275663136
- 0:13.616499231047639
- 1:54.14024510787728
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940251452605162
- 1:54.10922292267334
- 0:11.976009873308227
- 1:53.616719634921594
- 0:12.01072354453829
- 1:53.12417989359036
- 0:12.01075045196927
- 1:53.124129259184116
- 0:12.011393602066347
- 1:53.1237734244422
- 0:12.0114377523853
- 1:53.12377282938776
- 0:12.011464162083108
- 1:53.12375156052333
- 0:12.011501507198535
- 1:53.12374966175586
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635303440058125
- 1:53.64598268020052
- 0:13.619169446867653
- 1:54.1382255521481
- 0:13.618509291349097
- 1:54.13914231833514
- 0:13.618481060369875
- 1:54.13916285689181
- 0:13.616608879356276
- 1:54.140219953133
- 0:13.616537365236661
- 1:54.14024275663136
- system:index:20180721T102021_20180721T102024_T33UUV
- system:time_start:1532168424461
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.768469211051766
- 1:53.190097961472695
- 0:12.768324893458804
- 1:53.19005093032283
- 0:12.573231150618888
- 1:52.74489631172392
- 0:12.382286952005213
- 1:52.29934982417884
- 0:12.353067579451608
- 1:52.221389870952486
- 0:12.351323783420217
- 1:52.21576493870386
- 0:12.35127854998626
- 1:52.21516458575552
- 0:12.351673380801673
- 1:52.21502891185066
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.556107263602584
- 1:52.42141369392922
- 0:13.581675258373929
- 1:52.66713890869132
- 0:13.60761640311881
- 1:52.91284492452808
- 0:13.633941920144505
- 1:53.15856891554009
- 0:13.633738281761895
- 1:53.15870833762378
- 0:13.631064085370566
- 1:53.15936244790652
- 0:13.626149627369033
- 1:53.15982510020692
- 0:12.768469211051766
- 1:53.190097961472695
- system:index:20180723T101019_20180723T101036_T32UQD
- system:time_start:1532340636891
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651134434395978
- 1:53.31711587996908
- 0:13.678098515333522
- 1:53.56277068731834
- 0:13.705463330989971
- 1:53.80840585076389
- 0:13.73324108828881
- 1:54.054058264541375
- 0:13.731737327023362
- 1:54.05507021813864
- 0:13.166717834905482
- 1:54.076009575677276
- 0:13.165638961609712
- 1:54.07490804029753
- 0:13.162189092507823
- 1:54.06799996687528
- 0:13.137577400998815
- 1:54.01433891384178
- 0:12.947056821624187
- 1:53.5935978930804
- 0:12.760487062099953
- 1:53.17246793313685
- 0:12.755821299254682
- 1:53.160201295644825
- 0:12.735423791462692
- 1:53.10632880421053
- 0:12.735114021734788
- 1:53.102758017862485
- 0:12.735676551546694
- 1:53.10262516092555
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20180723T101019_20180723T101036_T32UQE
- system:time_start:1532340636891
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.78570697613869
- 1:53.229117050164305
- 0:12.785630503581555
- 1:53.22910130549897
- 0:12.782390899651864
- 1:53.222008219174654
- 0:12.57966782046027
- 1:52.758947704548845
- 0:12.381058059561324
- 1:52.29556333197161
- 0:12.360300829695513
- 1:52.237632589036856
- 0:12.359205056902573
- 1:52.23381988784857
- 0:12.35923758834168
- 1:52.23327153331405
- 0:12.359281469318907
- 1:52.233243172495655
- 0:12.359293144644694
- 1:52.23320135442415
- 0:12.359652931729691
- 1:52.23310079347354
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663526191031458
- 1:52.74821812379438
- 0:13.648220557695662
- 1:53.241063185181375
- 0:13.648195602780769
- 1:53.24111417499538
- 0:13.648004401508608
- 1:53.24122456151356
- 0:13.64614569117842
- 1:53.241755995237064
- 0:13.642956427300375
- 1:53.24199239286611
- 0:12.78576190974339
- 1:53.229147840192944
- 0:12.78570697613869
- 1:53.229117050164305
- system:index:20180723T101019_20180723T101036_T33UUU
- system:time_start:1532340636891
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.751365541651337
- 1:53.140057388712236
- 0:12.75144410515941
- 1:53.1400324151271
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635286108787739
- 1:53.646521870937306
- 0:13.61913383364833
- 1:54.1392975576008
- 0:13.618963929442273
- 1:54.13966589731069
- 0:13.618894685482022
- 1:54.139722176629185
- 0:13.617466090915418
- 1:54.13998371317055
- 0:13.615137251709552
- 1:54.140229494313765
- 0:13.192378551411378
- 1:54.13462310639914
- 0:13.192243176594738
- 1:54.13457620369565
- 0:12.98515601195374
- 1:53.67845370640428
- 0:12.78239078762587
- 1:53.22200773003716
- 0:12.758292148358258
- 1:53.167066762821136
- 0:12.751121597459582
- 1:53.14102433478253
- 0:12.751166268294218
- 1:53.140169914000325
- 0:12.751365541651337
- 1:53.140057388712236
- system:index:20180723T101019_20180723T101036_T33UUV
- system:time_start:1532340636891
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.556107263602584
- 1:52.42141369392922
- 0:13.581675258373929
- 1:52.66713890869132
- 0:13.60761640311881
- 1:52.91284492452808
- 0:13.63393911428562
- 1:53.15854280129964
- 0:13.633822535888257
- 1:53.158927630005785
- 0:13.633426953531108
- 1:53.15949169766722
- 0:13.633368246491898
- 1:53.15950873859723
- 0:13.633335209232591
- 1:53.15954237174533
- 0:13.633298339580875
- 1:53.159546662810676
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- system:index:20180726T102019_20180726T102150_T32UQD
- system:time_start:1532600510652
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180726T102019_20180726T102150_T32UQE
- system:time_start:1532600510652
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663523544820487
- 1:52.748308046051896
- 0:13.648214540369866
- 1:53.24125614046068
- 0:13.648197788476516
- 1:53.241282886990625
- 0:13.647575954237254
- 1:53.24199504199104
- 0:13.647514921542278
- 1:53.2420090162442
- 0:13.647477174155377
- 1:53.24204097145684
- 0:13.647439819307769
- 1:53.24204330946181
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071555935023119
- 1:52.22629968318028
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20180726T102019_20180726T102150_T33UUU
- system:time_start:1532600510652
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.6352773442801
- 1:53.64679139495173
- 0:13.619116261145418
- 1:54.13982561351762
- 0:13.619067731256989
- 1:54.13985662448578
- 0:13.619050858860382
- 1:54.13989747127366
- 0:13.619017049964521
- 1:54.139908056403186
- 0:13.617460692699964
- 1:54.140252946302866
- 0:13.617417379829536
- 1:54.14025563916818
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- system:index:20180726T102019_20180726T102150_T33UUV
- system:time_start:1532600510652
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.556065607127538
- 1:52.421010452389304
- 0:13.58159066961051
- 1:52.66633239345884
- 0:13.607487722897671
- 1:52.91163525431119
- 0:13.633767875398599
- 1:53.156956135771225
- 0:13.633561992774878
- 1:53.15709707160498
- 0:13.630451234961177
- 1:53.15776490827061
- 0:13.618559158859552
- 1:53.16012030937187
- 0:12.769694682892538
- 1:53.1900591906425
- 0:12.759262876322119
- 1:53.16873164772079
- 0:12.561100581946624
- 1:52.7161194612099
- 0:12.493991486661045
- 1:52.56026674580765
- 0:12.35375871389961
- 1:52.230546606441436
- 0:12.35037382803776
- 1:52.22064984652689
- 0:12.350003324102433
- 1:52.21573123084029
- 0:12.351410449302222
- 1:52.21539804079086
- 0:12.354915161981074
- 1:52.21502711018175
- 0:12.356963081247088
- 1:52.21487842611743
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20180728T101031_20180728T101340_T32UQD
- system:time_start:1532772820281
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651090499482224
- 1:53.316712687632
- 0:13.67800935569872
- 1:53.561964384337706
- 0:13.705327578560773
- 1:53.8071965229136
- 0:13.733057411445587
- 1:54.05244598611923
- 0:13.732844336084975
- 1:54.052589390563746
- 0:13.728748472161186
- 1:54.053296905501206
- 0:13.723324335896885
- 1:54.05405086715738
- 0:13.711565576699984
- 1:54.05559327527506
- 0:13.706103520051412
- 1:54.05607808413924
- 0:13.167148135800883
- 1:54.07599465328478
- 0:13.159660220238326
- 1:54.061071398401715
- 0:12.943151829663007
- 1:53.583337867046424
- 0:12.731729962257452
- 1:53.105097129137945
- 0:12.731606395649054
- 1:53.10367222670196
- 0:12.73525741525411
- 1:53.102999521826256
- 0:12.73882350140421
- 1:53.102616585471864
- 0:12.740762593948723
- 1:53.10246522714415
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20180728T101031_20180728T101340_T32UQE
- system:time_start:1532772820281
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.357434048073516
- 1:52.23404610816078
- 0:12.357470676117824
- 1:52.23342793186292
- 0:12.359807407735488
- 1:52.23319503153058
- 0:12.361436280934488
- 1:52.23314074009625
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.66355095934353
- 1:52.747409299405106
- 0:13.648269050787125
- 1:53.239523624358206
- 0:13.646667524488914
- 1:53.240138210376266
- 0:13.6439293634471
- 1:53.24065142965011
- 0:13.63669314104959
- 1:53.24164933666302
- 0:13.633969767596499
- 1:53.241889679603446
- 0:12.786548971926518
- 1:53.22916246723074
- 0:12.773603444886103
- 1:53.2008053784702
- 0:12.689473010274266
- 1:53.01092468041417
- 0:12.579253616957603
- 1:52.7583996923596
- 0:12.54306271168254
- 1:52.67456853971396
- 0:12.372212062316052
- 1:52.27405500771197
- 0:12.360276500304577
- 1:52.24545809814281
- 0:12.35805698728652
- 1:52.23838674472606
- 0:12.357434048073516
- 1:52.23404610816078
- system:index:20180728T101031_20180728T101340_T33UUU
- system:time_start:1532772820281
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635320926158924
- 1:53.64544355954639
- 0:13.619205555751472
- 1:54.13714112921424
- 0:13.619034120508799
- 1:54.137512772218344
- 0:13.618517942965157
- 1:54.138366012093755
- 0:13.614744272819122
- 1:54.1388740878583
- 0:13.606888538505533
- 1:54.139864185046896
- 0:13.595384746330861
- 1:54.140000600057526
- 0:13.19643204443436
- 1:54.13468390913371
- 0:13.192382161444836
- 1:54.131338144928804
- 0:12.980730482459856
- 1:53.66651233086548
- 0:12.773575324368057
- 1:53.20134377062295
- 0:12.754315926899208
- 1:53.15728412604693
- 0:12.749173806100014
- 1:53.143957471162224
- 0:12.749345516836184
- 1:53.140674933255234
- 0:12.749886034673995
- 1:53.14036979354857
- 0:12.75219206449853
- 1:53.14013744332212
- 0:12.753555990301507
- 1:53.140072321204094
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20180728T101031_20180728T101340_T33UUV
- system:time_start:1532772820281
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180731T102021_20180731T102024_T32UQD
- system:time_start:1533032424462
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.989028201815449
- 1:53.12376767319959
- 0:11.989061444183264
- 1:53.12373555436779
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651110038781999
- 1:53.31689188247017
- 0:13.678049003733323
- 1:53.56232275630326
- 0:13.705387921333323
- 1:53.80773401729156
- 0:13.733136218060636
- 1:54.05313861782352
- 0:13.733123248428317
- 1:54.053166125699505
- 0:13.732595961561255
- 1:54.05390671084626
- 0:13.732568782683288
- 1:54.053933921060576
- 0:13.729930222640402
- 1:54.05512624833215
- 0:13.729874212227609
- 1:54.055143592994035
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058830880593415
- 1:54.10924624101911
- 0:12.023089507527029
- 1:53.61683227230523
- 0:11.98839237057704
- 1:53.12438194258893
- 0:11.988400070004074
- 1:53.12434518235158
- 0:11.988973421247017
- 1:53.12377792083878
- 0:11.989028201815449
- 1:53.12376767319959
- system:index:20180731T102021_20180731T102024_T32UQE
- system:time_start:1533032424462
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663534434266163
- 1:52.74794848842764
- 0:13.648237286357022
- 1:53.24053507372088
- 0:13.648071319713393
- 1:53.240903467578555
- 0:13.6480260995058
- 1:53.24092138141883
- 0:13.648014011697333
- 1:53.2409530299247
- 0:13.647981058988647
- 1:53.24096381917828
- 0:13.643587951684097
- 1:53.2419963039248
- 0:13.643544870562039
- 1:53.241999055760196
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071555935023119
- 1:52.22629968318028
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20180731T102021_20180731T102024_T33UUU
- system:time_start:1533032424462
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635303440058125
- 1:53.64598268020052
- 0:13.619169737304382
- 1:54.13821636457053
- 0:13.618489161759934
- 1:54.14019399008154
- 0:13.61842230091038
- 1:54.14022371874356
- 0:13.618373673705657
- 1:54.14026381028777
- 0:13.61833557967792
- 1:54.14026624227948
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- system:index:20180731T102021_20180731T102024_T33UUV
- system:time_start:1533032424462
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.556107263602584
- 1:52.42141369392922
- 0:13.581675258373929
- 1:52.66713890869132
- 0:13.60761640311881
- 1:52.91284492452808
- 0:13.633941920144505
- 1:53.15856891554009
- 0:13.633313456050255
- 1:53.158999097006514
- 0:13.628841001326169
- 1:53.159720351663914
- 0:12.774661130383473
- 1:53.18990171574269
- 0:12.772663598988249
- 1:53.188292821907694
- 0:12.770485010190642
- 1:53.18402780651025
- 0:12.75931018708689
- 1:53.15901492519813
- 0:12.595809456733091
- 1:52.786847225107984
- 0:12.435219767012288
- 1:52.41439066349475
- 0:12.359989129646985
- 1:52.237386521468956
- 0:12.351344245790607
- 1:52.21603670899558
- 0:12.351300196150227
- 1:52.21545219205164
- 0:12.351792130091425
- 1:52.215120661354035
- 0:12.352866597672085
- 1:52.214995038017065
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20180802T101019_20180802T101020_T32UQD
- system:time_start:1533204620000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.17138550046946
- 1:54.07584756508845
- 0:13.171252262175633
- 1:54.07581441742064
- 0:13.169134015802227
- 1:54.07316472988845
- 0:13.166869303130435
- 1:54.06891792904383
- 0:12.94931771673015
- 1:53.58866599275366
- 0:12.736908012662886
- 1:53.107908158677915
- 0:12.735637348344781
- 1:53.10362155971762
- 0:12.73556198280453
- 1:53.10275319706381
- 0:12.735963498813067
- 1:53.102616125003216
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651134434395978
- 1:53.31711587996908
- 0:13.678098515333522
- 1:53.56277068731834
- 0:13.705463330989971
- 1:53.80840585076389
- 0:13.73324108828881
- 1:54.054058264541375
- 0:13.732600664038904
- 1:54.054489131553865
- 0:13.728035313834663
- 1:54.0552160743992
- 0:13.17138550046946
- 1:54.07584756508845
- system:index:20180802T101019_20180802T101020_T32UQE
- system:time_start:1533204620460
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.359678213338434
- 1:52.23351098585495
- 0:12.359715746370302
- 1:52.23348181660686
- 0:12.360818774480299
- 1:52.2331269106472
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663526191031458
- 1:52.74821812379438
- 0:13.648220557695662
- 1:53.241063185181375
- 0:13.648195602780769
- 1:53.24111417499538
- 0:13.647538496420518
- 1:53.24149367314367
- 0:13.644767758341041
- 1:53.242012966541026
- 0:12.791150680901357
- 1:53.22924788026149
- 0:12.791021107478974
- 1:53.22920324043717
- 0:12.786937161754205
- 1:53.22101536177135
- 0:12.782892219217002
- 1:53.21230746591502
- 0:12.74673349752656
- 1:53.13070834834422
- 0:12.55219729818898
- 1:52.68581805944435
- 0:12.361442597317904
- 1:52.24062894590777
- 0:12.359192677629052
- 1:52.23410163872438
- 0:12.359194293752052
- 1:52.23405487850137
- 0:12.359678213338434
- 1:52.23351098585495
- system:index:20180802T101019_20180802T101020_T33UUU
- system:time_start:1533204620000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.752413741204112
- 1:53.14214125189337
- 0:12.752410164139453
- 1:53.14211877328991
- 0:12.752497859125151
- 1:53.14044113353394
- 0:12.75413291937455
- 1:53.14008316969312
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635286108787739
- 1:53.646521870937306
- 0:13.619132855502608
- 1:54.13932369204633
- 0:13.618436920482422
- 1:54.13971668292826
- 0:13.615606001126075
- 1:54.14023484017745
- 0:13.197885700448566
- 1:54.13470568721752
- 0:13.19775577957391
- 1:54.13466436286594
- 0:13.195176700926899
- 1:54.13028906454084
- 0:13.172531112534061
- 1:54.081402672471754
- 0:12.981908581217848
- 1:53.66086839687507
- 0:12.79494670119664
- 1:53.240042868104695
- 0:12.76280613004145
- 1:53.16661607385693
- 0:12.754794226990372
- 1:53.1481224163136
- 0:12.752413741204112
- 1:53.14214125189337
- system:index:20180802T101019_20180802T101020_T33UUV
- system:time_start:1533204620000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.633357618413855
- 1:53.1595195144342
- 0:13.633335209232591
- 1:53.15954237174533
- 0:13.633298339580875
- 1:53.159546662810676
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927792648067898
- 1:52.22631591510951
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.556121186408014
- 1:52.42154810396402
- 0:13.58170341578687
- 1:52.66740767064899
- 0:13.607659235356387
- 1:52.9132481875345
- 0:13.633995979234369
- 1:53.1590694356372
- 0:13.633978162674719
- 1:53.159121462768915
- 0:13.633401490829973
- 1:53.1595161654914
- 0:13.633357618413855
- 1:53.1595195144342
- system:index:20180805T102019_20180805T102019_T32UQD
- system:time_start:1533464419462
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.732647698182753
- 1:54.05500946958526
- 0:13.732624889894508
- 1:54.05503236114704
- 0:13.732587170485852
- 1:54.055036657003576
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058830880593415
- 1:54.10924624101911
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.988464475701429
- 1:53.12375052159264
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651149117735748
- 1:53.31725027345753
- 0:13.678128260800328
- 1:53.56303942595175
- 0:13.705508452993383
- 1:53.80880895129567
- 0:13.733297982438883
- 1:54.054558567686264
- 0:13.73328009363748
- 1:54.054610616676605
- 0:13.732692460597647
- 1:54.05500604971079
- 0:13.732647698182753
- 1:54.05500946958526
- system:index:20180805T102019_20180805T102019_T32UQE
- system:time_start:1533464419462
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071555935023119
- 1:52.22629968318028
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.66351794745362
- 1:52.74848776021086
- 0:13.648203622791739
- 1:53.241602382248814
- 0:13.648164805534476
- 1:53.24162767665896
- 0:13.648163298239371
- 1:53.24166203097763
- 0:13.648134367905898
- 1:53.24167645685355
- 0:13.647224260212838
- 1:53.24202567908921
- 0:13.647177561678493
- 1:53.24203756566269
- 0:13.647140206944314
- 1:53.242039903557206
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- system:index:20180805T102019_20180805T102019_T33UUU
- system:time_start:1533464419462
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010870575835755
- 1:53.123733817593966
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.6352773442801
- 1:53.64679139495173
- 0:13.619116261145418
- 1:54.13982561351762
- 0:13.61908572994588
- 1:54.1398450607633
- 0:13.619093313897366
- 1:54.139871142911055
- 0:13.619069265237474
- 1:54.139888657821565
- 0:13.618445188107259
- 1:54.14024100552822
- 0:13.618399999548247
- 1:54.140242219246396
- 0:13.618373673705657
- 1:54.14026381028777
- 0:13.61833557967792
- 1:54.14026624227948
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940251452605162
- 1:54.10922292267334
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- system:index:20180805T102019_20180805T102019_T33UUV
- system:time_start:1533464419462
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.354476323528365
- 1:52.21503958709825
- 0:12.356378170694612
- 1:52.21489513248466
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.556065607127538
- 1:52.421010452389304
- 0:13.58159066961051
- 1:52.66633239345884
- 0:13.607487722897671
- 1:52.91163525431119
- 0:13.633767875398599
- 1:53.156956135771225
- 0:13.633558762471822
- 1:53.157099288357216
- 0:13.629548527952165
- 1:53.15780133416992
- 0:13.625131651039899
- 1:53.15851346591812
- 0:13.615400166974148
- 1:53.15997242822432
- 0:13.610048851918021
- 1:53.160450679900386
- 0:12.769694682892538
- 1:53.1900591906425
- 0:12.759262913802642
- 1:53.168731727137036
- 0:12.554431751729284
- 1:52.70242338826293
- 0:12.35414487205212
- 1:52.23566271480359
- 0:12.350781996188939
- 1:52.22604184376079
- 0:12.348498531067724
- 1:52.21908370479179
- 0:12.348270232395313
- 1:52.216050325116456
- 0:12.350972062852739
- 1:52.215410456119194
- 0:12.354476323528365
- 1:52.21503958709825
- system:index:20180807T101021_20180807T101024_T32UQD
- system:time_start:1533636624457
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.737483160879737
- 1:53.10265863795928
- 0:12.739869342726745
- 1:53.102493301124134
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.651090499482224
- 1:53.316712687632
- 0:13.67800935569872
- 1:53.561964384337706
- 0:13.705327578560773
- 1:53.8071965229136
- 0:13.733057411445587
- 1:54.05244598611923
- 0:13.732847539865917
- 1:54.0525871551862
- 0:13.72966576698479
- 1:54.05326044308847
- 0:13.712479294617921
- 1:54.05555745232152
- 0:13.707017041964106
- 1:54.056042243015895
- 0:13.167153477620404
- 1:54.07599448248175
- 0:13.160468329342327
- 1:54.06455361434475
- 0:13.120205908275372
- 1:53.977696803530215
- 0:12.92931491265786
- 1:53.553975921069515
- 0:12.742405470207329
- 1:53.1298653512483
- 0:12.731729887566253
- 1:53.10509697042051
- 0:12.731609309389368
- 1:53.10370519053653
- 0:12.732102286121242
- 1:53.10337579690965
- 0:12.733915981918553
- 1:53.10304165063141
- 0:12.737483160879737
- 1:53.10265863795928
- system:index:20180807T101021_20180807T101024_T32UQE
- system:time_start:1533636624457
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.356149883988882
- 1:52.2334721277929
- 0:12.356240239867686
- 1:52.23338986422996
- 0:12.358490301486079
- 1:52.233165606945796
- 0:12.35997291232916
- 1:52.23310800211887
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.66355095934353
- 1:52.747409299405106
- 0:13.648270830175928
- 1:53.23946946980255
- 0:13.647599450236987
- 1:53.24014423730665
- 0:13.637590565209987
- 1:53.241659962825096
- 0:13.633966746717753
- 1:53.24188969583323
- 0:12.786548971926518
- 1:53.22916246723074
- 0:12.773603444886103
- 1:53.2008053784702
- 0:12.606054967833456
- 1:52.82098778846051
- 0:12.379364618328538
- 1:52.2944481989255
- 0:12.360084986578372
- 1:52.24869241957407
- 0:12.355940984766375
- 1:52.236986002573964
- 0:12.356149883988882
- 1:52.2334721277929
- system:index:20180807T101021_20180807T101024_T33UUU
- system:time_start:1533636624457
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.751286495488277
- 1:53.140120970498096
- 0:12.752659690149729
- 1:53.14005535291197
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.635312203495733
- 1:53.64571315915087
- 0:13.619187201198816
- 1:54.137692993643356
- 0:13.618499765394366
- 1:54.13836844197347
- 0:13.611051152583551
- 1:54.13937125049742
- 0:13.606429226345705
- 1:54.13985865316518
- 0:13.599977913026397
- 1:54.14005414407571
- 0:13.195068467503912
- 1:54.134663514728494
- 0:13.192314914671286
- 1:54.13296169102109
- 0:13.15875945210828
- 1:54.060966982656
- 0:13.117032501299212
- 1:53.96997716732006
- 0:12.943788168201548
- 1:53.58578079318083
- 0:12.773575211716894
- 1:53.201343532286316
- 0:12.753952125202424
- 1:53.15565926448469
- 0:12.749173841635915
- 1:53.14395805151026
- 0:12.749345516836184
- 1:53.140674933255234
- 0:12.74987877609831
- 1:53.140373836546914
- 0:12.751286495488277
- 1:53.140120970498096
- system:index:20180807T101021_20180807T101024_T33UUV
- system:time_start:1533636624457
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.929542323450468
- 1:52.22627540130729
- 0:11.929580469281653
- 1:52.22627149925202
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.556074875859697
- 1:52.42110003244565
- 0:13.581609528760685
- 1:52.666511583365576
- 0:13.607516276521368
- 1:52.91190409151185
- 0:13.633804190317946
- 1:53.1572919512135
- 0:13.63331222929126
- 1:53.158417290560706
- 0:13.633285529063112
- 1:53.15844098169409
- 0:13.632449060715741
- 1:53.159013429028846
- 0:13.63240678505413
- 1:53.15903500002264
- 0:13.628844659580263
- 1:53.15972017706568
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.960614330786171
- 1:52.71941017785326
- 0:11.927708666887291
- 1:52.22676773255406
- 0:11.927754125027594
- 1:52.226733485295306
- 0:11.927772198121476
- 1:52.2266872399207
- 0:11.929542323450468
- 1:52.22627540130729
- system:index:20180810T102021_20180810T102023_T32UQD
- system:time_start:1533896423460
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.9896452011253
- 1:53.12372442917565
- 0:11.98969232603161
- 1:53.12371970838264
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651119865829472
- 1:53.31698147337989
- 0:13.678068770139987
- 1:53.56250194965098
- 0:13.70541805236422
- 1:53.808002686223396
- 0:13.733176580360688
- 1:54.05349236264576
- 0:13.73316845767755
- 1:54.05351744439363
- 0:13.732661631643102
- 1:54.054437161638724
- 0:13.732605282171239
- 1:54.054456749180375
- 0:13.732575452234085
- 1:54.054494769850024
- 0:13.723460598398628
- 1:54.05539618653011
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058830880593415
- 1:54.10924624101911
- 0:12.023083136387578
- 1:53.61674254390306
- 0:11.988379906020725
- 1:53.124202420143995
- 0:11.988420760325024
- 1:53.124172107054264
- 0:11.98842722185313
- 1:53.12412989359123
- 0:11.9896452011253
- 1:53.12372442917565
- system:index:20180810T102021_20180810T102023_T32UQE
- system:time_start:1533896423460
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663537232739284
- 1:52.74785863198954
- 0:13.64824296667014
- 1:53.24035413868409
- 0:13.647588793374608
- 1:53.24197444735494
- 0:13.647523441454425
- 1:53.242001909072854
- 0:13.647477174155377
- 1:53.24204097145684
- 0:13.647439819307769
- 1:53.24204330946181
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004609348085067
- 1:53.211994482054486
- 0:12.03849740278716
- 1:52.71938805678886
- 0:12.071412885521076
- 1:52.226745952202315
- 0:12.071456875271997
- 1:52.22671779289462
- 0:12.071467810071464
- 1:52.22667932136007
- 0:12.071499147078589
- 1:52.2266676052876
- 0:12.07271227490466
- 1:52.22633201212393
- 0:12.072758923892456
- 1:52.22632956636897
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- system:index:20180810T102021_20180810T102023_T33UUU
- system:time_start:1533896423460
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.010803121251215
- 1:53.12410414266407
- 0:12.01083811997407
- 1:53.1240961544332
- 0:12.012956099508799
- 1:53.123789052821145
- 0:12.01299378250713
- 1:53.123787119061234
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635300532305504
- 1:53.64607254728451
- 0:13.619163595759833
- 1:54.13840117173872
- 0:13.619146526352836
- 1:54.1384279701884
- 0:13.61851061646266
- 1:54.13913979259156
- 0:13.618479423387992
- 1:54.13916550326878
- 0:13.615666954926954
- 1:54.140220371712545
- 0:13.615608398428485
- 1:54.140234903548446
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940251452605162
- 1:54.10922292267334
- 0:11.976009873308227
- 1:53.616719634921594
- 0:12.01072354453829
- 1:53.12417989359036
- 0:12.010776266828987
- 1:53.12414694327017
- 0:12.010803121251215
- 1:53.12410414266407
- system:index:20180810T102021_20180810T102023_T33UUV
- system:time_start:1533896423460
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.556107263602584
- 1:52.42141369392922
- 0:13.581675258373929
- 1:52.66713890869132
- 0:13.60761640311881
- 1:52.91284492452808
- 0:13.633941920144505
- 1:53.15856891554009
- 0:13.633736780675306
- 1:53.15870943274411
- 0:13.629295401029797
- 1:53.15970262661494
- 0:12.773752712888957
- 1:53.18993052850071
- 0:12.771720338860929
- 1:53.18778065381043
- 0:12.770676580850916
- 1:53.186185326615245
- 0:12.76958896388632
- 1:53.184056088209424
- 0:12.747208020786404
- 1:53.13349225359412
- 0:12.554696426616085
- 1:52.69202660117853
- 0:12.543741337624901
- 1:52.66645076148944
- 0:12.357512750041492
- 1:52.2220731147782
- 0:12.356308143321991
- 1:52.21778100066503
- 0:12.356119969292806
- 1:52.215285827516176
- 0:12.358115155865562
- 1:52.21484565287645
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20180812T101019_20180812T101124_T32UQD
- system:time_start:1534068684399
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.739021244245281
- 1:53.111609986504334
- 0:12.738927161676408
- 1:53.11052675025495
- 0:12.738694354673013
- 1:53.10263185473377
- 0:12.739863388584746
- 1:53.10249353042716
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.651134434395978
- 1:53.31711587996908
- 0:13.678098515333522
- 1:53.56277068731834
- 0:13.705463330989971
- 1:53.80840585076389
- 0:13.73324108828881
- 1:54.054058264541375
- 0:13.733025877994606
- 1:54.05420310509928
- 0:13.728009556418675
- 1:54.05494651140174
- 0:13.722545843451893
- 1:54.05543221618218
- 0:13.175390593994623
- 1:54.075708392322966
- 0:13.174271074316174
- 1:54.074063896606724
- 0:13.153639883975877
- 1:54.037535690707756
- 0:13.151382081804758
- 1:54.03329455854294
- 0:13.147943107486242
- 1:54.026395456888054
- 0:12.94248791845403
- 1:53.573780280978056
- 0:12.741608053796046
- 1:53.12071228886168
- 0:12.739021244245281
- 1:53.111609986504334
- system:index:20180812T101019_20180812T101124_T32UQE
- system:time_start:1534068684399
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.363629044507912
- 1:52.233314100563526
- 0:12.364041134364298
- 1:52.233198919923936
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.663526191031458
- 1:52.74821812379438
- 0:13.648216992996641
- 1:53.24117794771522
- 0:13.64568867061608
- 1:53.241751640716586
- 0:13.64205618987728
- 1:53.24198213413731
- 0:12.79196368452537
- 1:53.22926290633405
- 0:12.789363817760803
- 1:53.22647065854863
- 0:12.787671908683793
- 1:53.22427262108512
- 0:12.78603913800197
- 1:53.220998460243166
- 0:12.782808661028177
- 1:53.21392411592671
- 0:12.742648756347185
- 1:53.12307831515188
- 0:12.587600279716057
- 1:52.768281037009125
- 0:12.547465387733736
- 1:52.675199196737175
- 0:12.513016213570697
- 1:52.59409039978507
- 0:12.364641230051545
- 1:52.23853883561088
- 0:12.363593384538817
- 1:52.233916380453
- 0:12.363629044507912
- 1:52.233314100563526
- system:index:20180812T101019_20180812T101124_T33UUU
- system:time_start:1534068684399
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635286108787739
- 1:53.646521870937306
- 0:13.619132855502608
- 1:54.13932369204633
- 0:13.617958103793432
- 1:54.13998705193891
- 0:13.614673846525543
- 1:54.1402241254251
- 0:13.20237996369376
- 1:54.13477291607078
- 0:13.20102813493623
- 1:54.13307876235798
- 0:13.165138148974364
- 1:54.061875334095376
- 0:13.156715527459543
- 1:54.0450256939758
- 0:13.15085459078385
- 1:54.032529491223485
- 0:12.987254398816031
- 1:53.67255562088807
- 0:12.826348980063656
- 1:53.31236692629503
- 0:12.78603823551935
- 1:53.220996553166195
- 0:12.769982745642027
- 1:53.18401318989659
- 0:12.768383871622026
- 1:53.18020587893245
- 0:12.759665836426874
- 1:53.1579200451181
- 0:12.755173087662415
- 1:53.14052246922954
- 0:12.755892140252744
- 1:53.14011636440569
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20180812T101019_20180812T101124_T33UUV
- system:time_start:1534068684399
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180815T102019_20180815T102017_T32UQD
- system:time_start:1534328417456
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180815T102019_20180815T102017_T32UQE
- system:time_start:1534328417456
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180815T102019_20180815T102017_T33UUU
- system:time_start:1534328417456
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180815T102019_20180815T102017_T33UUV
- system:time_start:1534328417456
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.765718795584071
- 1:53.19018504595999
- 0:12.765012799428337
- 1:53.18980353283094
- 0:12.763553708438069
- 1:53.18694606062259
- 0:12.761336585200889
- 1:53.18215758422654
- 0:12.75798914116418
- 1:53.174707445300825
- 0:12.60821434836725
- 1:52.83450097771064
- 0:12.460883169854664
- 1:52.49405209811466
- 0:12.430605613410526
- 1:52.42315936851839
- 0:12.369273510600024
- 1:52.278676436877866
- 0:12.345697009023075
- 1:52.222682275311115
- 0:12.343537598689458
- 1:52.2173450046361
- 0:12.342862681182659
- 1:52.2154122330902
- 0:12.343501632728614
- 1:52.21526100856948
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.765718795584071
- 1:53.19018504595999
- system:index:20180817T101021_20180817T101024_T32UQD
- system:time_start:1534500624461
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.726677713522262
- 1:53.103345434385616
- 0:12.726662727606389
- 1:53.103308775675984
- 0:12.727250588970701
- 1:53.102916072311814
- 0:12.727325344333467
- 1:53.10288728081694
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.162239628994309
- 1:54.07616481278918
- 0:13.162180230250604
- 1:54.07613757744512
- 0:13.162100966631757
- 1:54.0761273519786
- 0:13.161008588796179
- 1:54.074521633756866
- 0:13.05102002396091
- 1:53.833255206688264
- 0:12.942359434066443
- 1:53.59186409993876
- 0:12.728906523711451
- 1:53.10870230697444
- 0:12.726651661736117
- 1:53.103375950441865
- 0:12.726677713522262
- 1:53.103345434385616
- system:index:20180817T101021_20180817T101024_T32UQE
- system:time_start:1534500624461
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.350477371908745
- 1:52.2333345367807
- 0:12.350467536689866
- 1:52.23329549460493
- 0:12.351098414011165
- 1:52.232935510828895
- 0:12.35117557255649
- 1:52.232910786763725
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.782169318157482
- 1:53.22908096376881
- 0:12.782115486091206
- 1:53.229050721050825
- 0:12.782039657883615
- 1:53.22903632468199
- 0:12.781214725394689
- 1:53.22738197479525
- 0:12.519794780006254
- 1:52.63092136069159
- 0:12.461166442804704
- 1:52.49479283836763
- 0:12.418792385525633
- 1:52.39567604019487
- 0:12.365048975952188
- 1:52.26876927640584
- 0:12.35119828020053
- 1:52.23554298547825
- 0:12.350448355457155
- 1:52.23336600958405
- 0:12.350477371908745
- 1:52.2333345367807
- system:index:20180817T101021_20180817T101024_T33UUU
- system:time_start:1534500624461
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.188651874751306
- 1:54.13453782531795
- 0:13.188574328593898
- 1:54.134523680726595
- 0:13.186022036086943
- 1:54.129610410570656
- 0:13.175955853623398
- 1:54.10788289880903
- 0:12.962221430228947
- 1:53.635991772967195
- 0:12.753081884809855
- 1:53.163735605103184
- 0:12.749077624961961
- 1:53.15448881840211
- 0:12.743479021035636
- 1:53.141432946086695
- 0:12.74347545140442
- 1:53.141410216787044
- 0:12.743546097874644
- 1:53.1400629573672
- 0:12.743590647472907
- 1:53.14003450467493
- 0:12.743602204682283
- 1:53.13999260886355
- 0:12.743968704643127
- 1:53.13989098806998
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.188707134450901
- 1:54.134567909956466
- 0:13.188651874751306
- 1:54.13453782531795
- system:index:20180817T101021_20180817T101024_T33UUV
- system:time_start:1534500624461
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180820T102021_20180820T102358_T32UQD
- system:time_start:1534760638925
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180820T102021_20180820T102358_T32UQE
- system:time_start:1534760638925
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180820T102021_20180820T102358_T33UUU
- system:time_start:1534760638925
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180820T102021_20180820T102358_T33UUV
- system:time_start:1534760638925
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.358675589785577
- 1:52.214833262648646
- 0:12.358721668892228
- 1:52.21482837373034
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77966978583165
- 1:53.18974269156772
- 0:12.779608417626953
- 1:53.189713540139785
- 0:12.77952818432134
- 1:53.18969871832877
- 0:12.77897461616567
- 1:53.18861544567648
- 0:12.752107875713904
- 1:53.127940980999085
- 0:12.553099479666082
- 1:52.67237669816731
- 0:12.35839867165177
- 1:52.216376121921165
- 0:12.358296355509786
- 1:52.215020466669934
- 0:12.358336183388086
- 1:52.214990073132746
- 0:12.358342123205341
- 1:52.21494780456835
- 0:12.358675589785577
- 1:52.214833262648646
- system:index:20180822T101019_20180822T101321_T32UQD
- system:time_start:1534932801460
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.177235367578788
- 1:54.07564420831529
- 0:13.176666926567252
- 1:54.07506404925626
- 0:13.168478812329305
- 1:54.057526604596696
- 0:13.163798278869743
- 1:54.047434255232105
- 0:13.132174632545645
- 1:53.97836452538223
- 0:12.9401323813537
- 1:53.553349696097946
- 0:12.752107613747661
- 1:53.1279404253742
- 0:12.7419443540282
- 1:53.10396617281585
- 0:12.741821821531676
- 1:53.102556334118496
- 0:12.742223339805777
- 1:53.10241923832264
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20180822T101019_20180822T101321_T32UQE
- system:time_start:1534932801460
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.797437748606528
- 1:53.22936423863998
- 0:12.797320126314577
- 1:53.22933050381703
- 0:12.796458627756703
- 1:53.22821172169778
- 0:12.79482507985737
- 1:53.22493766774779
- 0:12.791592810083532
- 1:53.21786352053324
- 0:12.786761001334158
- 1:53.20698433692949
- 0:12.58563878652214
- 1:52.74746978703607
- 0:12.388565546275519
- 1:52.28763771866781
- 0:12.366964647693088
- 1:52.23643563400757
- 0:12.366210202671494
- 1:52.23424784687923
- 0:12.366262044611053
- 1:52.23337294929628
- 0:12.366674030030174
- 1:52.23325776962589
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.797437748606528
- 1:53.22936423863998
- system:index:20180822T101019_20180822T101321_T33UUU
- system:time_start:1534932801460
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.757895550058455
- 1:53.14055805251337
- 0:12.75791938087351
- 1:53.14054069106081
- 0:12.758535596520087
- 1:53.14019264467291
- 0:12.758614161798507
- 1:53.14016766561051
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20431069959926
- 1:54.1348017543702
- 0:13.204255298110878
- 1:54.13477169141159
- 0:13.204177730669723
- 1:54.13475755871736
- 0:13.200775947019654
- 1:54.12821386347259
- 0:13.19321961179813
- 1:54.11191884109666
- 0:12.987870901663245
- 1:53.65962022423294
- 0:12.78676100204599
- 1:53.20698408623769
- 0:12.758660291378117
- 1:53.14279973781122
- 0:12.757875581478421
- 1:53.140625234870555
- 0:12.757904970790564
- 1:53.1405936660063
- 0:12.757895550058455
- 1:53.14055805251337
- system:index:20180822T101019_20180822T101321_T33UUV
- system:time_start:1534932801460
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180825T102019_20180825T102015_T32UQD
- system:time_start:1535192415457
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180825T102019_20180825T102015_T32UQE
- system:time_start:1535192415457
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180825T102019_20180825T102015_T33UUU
- system:time_start:1535192415457
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180825T102019_20180825T102015_T33UUV
- system:time_start:1535192415457
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.762975637641551
- 1:53.19027186084791
- 0:12.761855969565161
- 1:53.18807905342356
- 0:12.759638962882121
- 1:53.183290472883364
- 0:12.584533069390298
- 1:52.785030186649465
- 0:12.439707809448688
- 1:52.44933840530313
- 0:12.410585543907345
- 1:52.38110568618934
- 0:12.380473437244433
- 1:52.310196353601285
- 0:12.357945576159572
- 1:52.256873110222934
- 0:12.348302364696456
- 1:52.23394148584697
- 0:12.34076732143669
- 1:52.21575906134992
- 0:12.341419002855602
- 1:52.215320061274284
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20180827T101021_20180827T101023_T32UQD
- system:time_start:1535364623459
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.724875795184769
- 1:53.10311485782878
- 0:12.724881443368147
- 1:53.103072542353985
- 0:12.725232209386201
- 1:53.10295294001699
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.159953110751868
- 1:54.07624408111573
- 0:13.159900674993715
- 1:54.076219962256545
- 0:13.159828435502204
- 1:54.07621673701182
- 0:13.159290576199291
- 1:54.07566746139049
- 0:13.156971465490416
- 1:54.07087889936093
- 0:12.941228553940295
- 1:53.59433001099734
- 0:12.730547224948829
- 1:53.117285651020886
- 0:12.724905985175809
- 1:53.103961582197314
- 0:12.72483535168189
- 1:53.10314534890864
- 0:12.724875795184769
- 1:53.10311485782878
- system:index:20180827T101021_20180827T101023_T32UQE
- system:time_start:1535364623459
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780264659775597
- 1:53.22904556725041
- 0:12.7794186625668
- 1:53.22734871538393
- 0:12.770547139413987
- 1:53.2077612485083
- 0:12.764908489467475
- 1:53.19524772763032
- 0:12.645826541953515
- 1:52.92536776300045
- 0:12.58327004216191
- 1:52.78222038489114
- 0:12.493709243377037
- 1:52.57533926137276
- 0:12.440683842137542
- 1:52.45172666641363
- 0:12.408854930307939
- 1:52.37711338733228
- 0:12.381767035145787
- 1:52.31338650364723
- 0:12.355535657508222
- 1:52.251290074872884
- 0:12.349378652134831
- 1:52.23658130817327
- 0:12.348250524864872
- 1:52.2333058712354
- 0:12.348271199277061
- 1:52.232960616274546
- 0:12.34883983442784
- 1:52.232858286124554
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- system:index:20180827T101021_20180827T101023_T33UUU
- system:time_start:1535364623459
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.18629783064216
- 1:54.134500544939414
- 0:13.186277425245404
- 1:54.134481481578064
- 0:13.185836396602749
- 1:54.133928555773615
- 0:13.17576647750204
- 1:54.112194807062096
- 0:12.965705745374983
- 1:53.648457461770725
- 0:12.760085937851661
- 1:53.18436740607966
- 0:12.740848010673597
- 1:53.14030696939146
- 0:12.740876286658795
- 1:53.14027327391193
- 0:12.740865472872924
- 1:53.140232637934844
- 0:12.74150668569911
- 1:53.139870718618795
- 0:12.741585246767121
- 1:53.13984575256457
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.186412618616195
- 1:54.134533320489304
- 0:13.186363676996185
- 1:54.13450676494258
- 0:13.18629783064216
- 1:54.134500544939414
- system:index:20180827T101021_20180827T101023_T33UUV
- system:time_start:1535364623459
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180830T102021_20180830T102524_T32UQD
- system:time_start:1535624724509
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180830T102021_20180830T102524_T32UQE
- system:time_start:1535624724509
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180830T102021_20180830T102524_T33UUU
- system:time_start:1535624724509
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180830T102021_20180830T102524_T33UUV
- system:time_start:1535624724509
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.357459497272918
- 1:52.21501502854421
- 0:12.357465438134723
- 1:52.21497275999127
- 0:12.3578102389839
- 1:52.21485430281744
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.773845542288115
- 1:53.18992761511224
- 0:12.773758578613169
- 1:53.18991619396903
- 0:12.772793582554208
- 1:53.18939477304055
- 0:12.772755843661065
- 1:53.18936638970763
- 0:12.56542330157368
- 1:52.714640172797374
- 0:12.362783400922627
- 1:52.23946550014478
- 0:12.361700416469239
- 1:52.2367924737289
- 0:12.357562236898483
- 1:52.21693383724227
- 0:12.35741966900896
- 1:52.21504542176433
- 0:12.357459497272918
- 1:52.21501502854421
- system:index:20180901T101019_20180901T101015_T32UQD
- system:time_start:1535796615459
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.740423276182954
- 1:53.102479459865556
- 0:12.740470243842974
- 1:53.10247444450009
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.17138550046946
- 1:54.07584756508845
- 0:13.171320651538117
- 1:54.07581781001617
- 0:13.171237318306856
- 1:54.07580085294203
- 0:12.956001648749266
- 1:53.601937197928734
- 0:12.745795328652546
- 1:53.12759516634152
- 0:12.740202079827059
- 1:53.10455594209625
- 0:12.740038172363446
- 1:53.102668065342
- 0:12.74007845833481
- 1:53.10263750166093
- 0:12.740084201199057
- 1:53.102595173780536
- 0:12.740423276182954
- 1:53.102479459865556
- system:index:20180901T101019_20180901T101015_T32UQE
- system:time_start:1535796615459
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.364989717299899
- 1:52.23337111050401
- 0:12.365015696427545
- 1:52.23332176421129
- 0:12.365514705539857
- 1:52.23323184155445
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.795641476845292
- 1:53.22933107145998
- 0:12.795556398436265
- 1:53.22931535075714
- 0:12.794643326799054
- 1:53.228732559517915
- 0:12.772452300328336
- 1:53.1883783518021
- 0:12.762806279996196
- 1:53.166616391506786
- 0:12.695584133031513
- 1:53.013740644761384
- 0:12.622492993806684
- 1:52.846135443843075
- 0:12.398719594651952
- 1:52.32455263033245
- 0:12.367825858284446
- 1:52.251561004026435
- 0:12.367105549988407
- 1:52.248839608843866
- 0:12.364942672739257
- 1:52.233410016462635
- 0:12.364989717299899
- 1:52.23337111050401
- system:index:20180901T101019_20180901T101015_T33UUU
- system:time_start:1535796615459
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.756102986416856
- 1:53.140524252080475
- 0:12.756126817623247
- 1:53.140506891036196
- 0:12.756743037970889
- 1:53.14015885527888
- 0:12.756821602807012
- 1:53.14013387758587
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.197885700448566
- 1:54.13470568721752
- 0:13.197828935864251
- 1:54.13467484235237
- 0:13.197750348445485
- 1:54.134658872148044
- 0:13.016487344088315
- 1:53.736692507261964
- 0:12.838540123456083
- 1:53.33848186628774
- 0:12.772450799711232
- 1:53.18837492389389
- 0:12.76686884213099
- 1:53.174780737255894
- 0:12.756082268433037
- 1:53.14058909499956
- 0:12.756112182128572
- 1:53.14055888851506
- 0:12.756102986416856
- 1:53.140524252080475
- system:index:20180901T101019_20180901T101015_T33UUV
- system:time_start:1535796615459
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180904T102019_20180904T102014_T32UQD
- system:time_start:1536056414457
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180904T102019_20180904T102014_T32UQE
- system:time_start:1536056414457
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180904T102019_20180904T102014_T33UUU
- system:time_start:1536056414457
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180904T102019_20180904T102014_T33UUV
- system:time_start:1536056414457
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.761179245781777
- 1:53.19032866084817
- 0:12.71654772002472
- 1:53.090201437019566
- 0:12.573211120323576
- 1:52.763650505672416
- 0:12.432113614269248
- 1:52.436877208885676
- 0:12.372420833499424
- 1:52.296935144390204
- 0:12.355792458009782
- 1:52.257473934247415
- 0:12.346129665025327
- 1:52.23427240987548
- 0:12.339609535024037
- 1:52.21771861657576
- 0:12.339444335310695
- 1:52.21551871709366
- 0:12.339665530842824
- 1:52.21536971780287
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20180906T101021_20180906T101022_T32UQD
- system:time_start:1536228622456
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.15852114958056
- 1:54.07626399910491
- 0:13.158441182780754
- 1:54.07625283431136
- 0:13.151917024977458
- 1:54.0662001978496
- 0:12.936984047999644
- 1:53.590152351716625
- 0:12.727086199496867
- 1:53.11360770620604
- 0:12.726176766060224
- 1:53.103103327314074
- 0:12.726195639690566
- 1:53.10305148714247
- 0:12.72635632985471
- 1:53.102944150816064
- 0:12.726431085244831
- 1:53.10291535994919
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.158581207954619
- 1:54.07629158574562
- 0:13.15852114958056
- 1:54.07626399910491
- system:index:20180906T101021_20180906T101022_T32UQE
- system:time_start:1536228622456
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.347828465552668
- 1:52.23301552413117
- 0:12.347884072760488
- 1:52.23294542982361
- 0:12.348243839592369
- 1:52.2328449092898
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780741576636983
- 1:53.229054441868
- 0:12.778121816167461
- 1:53.2265298317961
- 0:12.77273840305472
- 1:53.21751581951534
- 0:12.589367145713283
- 1:52.80068789445681
- 0:12.409356746247047
- 1:52.38359920370254
- 0:12.359092925970675
- 1:52.26539875906901
- 0:12.352167876305609
- 1:52.248785578624556
- 0:12.347590691937077
- 1:52.23707948391436
- 0:12.347587404623306
- 1:52.23705694914138
- 0:12.347828465552668
- 1:52.23301552413117
- system:index:20180906T101021_20180906T101022_T33UUU
- system:time_start:1536228622456
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.183529544749808
- 1:54.134446476214656
- 0:13.18351483551829
- 1:54.13442567849583
- 0:13.16295982395037
- 1:54.090425970825706
- 0:12.965873801674192
- 1:53.65439374982268
- 0:12.772708651777435
- 1:53.21805074919323
- 0:12.740648620874822
- 1:53.14407662235933
- 0:12.740645053188146
- 1:53.144053892082844
- 0:12.740843209711215
- 1:53.14028136987588
- 0:12.740869140201696
- 1:53.14023057091006
- 0:12.74150668569911
- 1:53.139870718618795
- 0:12.741585246767121
- 1:53.13984575256457
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.18365906064585
- 1:54.13449183823382
- 0:13.18360247583878
- 1:54.13446105251552
- 0:13.183529544749808
- 1:54.134446476214656
- system:index:20180906T101021_20180906T101022_T33UUV
- system:time_start:1536228622456
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180909T102021_20180909T102205_T32UQD
- system:time_start:1536488525087
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180909T102021_20180909T102205_T32UQE
- system:time_start:1536488525087
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180909T102021_20180909T102205_T33UUU
- system:time_start:1536488525087
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180909T102021_20180909T102205_T33UUV
- system:time_start:1536488525087
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77106451305403
- 1:53.19001573456728
- 0:12.7630901160271
- 1:53.18157774381364
- 0:12.762046781727616
- 1:53.17998239787012
- 0:12.760959768327686
- 1:53.17785300881699
- 0:12.620853265260688
- 1:52.857860958056875
- 0:12.58444645858871
- 1:52.773159705641106
- 0:12.468101210473773
- 1:52.49869711375863
- 0:12.353271969447457
- 1:52.22408590817866
- 0:12.350029249397245
- 1:52.21607409474962
- 0:12.34996485007926
- 1:52.2152202681736
- 0:12.350186135836818
- 1:52.21507123589608
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20180911T101019_20180911T101438_T32UQD
- system:time_start:1536660878831
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.169492791709672
- 1:54.07591326318409
- 0:13.167965385336485
- 1:54.07511519892306
- 0:13.157726201443356
- 1:54.060063382442216
- 0:13.154228384195356
- 1:54.0526233551228
- 0:13.127331783351769
- 1:53.994182848672565
- 0:12.942284880994126
- 1:53.586199850097195
- 0:12.760959056834968
- 1:53.17785124913987
- 0:12.75534962822782
- 1:53.16507438403506
- 0:12.73589312391798
- 1:53.111716720727856
- 0:12.734058806024484
- 1:53.10610047398752
- 0:12.73377339104298
- 1:53.102809400294376
- 0:12.734175019481304
- 1:53.10267232274587
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20180911T101019_20180911T101438_T32UQE
- system:time_start:1536660878831
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35811941611142
- 1:52.23309292422743
- 0:12.358196576669535
- 1:52.23306819483536
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.788456247501115
- 1:53.2291978959799
- 0:12.788331361683907
- 1:53.22915784072641
- 0:12.7866613785732
- 1:53.22640890852642
- 0:12.762106533942976
- 1:53.18009330887295
- 0:12.761292543766675
- 1:53.178457460077674
- 0:12.621756249498608
- 1:52.859608270711256
- 0:12.582269159853803
- 1:52.768172286903436
- 0:12.360142070566154
- 1:52.240330295019845
- 0:12.357872462851976
- 1:52.23406183302443
- 0:12.35792341116039
- 1:52.233204833682684
- 0:12.35811941611142
- 1:52.23309292422743
- system:index:20180911T101019_20180911T101438_T33UUU
- system:time_start:1536660878831
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.749422186008577
- 1:53.14014101323308
- 0:12.749446048181074
- 1:53.14009569353049
- 0:12.749954858153302
- 1:53.14000430165371
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.195591038016063
- 1:54.13467129007464
- 0:13.195536670250506
- 1:54.134641786005425
- 0:13.19545990379434
- 1:54.13462874403416
- 0:13.19331808603627
- 1:54.130801137150925
- 0:13.164543673730744
- 1:54.07534975567892
- 0:13.152812579431398
- 1:54.05035841503546
- 0:12.953446227325383
- 1:53.611029198085696
- 0:12.758068271335368
- 1:53.17138041085191
- 0:12.756498081644558
- 1:53.16703132640459
- 0:12.74928680318902
- 1:53.14179910620878
- 0:12.749371776598187
- 1:53.14017319274519
- 0:12.749422186008577
- 1:53.14014101323308
- system:index:20180911T101019_20180911T101438_T33UUV
- system:time_start:1536660878831
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180914T102019_20180914T102014_T32UQD
- system:time_start:1536920414459
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180914T102019_20180914T102014_T32UQE
- system:time_start:1536920414459
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180914T102019_20180914T102014_T33UUU
- system:time_start:1536920414459
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180914T102019_20180914T102014_T33UUV
- system:time_start:1536920414459
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.756372312190388
- 1:53.19048050813975
- 0:12.756229573895688
- 1:53.19043521248236
- 0:12.752377675659046
- 1:53.182440753467674
- 0:12.55227106237419
- 1:52.72501927228425
- 0:12.356525140432298
- 1:52.267167194768476
- 0:12.346879899853363
- 1:52.24423512141342
- 0:12.340381274720809
- 1:52.22795879509189
- 0:12.336560944841585
- 1:52.21807458162371
- 0:12.336395948231349
- 1:52.215874908340275
- 0:12.337035421082787
- 1:52.21544422419742
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.756372312190388
- 1:53.19048050813975
- system:index:20180916T101021_20180916T101512_T32UQD
- system:time_start:1537092912688
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.718307614490854
- 1:53.103196169666795
- 0:12.718382370123892
- 1:53.1031673844525
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.15583745623104
- 1:54.07638654036605
- 0:13.15571267293419
- 1:54.076359204132324
- 0:13.15261900816346
- 1:54.07319924752885
- 0:13.134477799765937
- 1:54.03387535994336
- 0:13.012449672945822
- 1:53.76628224719347
- 0:12.892047109148754
- 1:53.498529580476394
- 0:12.717751538714165
- 1:53.1041858959376
- 0:12.717700964626571
- 1:53.10360128173502
- 0:12.718307614490854
- 1:53.103196169666795
- system:index:20180916T101021_20180916T101512_T32UQE
- system:time_start:1537092912688
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.772276999201381
- 1:53.22725631601746
- 0:12.772240051873698
- 1:53.227228413066676
- 0:12.740083908753592
- 1:53.15485848988531
- 0:12.553615245832852
- 1:52.72793008490747
- 0:12.370632400496774
- 1:52.30072886983141
- 0:12.358676203550162
- 1:52.272403501281964
- 0:12.342972687016312
- 1:52.23346840817626
- 0:12.342969367613785
- 1:52.23344579583551
- 0:12.343001593807973
- 1:52.2329068864062
- 0:12.343027578386666
- 1:52.23285623053302
- 0:12.343199924671401
- 1:52.23275788641074
- 0:12.343277045446708
- 1:52.23273308979169
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.775433189279987
- 1:53.22895538431762
- 0:12.775357286988081
- 1:53.22894333167244
- 0:12.772276999201381
- 1:53.22725631601746
- system:index:20180916T101021_20180916T101512_T33UUU
- system:time_start:1537092912688
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.73612914211683
- 1:53.13976856722634
- 0:12.736207701851079
- 1:53.13974360527968
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.182741281344269
- 1:54.134478016795384
- 0:13.182625111050344
- 1:54.1344476774713
- 0:13.17822529714983
- 1:54.12950090401199
- 0:13.17023879722161
- 1:54.112650556810365
- 0:12.979453557573908
- 1:53.693191245778024
- 0:12.792327725054568
- 1:53.27344071968432
- 0:12.772205086814642
- 1:53.22775169548873
- 0:12.752544276066711
- 1:53.18260670479811
- 0:12.735728688467686
- 1:53.14370365790551
- 0:12.735929855879583
- 1:53.139881063293295
- 0:12.73612914211683
- 1:53.13976856722634
- system:index:20180916T101021_20180916T101512_T33UUV
- system:time_start:1537092912688
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180919T102021_20180919T102018_T32UQD
- system:time_start:1537352418000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180919T102021_20180919T102018_T32UQE
- system:time_start:1537352418000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180919T102021_20180919T102018_T33UUU
- system:time_start:1537352418000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180919T102021_20180919T102018_T33UUV
- system:time_start:1537352418000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.783639659910039
- 1:53.18961650866371
- 0:12.781680205088566
- 1:53.18855797134059
- 0:12.77958778732931
- 1:53.18536134347235
- 0:12.610310467039653
- 1:52.80070768284669
- 0:12.444151450449342
- 1:52.41574951898685
- 0:12.401051716999017
- 1:52.31446199461378
- 0:12.374209120333356
- 1:52.25101221345909
- 0:12.363478262042994
- 1:52.2254142530318
- 0:12.360233507952398
- 1:52.217402652449785
- 0:12.360067282499982
- 1:52.21520262355948
- 0:12.360706409200855
- 1:52.214771823797705
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20180921T101019_20180921T101017_T32UQD
- system:time_start:1537524617000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.744501605640378
- 1:53.10243759522567
- 0:12.744609501262776
- 1:53.10234413680809
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.1804489913392
- 1:54.07553241845048
- 0:13.178390893500891
- 1:54.073930624413066
- 0:13.176067232057285
- 1:54.06913740027859
- 0:13.170253271514419
- 1:54.056925397181246
- 0:13.158528709641777
- 1:54.03142533449471
- 0:12.952757991051184
- 1:53.576948799814794
- 0:12.75159133569339
- 1:53.12202025031066
- 0:12.745945590730454
- 1:53.10870353044474
- 0:12.744720697741444
- 1:53.10495559043426
- 0:12.744501605640378
- 1:53.10243759522567
- system:index:20180921T101019_20180921T101017_T32UQE
- system:time_start:1537524617000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.800132273537326
- 1:53.22941400928025
- 0:12.800002559832352
- 1:53.22936939344993
- 0:12.795916817761078
- 1:53.22118147689642
- 0:12.78785317598421
- 1:53.203228534432505
- 0:12.743665218268196
- 1:53.10367672848934
- 0:12.570878996387846
- 1:52.70913225428953
- 0:12.401078866167882
- 1:52.31435287123872
- 0:12.37403723097438
- 1:52.250624060617355
- 0:12.370188916745684
- 1:52.241364534389966
- 0:12.36790161512078
- 1:52.23536566163697
- 0:12.368017321723944
- 1:52.233412155130594
- 0:12.368429275130294
- 1:52.23329688980264
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.800132273537326
- 1:53.22941400928025
- system:index:20180921T101019_20180921T101017_T33UUU
- system:time_start:1537524617000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.761515999709212
- 1:53.140372947699525
- 0:12.7615275370384
- 1:53.140331050151644
- 0:12.761894065639474
- 1:53.140229365369834
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.207064149388168
- 1:54.13484277343027
- 0:13.206977031505916
- 1:54.134827336071275
- 0:13.206037197331295
- 1:54.13424663902435
- 0:13.202634657134162
- 1:54.12770233404511
- 0:13.190043405551402
- 1:54.100544784547125
- 0:12.980696514153095
- 1:53.63873227059683
- 0:12.775756683743502
- 1:53.17656907027496
- 0:12.763730568062671
- 1:53.14883009168112
- 0:12.761348785904147
- 1:53.14284913201302
- 0:12.761345315637975
- 1:53.1428266413278
- 0:12.761471455277933
- 1:53.140401408052774
- 0:12.761515999709212
- 1:53.140372947699525
- system:index:20180921T101019_20180921T101017_T33UUV
- system:time_start:1537524617000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.534709626078016
- 1:52.21955582175958
- 0:13.53479133532182
- 1:52.21957882212126
- 0:13.535729549888392
- 1:52.22298688056302
- 0:13.55980024907971
- 1:52.457126572536396
- 0:13.584203490002716
- 1:52.69124438101281
- 0:13.608946308652198
- 1:52.925344836256656
- 0:13.634034600698282
- 1:53.15942775214035
- 0:13.63392855064743
- 1:53.15952209643017
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.970936924208033
- 1:52.871043391126435
- 0:11.947853722220355
- 1:52.530063237849646
- 0:11.947900249395179
- 1:52.53002842505752
- 0:11.947920344511417
- 1:52.52998169614185
- 0:11.998521033664371
- 1:52.51899057361001
- 0:12.167525558288647
- 1:52.48274551898697
- 0:13.459562385627573
- 1:52.233730164622045
- 0:13.53374964476479
- 1:52.21955849915136
- 0:13.534642845231504
- 1:52.21952414724437
- 0:13.534709626078016
- 1:52.21955582175958
- system:index:20180924T102019_20180924T102016_T32UQD
- system:time_start:1537784416000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180924T102019_20180924T102016_T32UQE
- system:time_start:1537784416000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.052633155583642
- 1:52.50957084317295
- 0:12.05265955500588
- 1:52.50952014387541
- 0:12.05453931299734
- 1:52.508463295232694
- 0:12.131800190481986
- 1:52.490389807430226
- 0:12.959472801431842
- 1:52.33006807681872
- 0:13.105059293706738
- 1:52.30282074456112
- 0:13.289437129575258
- 1:52.26841047729834
- 0:13.38149492715682
- 1:52.251904650522526
- 0:13.381531603211075
- 1:52.251901582812856
- 0:13.3988259466283
- 1:52.25177774902311
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004609348085067
- 1:53.211994482054486
- 0:12.028871540353471
- 1:52.86078671342728
- 0:12.052633155583642
- 1:52.50957084317295
- system:index:20180924T102019_20180924T102016_T33UUU
- system:time_start:1537784416000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180924T102019_20180924T102016_T33UUV
- system:time_start:1537784416000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77373014812652
- 1:53.18993122870925
- 0:12.769400694419685
- 1:53.18190470716354
- 0:12.758368021629163
- 1:53.158505746630304
- 0:12.720471040818385
- 1:53.073348752508565
- 0:12.563672346251842
- 1:52.714962765340424
- 0:12.492757770939617
- 1:52.550319278358494
- 0:12.379299654442374
- 1:52.28324638406813
- 0:12.353463162652433
- 1:52.220833656434195
- 0:12.353029402116249
- 1:52.215080468805354
- 0:12.353136062108002
- 1:52.214987363124145
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20180926T101021_20180926T101020_T32UQD
- system:time_start:1537956620000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.73529913691355
- 1:53.10266344716866
- 0:12.735373778948235
- 1:53.10263466229215
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.173214567558096
- 1:54.07578400712719
- 0:13.173089863770587
- 1:54.07575667950019
- 0:13.169995325597789
- 1:54.07259757840975
- 0:13.154927803101259
- 1:54.04126540769618
- 0:12.945877118903297
- 1:53.580954187910606
- 0:12.741562771971076
- 1:53.12017733104937
- 0:12.734743313331887
- 1:53.103652679826965
- 0:12.734692616334149
- 1:53.10306873219799
- 0:12.73529913691355
- 1:53.10266344716866
- system:index:20180926T101021_20180926T101020_T32UQE
- system:time_start:1537956620000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.789316245292918
- 1:53.227558793161364
- 0:12.789297325343949
- 1:53.22753143876806
- 0:12.773966609317876
- 1:53.19379912599929
- 0:12.601726538613827
- 1:52.802556974044684
- 0:12.543425691519278
- 1:52.668101784660145
- 0:12.360660331898858
- 1:52.238991626389165
- 0:12.360657038340257
- 1:52.23896884431565
- 0:12.36097690838751
- 1:52.233580215367
- 0:12.36100272701884
- 1:52.23352948805214
- 0:12.361629899626505
- 1:52.23317147618589
- 0:12.361707061189732
- 1:52.2331467441303
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792048871934362
- 1:53.229264495186534
- 0:12.791963685502253
- 1:53.22924878381713
- 0:12.789316245292918
- 1:53.227558793161364
- system:index:20180926T101021_20180926T101020_T33UUU
- system:time_start:1537956620000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.197828935864251
- 1:54.13467484235237
- 0:13.197750348445485
- 1:54.134658872148044
- 0:12.98109128259355
- 1:53.6589667428694
- 0:12.769141719164079
- 1:53.18291882339234
- 0:12.761936974147824
- 1:53.16605950730842
- 0:12.7547643628316
- 1:53.14865707842969
- 0:12.75327795708895
- 1:53.14268273634676
- 0:12.753390928125706
- 1:53.14051887652367
- 0:12.75341695686647
- 1:53.140468062309814
- 0:12.754054241974401
- 1:53.14010815763301
- 0:12.754132806146757
- 1:53.140083181993994
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.197885700448566
- 1:54.13470568721752
- 0:13.197828935864251
- 1:54.13467484235237
- system:index:20180926T101021_20180926T101020_T33UUV
- system:time_start:1537956620000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20180929T102021_20180929T102019_T32UQD
- system:time_start:1538216419456
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20180929T102021_20180929T102019_T32UQE
- system:time_start:1538216419456
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20180929T102021_20180929T102019_T33UUU
- system:time_start:1538216419456
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20180929T102021_20180929T102019_T33UUV
- system:time_start:1538216419456
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.644198762492348
- 1:52.89109019759277
- 0:12.644229544021085
- 1:52.89104114530939
- 0:12.65616495034247
- 1:52.88932092219602
- 0:13.586955779447376
- 1:52.758439171561214
- 0:13.591104332773355
- 1:52.75827836359835
- 0:13.591260134911606
- 1:52.75834200259765
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.775637592103482
- 1:53.18987075604691
- 0:12.775579777503447
- 1:53.18984330411719
- 0:12.77550225756724
- 1:53.18983269438921
- 0:12.774449715743838
- 1:53.18822442696253
- 0:12.772277088991306
- 1:53.18397139074503
- 0:12.770059163824893
- 1:53.179183185776566
- 0:12.758933659778775
- 1:53.15470954682404
- 0:12.664264716228104
- 1:52.9390980079719
- 0:12.647637125827654
- 1:52.90075334899494
- 0:12.644284579261186
- 1:52.89275225133509
- 0:12.644148114389605
- 1:52.89112850680219
- 0:12.644198762492348
- 1:52.89109019759277
- system:index:20181001T101019_20181001T101019_T32UQD
- system:time_start:1538388619000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.17215365491172
- 1:54.07524260799028
- 0:13.17209789149752
- 1:54.075231298738586
- 0:13.142789376425668
- 1:54.01146062855421
- 0:12.937370278070302
- 1:53.557758373877434
- 0:12.736531892134586
- 1:53.103597050189116
- 0:12.736484443876078
- 1:53.103049615124256
- 0:12.736503303790487
- 1:53.10299777343473
- 0:12.737087638242237
- 1:53.1026072296976
- 0:12.737162393301833
- 1:53.102578431294155
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.174092927361313
- 1:54.075753491104486
- 0:13.172176412755006
- 1:54.07527078312168
- 0:13.17215365491172
- 1:54.07524260799028
- system:index:20181001T101019_20181001T101019_T32UQE
- system:time_start:1538388619000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.792905127800832
- 1:53.22925759146839
- 0:12.792841928259175
- 1:53.229256032585226
- 0:12.791099187415806
- 1:53.227577287503905
- 0:12.783031223642233
- 1:53.2096123194087
- 0:12.678987721495552
- 1:52.97295606528714
- 0:12.644846787986536
- 1:52.894054357538046
- 0:12.644843338127592
- 1:52.89403153148329
- 0:12.644989474835304
- 1:52.8913369275318
- 0:12.645015442034202
- 1:52.89128614955848
- 0:12.64567665342068
- 1:52.89091170744132
- 0:12.650966494180098
- 1:52.89002008563092
- 0:12.676581220646666
- 1:52.886477312623626
- 0:13.65609842719403
- 1:52.74786612823351
- 0:13.66190992686676
- 1:52.74739066543353
- 0:13.663402414355152
- 1:52.74740747846881
- 0:13.663548864793515
- 1:52.747478770912714
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792946960017524
- 1:53.22928111453111
- 0:12.792905127800832
- 1:53.22925759146839
- system:index:20181001T101019_20181001T101019_T33UUU
- system:time_start:1538388619000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.199676378939497
- 1:54.1341835717925
- 0:13.199614639774142
- 1:54.134151419398954
- 0:13.197883563966231
- 1:54.13140920735817
- 0:13.185293065128082
- 1:54.104248651330444
- 0:13.126798347917324
- 1:53.97660226815845
- 0:12.863786669785929
- 1:53.392341300502146
- 0:12.758939633808883
- 1:53.154674506993565
- 0:12.7549614060709
- 1:53.144885114678864
- 0:12.754202395532223
- 1:53.142161520530635
- 0:12.754305978779511
- 1:53.14017653201493
- 0:12.754426572620961
- 1:53.14008873854695
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.201520718640515
- 1:54.13476008434651
- 0:13.199676378939497
- 1:54.1341835717925
- system:index:20181001T101019_20181001T101019_T33UUV
- system:time_start:1538388619000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.569824418611857
- 1:52.55368823097488
- 0:13.60962260906991
- 1:52.93169903102065
- 0:13.609017215899572
- 1:52.932115159807864
- 0:13.606426265459499
- 1:52.93331076702325
- 0:13.464781136561317
- 1:52.95492598796289
- 0:13.441014069494335
- 1:52.95851738346224
- 0:12.723616720463141
- 1:53.05605205615767
- 0:12.716344923149078
- 1:53.05627974747831
- 0:12.714195636207695
- 1:53.05250098771659
- 0:12.708663751370263
- 1:53.0402581850451
- 0:12.54339269384383
- 1:52.66214416226676
- 0:12.381096947447997
- 1:52.28373490485073
- 0:12.359663587675543
- 1:52.23307883824607
- 0:12.354301626393129
- 1:52.220275819897175
- 0:12.35309741452725
- 1:52.21598353580029
- 0:12.353022664947225
- 1:52.21499058387708
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20181001T101019_20181001T101558_T32UQD
- system:time_start:1538388958000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.714908629753099
- 1:53.05459590481835
- 0:12.714894208051078
- 1:53.0545745471116
- 0:12.536660496429073
- 1:52.646380288085126
- 0:12.36160065071115
- 1:52.23793014024187
- 0:12.360944479994648
- 1:52.23412543638612
- 0:12.36099825365733
- 1:52.233220963963866
- 0:12.361117097803955
- 1:52.23313353311593
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.658101694039585
- 1:52.92454740170488
- 0:13.658076924363586
- 1:52.92459842412115
- 0:13.657432764835331
- 1:52.92497340296342
- 0:13.653795239089993
- 1:52.92602154822433
- 0:13.459019359937544
- 1:52.95602286322143
- 0:12.750096311060275
- 1:53.052609839403694
- 0:12.732063249764165
- 1:53.054965154396704
- 0:12.719436980514184
- 1:53.05634445235172
- 0:12.7167375379718
- 1:53.05629261655301
- 0:12.716695852497486
- 1:53.05626904607539
- 0:12.716633041066107
- 1:53.056267436434105
- 0:12.714908629753099
- 1:53.05459590481835
- system:index:20181001T101019_20181001T101558_T33UUU
- system:time_start:1538388958000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181004T102019_20181004T102018_T32UQD
- system:time_start:1538648418000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181004T102019_20181004T102018_T32UQE
- system:time_start:1538648418000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181004T102019_20181004T102018_T33UUU
- system:time_start:1538648418000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181004T102019_20181004T102018_T33UUV
- system:time_start:1538648418457
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.773737329457038
- 1:53.18993103231169
- 0:12.769543790778107
- 1:53.18352212278034
- 0:12.758556389870463
- 1:53.16065871186215
- 0:12.56721134077309
- 1:52.72564974139486
- 0:12.37983303079822
- 1:52.29024684808647
- 0:12.370129517095787
- 1:52.26677876641752
- 0:12.353953600521463
- 1:52.22730336766261
- 0:12.350629732199248
- 1:52.21821465686535
- 0:12.350399305994973
- 1:52.215155197526926
- 0:12.350505860298801
- 1:52.21506210599126
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20181006T101021_20181006T101510_T32UQD
- system:time_start:1538820910078
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.170470900668464
- 1:54.075879298328516
- 0:13.170346085863493
- 1:54.07585198029115
- 0:13.167252019710254
- 1:54.07269302749513
- 0:13.15917578810432
- 1:54.05623060814766
- 0:13.11244954614309
- 1:53.95475552689481
- 0:12.930295689752386
- 1:53.549895914374915
- 0:12.751773359373388
- 1:53.14468108535032
- 0:12.73488338477261
- 1:53.105267643897086
- 0:12.734692616334149
- 1:53.10306873219799
- 0:12.73534065656124
- 1:53.1026357543057
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.170470900668464
- 1:54.075879298328516
- system:index:20181006T101021_20181006T101510_T32UQE
- system:time_start:1538820910078
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.789299392005558
- 1:53.22918358776315
- 0:12.789222650237154
- 1:53.22916754031057
- 0:12.769085944058379
- 1:53.183997207053686
- 0:12.591773026230392
- 1:52.78131439488686
- 0:12.417597313211328
- 1:52.37838403101751
- 0:12.360372305140537
- 1:52.24384102917356
- 0:12.358183343830401
- 1:52.23622505974852
- 0:12.358344001925502
- 1:52.233521318702046
- 0:12.358369933397432
- 1:52.233470580374416
- 0:12.35899711215372
- 1:52.23311258460888
- 0:12.359074272963237
- 1:52.233087854550874
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.789354406658127
- 1:53.22921453474213
- 0:12.789299392005558
- 1:53.22918358776315
- system:index:20181006T101021_20181006T101510_T33UUU
- system:time_start:1538820910078
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.197803384036805
- 1:54.13470443958448
- 0:13.195987144771378
- 1:54.13301268973063
- 0:13.19251862676372
- 1:54.12809448766321
- 0:13.16649486103131
- 1:54.072681352787995
- 0:13.138084348704835
- 1:54.010757628938954
- 0:13.11725118706974
- 1:53.965126261427855
- 0:12.940393579836403
- 1:53.57169746402727
- 0:12.766702258056357
- 1:53.17801789775074
- 0:12.757089707503596
- 1:53.15571725238853
- 0:12.754736442488777
- 1:53.14919637418844
- 0:12.753193480990861
- 1:53.144301325927124
- 0:12.753392912291691
- 1:53.1404816903749
- 0:12.754099645824859
- 1:53.14008252827539
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20181006T101021_20181006T101510_T33UUV
- system:time_start:1538820910078
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.97562444075535
- 1:52.93945164530273
- 0:11.975668314772742
- 1:52.93941901170587
- 0:11.975680511139325
- 1:52.93937756554
- 0:11.9757123569614
- 1:52.93936584462985
- 0:11.986679437852418
- 1:52.9363907085305
- 0:12.00181887819877
- 1:52.93348941836616
- 0:13.566024229138318
- 1:52.63508287620228
- 0:13.578121055349529
- 1:52.63461508461861
- 0:13.57819316992376
- 1:52.63464895712501
- 0:13.578271575290634
- 1:52.634677113592765
- 0:13.578277682288535
- 1:52.63469168380498
- 0:13.605939964218331
- 1:52.89707450638613
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181009T102021_20181009T102020_T32UQD
- system:time_start:1539080420000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181009T102021_20181009T102020_T32UQE
- system:time_start:1539080420000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648051596411346
- 1:53.242050249354
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.024037542301427
- 1:52.93134962699359
- 0:12.024083631586809
- 1:52.931320734311136
- 0:12.02409697962835
- 1:52.93128149041296
- 0:12.024129289412562
- 1:52.93127028957503
- 0:12.043669447472706
- 1:52.926360903923566
- 0:12.853821281491205
- 1:52.7738268862999
- 0:13.658366923981168
- 1:52.615731789629585
- 0:13.658406439597112
- 1:52.61572923326771
- 0:13.667413657845158
- 1:52.61583088003179
- 0:13.667480767599761
- 1:52.61586818675301
- 0:13.667555179434963
- 1:52.61590015206771
- 0:13.667559346149448
- 1:52.61591502767991
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- system:index:20181009T102021_20181009T102020_T33UUU
- system:time_start:1539080420000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181009T102021_20181009T102020_T33UUV
- system:time_start:1539080420000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.563510223232296
- 1:52.49292864888853
- 0:13.596732474190672
- 1:52.81019325179776
- 0:13.592790555537075
- 1:52.81290855170014
- 0:13.49685820834261
- 1:52.83333074467105
- 0:13.152298876299042
- 1:52.902580350740465
- 0:12.80035559603954
- 1:52.97104647724931
- 0:12.430286054717287
- 1:53.03897635895681
- 0:12.134995225316947
- 1:53.09029980455255
- 0:12.0411126707896
- 1:53.10622715574886
- 0:12.006539576954463
- 1:53.11196299494215
- 0:11.988732023607207
- 1:53.11403200701224
- 0:11.987825662845026
- 1:53.114054793238516
- 0:11.987671026764396
- 1:53.113988957074596
- 0:11.957284850221884
- 1:52.670211292103495
- 0:11.92767912889857
- 1:52.2263187283873
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20181009T102021_20181009T102559_T32UQD
- system:time_start:1539080759000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.662026148346872
- 1:52.79716673932712
- 0:13.65415872250458
- 1:52.79926060109329
- 0:13.640707501771129
- 1:52.802345067472885
- 0:13.604857854129056
- 1:52.81002072412927
- 0:13.49454855971339
- 1:52.83348661109052
- 0:13.447441300464712
- 1:52.84312921464599
- 0:13.145044061267546
- 1:52.90406266728984
- 0:12.838721052318538
- 1:52.96362012529137
- 0:12.495521522478708
- 1:53.027017384715364
- 0:12.210387030880398
- 1:53.077319204013264
- 0:12.030861892208193
- 1:53.10804495508835
- 0:12.011877281118208
- 1:53.110000107787705
- 0:12.01171251447768
- 1:53.10993309129641
- 0:12.04196428993257
- 1:52.66816913294924
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071555935023119
- 1:52.22629968318028
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20181009T102021_20181009T102559_T33UUU
- system:time_start:1539080759000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.77104203873819
- 1:53.189467229345766
- 0:12.770965979521145
- 1:53.189427896019666
- 0:12.754221936714695
- 1:53.15215991925366
- 0:12.59074856557176
- 1:52.779445272271424
- 0:12.43018950392513
- 1:52.40644185466941
- 0:12.365680052397535
- 1:52.254493994447216
- 0:12.34959081931955
- 1:52.2160869202849
- 0:12.349546843053414
- 1:52.21550198558227
- 0:12.350186135836818
- 1:52.21507123589608
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.772913963124415
- 1:53.189957102891476
- 0:12.77104203873819
- 1:53.189467229345766
- system:index:20181011T101019_20181011T101020_T32UQD
- system:time_start:1539252620000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.169496899431925
- 1:54.075883792577415
- 0:13.169417744315451
- 1:54.07587355983293
- 0:13.167248506972696
- 1:54.072686143663894
- 0:12.95549983052478
- 1:53.606271336985245
- 0:12.748618706879515
- 1:53.13938388538452
- 0:12.737376585272893
- 1:53.11329328786854
- 0:12.733989024416276
- 1:53.105295620784254
- 0:12.733778211233762
- 1:53.10286484394234
- 0:12.733818613223864
- 1:53.10283427025707
- 0:12.733824287930727
- 1:53.10279203406094
- 0:12.734175019481304
- 1:53.10267232274587
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16955630884026
- 1:54.075911023473104
- 0:13.169496899431925
- 1:54.075883792577415
- system:index:20181011T101019_20181011T101020_T32UQE
- system:time_start:1539252620000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.78839172898732
- 1:53.228081997465225
- 0:12.788372503813473
- 1:53.22805576230092
- 0:12.78674239668486
- 1:53.224787564782936
- 0:12.778682089607525
- 1:53.20683410359058
- 0:12.61112633284884
- 1:52.82594552284386
- 0:12.357373622657873
- 1:52.235141018876945
- 0:12.35737033159396
- 1:52.23511823793879
- 0:12.357466302813126
- 1:52.23350165274137
- 0:12.35749223530653
- 1:52.233450914625315
- 0:12.35811941611142
- 1:52.23309292422743
- 0:12.358196576669535
- 1:52.23306819483536
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790252576440476
- 1:53.229231165558666
- 0:12.790167430407873
- 1:53.22921553214035
- 0:12.78839172898732
- 1:53.228081997465225
- system:index:20181011T101019_20181011T101020_T33UUU
- system:time_start:1539252620000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.196924762717599
- 1:54.13466850398466
- 0:13.196860229459215
- 1:54.13466722295648
- 0:13.195064313550777
- 1:54.132994196303855
- 0:13.189174313052362
- 1:54.12048787560724
- 0:13.176594408809121
- 1:54.0933301015425
- 0:12.963285069850082
- 1:53.6233337731376
- 0:12.754541433762553
- 1:53.152973843505755
- 0:12.750536624323361
- 1:53.14372443011984
- 0:12.750533049476262
- 1:53.14370170045186
- 0:12.750702104085564
- 1:53.14046810277541
- 0:12.750728136033436
- 1:53.14041728919601
- 0:12.751365541651337
- 1:53.140057388712236
- 0:12.75144410515941
- 1:53.1400324151271
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19696787477602
- 1:54.13469198006072
- 0:13.196924762717599
- 1:54.13466850398466
- system:index:20181011T101019_20181011T101020_T33UUV
- system:time_start:1539252620000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181014T102019_20181014T102019_T32UQD
- system:time_start:1539512419000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181014T102019_20181014T102019_T32UQE
- system:time_start:1539512419000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181014T102019_20181014T102019_T33UUU
- system:time_start:1539512419000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181014T102019_20181014T102019_T33UUV
- system:time_start:1539512419000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.770142181970106
- 1:53.19004502954945
- 0:12.759121490411674
- 1:53.16711708042734
- 0:12.752431328739906
- 1:53.15221643775919
- 0:12.564397291779729
- 1:52.7238455664167
- 0:12.380202373151974
- 1:52.29509355586419
- 0:12.364129037745453
- 1:52.25723663013816
- 0:12.354482245993449
- 1:52.23430500228994
- 0:12.347958922474088
- 1:52.21775157983149
- 0:12.347793413706555
- 1:52.21555176038227
- 0:12.348432715878253
- 1:52.21512102098351
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20181016T101021_20181016T101021_T32UQD
- system:time_start:1539684621000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16760752552203
- 1:54.07597869525144
- 0:13.159660614771845
- 1:54.061072200272015
- 0:13.149122642815044
- 1:54.03822743211991
- 0:12.998117593467676
- 1:53.70658590657563
- 0:12.871092424733162
- 1:53.42257603017191
- 0:12.759167919021033
- 1:53.1676536995992
- 0:12.742264842851972
- 1:53.12825020543361
- 0:12.732060352022202
- 1:53.10373699984563
- 0:12.731981885770447
- 1:53.10283127775482
- 0:12.732089801506097
- 1:53.102737831309284
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20181016T101021_20181016T101021_T32UQE
- system:time_start:1539684621000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.786534036587726
- 1:53.229119051966606
- 0:12.786519678622273
- 1:53.22909830308334
- 0:12.773603444886103
- 1:53.2008053784702
- 0:12.562322305360379
- 1:52.71920744056525
- 0:12.355490028086779
- 1:52.237257148118616
- 0:12.355486702767323
- 1:52.23723428783399
- 0:12.355711046476436
- 1:52.23346228619395
- 0:12.355736981012546
- 1:52.23341154850108
- 0:12.356364201450807
- 1:52.23305364737912
- 0:12.356441325967758
- 1:52.233028840777486
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.786660037019558
- 1:53.229164502790226
- 0:12.786605101962895
- 1:53.22913371325848
- 0:12.786534036587726
- 1:53.229119051966606
- system:index:20181016T101021_20181016T101021_T33UUU
- system:time_start:1539684621000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.195967705498001
- 1:54.13467693533649
- 0:13.19238128649416
- 1:54.131335871998836
- 0:13.166352350513357
- 1:54.075915448472585
- 0:13.145433080002675
- 1:54.03082772453178
- 0:12.916014659302629
- 1:53.52380618072094
- 0:12.800945064022176
- 1:53.26335019013719
- 0:12.768805804319689
- 1:53.18938590452919
- 0:12.761600395554922
- 1:53.17252704978153
- 0:12.749612120973113
- 1:53.144246377666455
- 0:12.749608584206419
- 1:53.14422372718092
- 0:12.749824640077989
- 1:53.14009188281926
- 0:12.74994523886021
- 1:53.14000409451679
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20181016T101021_20181016T101021_T33UUV
- system:time_start:1539684621000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181019T102031_20181019T102029_T32UQD
- system:time_start:1539944429000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181019T102031_20181019T102029_T32UQE
- system:time_start:1539944429000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181019T102031_20181019T102029_T33UUU
- system:time_start:1539944429000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181019T102031_20181019T102029_T33UUV
- system:time_start:1539944429000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.770180922691397
- 1:53.19004374054181
- 0:12.768182312950113
- 1:53.18843381689008
- 0:12.765957684424196
- 1:53.18363054812287
- 0:12.75483321036964
- 1:53.159156557256956
- 0:12.585933088168458
- 1:52.77500395012521
- 0:12.420134654463281
- 1:52.39054350236813
- 0:12.387872274282804
- 1:52.31484118349051
- 0:12.366414704126749
- 1:52.26418704576403
- 0:12.350324371229975
- 1:52.22578823298387
- 0:12.347041647274779
- 1:52.217237721767866
- 0:12.346895029942347
- 1:52.21528911795001
- 0:12.347289858203156
- 1:52.21515346054683
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20181021T101039_20181021T101201_T32UQD
- system:time_start:1540116721000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.166766316928848
- 1:54.07598507011655
- 0:13.166701980014944
- 1:54.07598689188988
- 0:13.16467408468301
- 1:54.074408110023974
- 0:13.162404949627204
- 1:54.0701521333965
- 0:12.944846549185003
- 1:53.589353333287846
- 0:12.732436097588769
- 1:53.10804862233084
- 0:12.731165847565547
- 1:53.10376197088927
- 0:12.731087581624061
- 1:53.10285939772839
- 0:12.731195461454048
- 1:53.1027658727817
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.166812503769583
- 1:54.0760062435302
- 0:13.166766316928848
- 1:54.07598507011655
- system:index:20181021T101039_20181021T101201_T32UQE
- system:time_start:1540116721000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.354708565057626
- 1:52.23562072006605
- 0:12.35470520165395
- 1:52.23559802902575
- 0:12.354852705074116
- 1:52.23311764382573
- 0:12.355264777101148
- 1:52.23300249879705
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.786660037019558
- 1:53.229164502790226
- 0:12.78653036338455
- 1:53.229119869516154
- 0:12.782447147131485
- 1:53.22093152691639
- 0:12.774389287828182
- 1:53.20297772586287
- 0:12.535902682038971
- 1:52.65985272041921
- 0:12.383970665385084
- 1:52.30588146168931
- 0:12.368530457121617
- 1:52.26938653196111
- 0:12.364682117350872
- 1:52.26012746387938
- 0:12.354708565057626
- 1:52.23562072006605
- system:index:20181021T101039_20181021T101201_T33UUU
- system:time_start:1540116721000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.748071926703943
- 1:53.140119312904865
- 0:12.74808351636687
- 1:53.1400774960488
- 0:12.748450023497783
- 1:53.13997585925901
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.193296481127124
- 1:54.13463692183664
- 0:13.193209266998384
- 1:54.134621485729525
- 0:13.192272814789655
- 1:54.1340426971233
- 0:13.19054136020987
- 1:54.13129903958402
- 0:13.167900270882301
- 1:54.082410926327086
- 0:12.977345601575596
- 1:53.66133072446935
- 0:12.790454728841622
- 1:53.239959641167246
- 0:12.755912749526019
- 1:53.16109167823334
- 0:12.747904082692092
- 1:53.14259570201939
- 0:12.747900509801969
- 1:53.14257297257522
- 0:12.748027378396277
- 1:53.140147767512445
- 0:12.748071926703943
- 1:53.140119312904865
- system:index:20181021T101039_20181021T101201_T33UUV
- system:time_start:1540116721000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181024T102059_20181024T102428_T32UQD
- system:time_start:1540376668000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181024T102059_20181024T102428_T32UQE
- system:time_start:1540376668000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181024T102059_20181024T102428_T33UUU
- system:time_start:1540376668000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181024T102059_20181024T102428_T33UUV
- system:time_start:1540376668000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77285662559716
- 1:53.18995891189564
- 0:12.76982977719823
- 1:53.18675683604821
- 0:12.758697449550118
- 1:53.162272750722956
- 0:12.752008465395456
- 1:53.147372708862385
- 0:12.563935905072537
- 1:52.718192915116376
- 0:12.37970990023298
- 1:52.28863146770923
- 0:12.360355329634283
- 1:52.242232668999684
- 0:12.35382981004207
- 1:52.225682714704895
- 0:12.352342269518784
- 1:52.217621452244416
- 0:12.352176904584145
- 1:52.215427199561546
- 0:12.352816183280765
- 1:52.21499643444564
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20181026T101111_20181026T101108_T32UQD
- system:time_start:1540548668000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.170360436394871
- 1:54.07588312073743
- 0:13.167087213294415
- 1:54.071073379749315
- 0:13.159014236361877
- 1:54.05461706066793
- 0:13.112290554364114
- 1:53.95314187525691
- 0:12.916142273073207
- 1:53.51932900246807
- 0:12.838833227485171
- 1:53.34536502959445
- 0:12.758744058349638
- 1:53.16280998165982
- 0:12.741843370650315
- 1:53.12340627879605
- 0:12.735023352462877
- 1:53.106881905282044
- 0:12.734692616334149
- 1:53.10306873219799
- 0:12.73534065656124
- 1:53.1026357543057
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20181026T101111_20181026T101108_T32UQE
- system:time_start:1540548668000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35899711215372
- 1:52.23311258460888
- 0:12.359074272963237
- 1:52.233087854550874
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.789354406658127
- 1:53.22921453474213
- 0:12.789224838577173
- 1:53.22916989259428
- 0:12.786770629039705
- 1:53.224249302951726
- 0:12.773799305901395
- 1:53.19703325692145
- 0:12.766562410557828
- 1:53.18071302231075
- 0:12.574792291084322
- 1:52.74266251632176
- 0:12.38670310705269
- 1:52.3043232189947
- 0:12.360469228200223
- 1:52.24222675997249
- 0:12.358183238149175
- 1:52.23622762271385
- 0:12.358346155243732
- 1:52.23348413243571
- 0:12.35899711215372
- 1:52.23311258460888
- system:index:20181026T101111_20181026T101108_T33UUU
- system:time_start:1540548668000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.197803384036805
- 1:54.13470443958448
- 0:13.195983211475506
- 1:54.13300897944749
- 0:13.19258729402752
- 1:54.12647376051043
- 0:13.187527860473384
- 1:54.116149002595186
- 0:13.17156723408419
- 1:54.08246704437954
- 0:12.939087870971557
- 1:53.57059627214788
- 0:12.911330605289663
- 1:53.508620577454565
- 0:12.858512279920737
- 1:53.38954951112471
- 0:12.768973811806593
- 1:53.186152330504086
- 0:12.749781157728663
- 1:53.141012767124174
- 0:12.749777620970985
- 1:53.14099011766433
- 0:12.749824640077989
- 1:53.14009188281926
- 0:12.74994523886021
- 1:53.14000409451679
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20181026T101111_20181026T101108_T33UUV
- system:time_start:1540548668000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181029T102131_20181029T102131_T32UQD
- system:time_start:1540808491459
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181029T102131_20181029T102131_T32UQE
- system:time_start:1540808491459
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181029T102131_20181029T102131_T33UUU
- system:time_start:1540808491459
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181029T102131_20181029T102131_T33UUV
- system:time_start:1540808491459
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.76570061649031
- 1:53.19018568551517
- 0:12.763703378369225
- 1:53.18857663705974
- 0:12.76152566693766
- 1:53.18431135764822
- 0:12.722470071416355
- 1:53.09649215947704
- 0:12.600744122176424
- 1:52.81961730291459
- 0:12.518659334422722
- 1:52.63050194392232
- 0:12.394204152874275
- 1:52.340023581922544
- 0:12.351299088203282
- 1:52.23871350111968
- 0:12.345939839605922
- 1:52.22591273921479
- 0:12.342657854520988
- 1:52.21736210305848
- 0:12.342533032838398
- 1:52.215701016015146
- 0:12.343172363166902
- 1:52.21527030747991
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20181031T101139_20181031T101140_T32UQD
- system:time_start:1540980700000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.162135879950428
- 1:54.07616847337051
- 0:13.159988797589996
- 1:54.073481868998755
- 0:13.157725018176716
- 1:54.06923487504331
- 0:13.146003677196566
- 1:54.04373227674584
- 0:12.934552242524639
- 1:53.57620060258125
- 0:12.72796408524789
- 1:53.10818900645229
- 0:12.726694325317816
- 1:53.103902210923295
- 0:12.726616184766014
- 1:53.10299962986133
- 0:12.726724109117516
- 1:53.10290618854776
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20181031T101139_20181031T101140_T32UQE
- system:time_start:1540980700000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.782115486091206
- 1:53.229050721050825
- 0:12.782039657883615
- 1:53.22903632468199
- 0:12.77795750951772
- 1:53.22084823336541
- 0:12.773914386130539
- 1:53.2121401387794
- 0:12.661860290021574
- 1:52.959133166775736
- 0:12.391176422738432
- 1:52.33301929991749
- 0:12.358009386696779
- 1:52.25404323245665
- 0:12.350320185104037
- 1:52.23552231521271
- 0:12.350316899101594
- 1:52.23549953381029
- 0:12.350461330918693
- 1:52.23307474000143
- 0:12.350505214191577
- 1:52.23304638292878
- 0:12.35051689906112
- 1:52.23300456575565
- 0:12.350876670570232
- 1:52.23290403589539
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.782169318157482
- 1:53.22908096376881
- 0:12.782115486091206
- 1:53.229050721050825
- system:index:20181031T101139_20181031T101140_T33UUU
- system:time_start:1540980700000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.743956582564907
- 1:53.139894306765065
- 0:12.744004237083393
- 1:53.139891637482144
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.188707134450901
- 1:54.134567909956466
- 0:13.188620044447584
- 1:54.13455245688145
- 0:13.18768038989418
- 1:54.133971625779196
- 0:13.184280875983593
- 1:54.12742689185426
- 0:13.17588488958741
- 1:54.10949994767747
- 0:12.961340614210162
- 1:53.63543736603995
- 0:12.751429303023475
- 1:53.16100705160988
- 0:12.743422480448654
- 1:53.14251089083692
- 0:12.743418910813897
- 1:53.142488161194116
- 0:12.743546097874644
- 1:53.1400629573672
- 0:12.743590647472907
- 1:53.14003450467493
- 0:12.743602204682283
- 1:53.13999260886355
- 0:12.743956582564907
- 1:53.139894306765065
- system:index:20181031T101139_20181031T101140_T33UUV
- system:time_start:1540980700000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181103T102159_20181103T102338_T32UQD
- system:time_start:1541240618000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181103T102159_20181103T102338_T32UQE
- system:time_start:1541240618000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181103T102159_20181103T102338_T33UUU
- system:time_start:1541240618000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181103T102159_20181103T102338_T33UUV
- system:time_start:1541240618000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.775529377299533
- 1:53.18987417514248
- 0:12.77341221143126
- 1:53.18663894425602
- 0:12.769117185121846
- 1:53.178675622964136
- 0:12.758085528010286
- 1:53.15527649800648
- 0:12.558433152453233
- 1:52.69973974601588
- 0:12.363109663293239
- 1:52.243774030568304
- 0:12.353463159485562
- 1:52.220833903655944
- 0:12.353029402116249
- 1:52.215080468805354
- 0:12.353136062108002
- 1:52.214987363124145
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20181105T101211_20181105T101404_T32UQD
- system:time_start:1541412844000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.737350494219372
- 1:53.102696974797716
- 0:12.737752010876477
- 1:53.102559895955736
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.17311985342091
- 1:54.07578726494335
- 0:13.16999583587393
- 1:54.07259811377463
- 0:13.158530137896143
- 1:54.04977664855803
- 0:13.147996259380127
- 1:54.02693249345587
- 0:13.072206099830586
- 1:53.861141215680505
- 0:13.03627176898402
- 1:53.78194204603065
- 0:12.896123170522158
- 1:53.468983625391836
- 0:12.758132128585673
- 1:53.155813426606265
- 0:12.751350438968132
- 1:53.13983654065404
- 0:12.741094255125832
- 1:53.11479380669165
- 0:12.737612969309938
- 1:53.10572038303202
- 0:12.737350494219372
- 1:53.102696974797716
- system:index:20181105T101211_20181105T101404_T32UQE
- system:time_start:1541412844000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.791936900631871
- 1:53.22923131018561
- 0:12.791917008148083
- 1:53.229212250525336
- 0:12.789383906570452
- 1:53.225921818915076
- 0:12.774050369387593
- 1:53.19218226810946
- 0:12.580944540649586
- 1:52.75196002144605
- 0:12.391565339297152
- 1:52.31144498346217
- 0:12.360756322825143
- 1:52.23737501538329
- 0:12.360753029252157
- 1:52.23735223385683
- 0:12.36097690838751
- 1:52.233580215367
- 0:12.36100272701884
- 1:52.23352948805214
- 0:12.361629899626505
- 1:52.23317147618589
- 0:12.361707061189732
- 1:52.2331467441303
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792048871934362
- 1:53.229264495186534
- 0:12.792001221337578
- 1:53.2292377613567
- 0:12.791936900631871
- 1:53.22923131018561
- system:index:20181105T101211_20181105T101404_T33UUU
- system:time_start:1541412844000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.200562355801745
- 1:54.13474575536518
- 0:13.197844301676641
- 1:54.132500561232234
- 0:13.192728113511068
- 1:54.12324005829994
- 0:13.16670855506562
- 1:54.06783042137536
- 0:13.056053185582046
- 1:53.825531085798886
- 0:13.03044133497114
- 1:53.76901659128384
- 0:12.886360227420672
- 1:53.44668648766457
- 0:12.82643109338818
- 1:53.310749920572064
- 0:12.799023517699798
- 1:53.24820999703832
- 0:12.75725838558173
- 1:53.15248377289218
- 0:12.754905176077564
- 1:53.1459627798625
- 0:12.753362291460233
- 1:53.1410677023684
- 0:12.753392912291691
- 1:53.1404816903749
- 0:12.754099645824859
- 1:53.14008252827539
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- system:index:20181105T101211_20181105T101404_T33UUV
- system:time_start:1541412844000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181108T102231_20181108T102225_T32UQD
- system:time_start:1541672766000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181108T102231_20181108T102225_T32UQE
- system:time_start:1541672752000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181108T102231_20181108T102225_T33UUU
- system:time_start:1541672765000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181108T102231_20181108T102225_T33UUV
- system:time_start:1541672751000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.762103986850542
- 1:53.1902994262363
- 0:12.761058700595859
- 1:53.18919328754731
- 0:12.758837272016336
- 1:53.18439508227238
- 0:12.736469100527454
- 1:53.13383013610816
- 0:12.654163306869387
- 1:52.946425229952936
- 0:12.506987097039243
- 1:52.606563387010645
- 0:12.484138854952453
- 1:52.55327187401482
- 0:12.356823836492346
- 1:52.25366704190445
- 0:12.34610222407886
- 1:52.22806737548029
- 0:12.34178118684302
- 1:52.21738750914008
- 0:12.341625423422428
- 1:52.21531415541742
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20181110T101239_20181110T101317_T32UQD
- system:time_start:1541844971000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:13.16041040251753
- 1:54.07622821545748
- 0:13.160347487106641
- 1:54.07619933987789
- 0:13.160270857132494
- 1:54.07618569092425
- 0:13.160255021266833
- 1:54.07616528834317
- 0:13.159124007992
- 1:54.07404382531341
- 0:12.945322787929898
- 1:53.60417926352767
- 0:12.736469025758135
- 1:53.13382997733222
- 0:12.72415133009083
- 1:53.10560454752024
- 0:12.72393336962833
- 1:53.10308366671144
- 0:12.723990633809123
- 1:53.10304042626526
- 0:12.724041298286535
- 1:53.1029902279641
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- system:index:20181110T101239_20181110T101317_T32UQE
- system:time_start:1541844956000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.779412468058235
- 1:53.22902962604568
- 0:12.778475355395265
- 1:53.22843121857939
- 0:12.777650271794181
- 1:53.22677605474389
- 0:12.731869653191914
- 1:53.12341286732227
- 0:12.675151942282739
- 1:52.99446072301975
- 0:12.617186218461608
- 1:52.86167470854629
- 0:12.564286943140509
- 1:52.739749543661716
- 0:12.483537553091386
- 1:52.55192301605623
- 0:12.421278187052122
- 1:52.405981914976756
- 0:12.355567692602952
- 1:52.250751191757324
- 0:12.349410821386531
- 1:52.23604245240374
- 0:12.348657252989659
- 1:52.23385456770962
- 0:12.348709464692792
- 1:52.23297976434652
- 0:12.349121524223015
- 1:52.23286464424309
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20181110T101239_20181110T101317_T33UUU
- system:time_start:1541844970000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.740083132233982
- 1:53.13982008009153
- 0:12.74010784901911
- 1:53.13981773175662
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.186871547856214
- 1:54.13454025593314
- 0:13.186816173907623
- 1:54.13451018331229
- 0:13.186744185699673
- 1:54.13449702776225
- 0:13.186728498757752
- 1:54.13447650832587
- 0:13.185033532051333
- 1:54.13121353996168
- 0:12.960744134635954
- 1:53.6383940669834
- 0:12.741489513397896
- 1:53.14517405020684
- 0:12.73989381794203
- 1:53.14136487942093
- 0:12.73989028831607
- 1:53.141342229357235
- 0:12.739965740069257
- 1:53.139905087793
- 0:12.74002885958072
- 1:53.139864774392976
- 0:12.740083132233982
- 1:53.13982008009153
- system:index:20181110T101239_20181110T101317_T33UUV
- system:time_start:1541844955000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.77462435358101
- 1:53.18990287616973
- 0:12.77350411104569
- 1:53.18771018810205
- 0:12.771285892051674
- 1:53.18292200778508
- 0:12.762373553386054
- 1:53.163235780667314
- 0:12.759027825044019
- 1:53.15578588422876
- 0:12.549129947098946
- 1:52.67816244258728
- 0:12.496847890076536
- 1:52.55721420280723
- 0:12.44054564268895
- 1:52.42610829562371
- 0:12.401743879186604
- 1:52.33494941882547
- 0:12.374886706020709
- 1:52.27150032186461
- 0:12.352386991838765
- 1:52.218174893612094
- 0:12.351288297530575
- 1:52.21546020133917
- 0:12.351939444033336
- 1:52.21502135355613
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20181115T101251_20181115T101254_T32UQD
- system:time_start:1542276968000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.171321942732298
- 1:54.0758497257267
- 0:13.170271801183274
- 1:54.07530102387886
- 0:13.165576640440502
- 1:54.06518310015764
- 0:13.119895733640835
- 1:53.965294038858225
- 0:13.087239792454753
- 1:53.893551252717714
- 0:12.921630234264
- 1:53.524815482122634
- 0:12.759027600234397
- 1:53.15578540781492
- 0:12.738838366882147
- 1:53.1094696498936
- 0:12.73657855057869
- 1:53.104134983053996
- 0:12.7364562157422
- 1:53.10272505016687
- 0:12.736857769432548
- 1:53.10258805406959
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20181115T101251_20181115T101254_T32UQE
- system:time_start:1542276953000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.792048871934362
- 1:53.229264495186534
- 0:12.7919312630892
- 1:53.22923075405069
- 0:12.791069852696946
- 1:53.22811185666833
- 0:12.789436604945118
- 1:53.2248374951963
- 0:12.548291750437716
- 1:52.676295614429975
- 0:12.498106790483002
- 1:52.56032527756004
- 0:12.495761034278086
- 1:52.55488022765909
- 0:12.435756795422662
- 1:52.41493004612311
- 0:12.373049690954952
- 1:52.26732902613387
- 0:12.359188880378566
- 1:52.23409274025768
- 0:12.359223828570398
- 1:52.23350371218585
- 0:12.359919320588617
- 1:52.23310677362192
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792048871934362
- 1:53.229264495186534
- system:index:20181115T101251_20181115T101254_T33UUU
- system:time_start:1542276967000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.752497932860253
- 1:53.140523829310055
- 0:12.752517017953336
- 1:53.1404532397571
- 0:12.753203376662412
- 1:53.14006564417505
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.197885700448566
- 1:54.13470568721752
- 0:13.197765175370959
- 1:54.13467237520547
- 0:13.196873832485412
- 1:54.13355507975132
- 0:13.191832921994846
- 1:54.12268497359931
- 0:13.085899306025814
- 1:53.890736549247514
- 0:13.076778286785366
- 1:53.87063372480268
- 0:12.91571881006945
- 1:53.511394249646436
- 0:12.757287285251767
- 1:53.1519465962606
- 0:12.753282314720376
- 1:53.14269828683991
- 0:12.752497932860253
- 1:53.140523829310055
- system:index:20181115T101251_20181115T101254_T33UUV
- system:time_start:1542276952000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181118T102311_20181118T102312_T32UQD
- system:time_start:1542536764000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181118T102311_20181118T102312_T32UQE
- system:time_start:1542536750000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181118T102311_20181118T102312_T33UUU
- system:time_start:1542536764000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181118T102311_20181118T102312_T33UUV
- system:time_start:1542536749000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.614500298080566
- 1:52.97820560093425
- 0:13.614584318881333
- 1:52.9782354625279
- 0:13.634034600698282
- 1:53.15942775214035
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76398886948041
- 1:53.19023984379334
- 0:12.763931072008967
- 1:53.190212384901535
- 0:12.763859193596875
- 1:53.190202574357734
- 0:12.763841161359919
- 1:53.190182820242306
- 0:12.762800370132874
- 1:53.188591751153346
- 0:12.728105347544368
- 1:53.109806842753
- 0:12.725846885577788
- 1:53.10447177702695
- 0:12.725613223381195
- 1:53.10177180875091
- 0:12.725663983394046
- 1:53.1017334433662
- 0:12.72569292650459
- 1:53.10168760182115
- 0:12.725727920249138
- 1:53.10167963720033
- 0:12.749639134315744
- 1:53.098229297397666
- 0:13.60229186134247
- 1:52.97918378004123
- 0:13.61115429715685
- 1:52.9782990922254
- 0:13.614427759343505
- 1:52.978171815140094
- 0:13.614500298080566
- 1:52.97820560093425
- system:index:20181120T101319_20181120T101318_T32UQD
- system:time_start:1542708962000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.726114912151582
- 1:53.102928875674365
- 0:12.726161837128984
- 1:53.10292378747062
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.159495820980238
- 1:54.07625994475034
- 0:13.159431107888256
- 1:54.0762301688008
- 0:13.159347870217347
- 1:54.076213362278025
- 0:13.154658150029025
- 1:54.066100996858864
- 0:12.938843331088544
- 1:53.58820217274365
- 0:12.728105310204844
- 1:53.10980676338764
- 0:12.725846885577788
- 1:53.10447177702695
- 0:12.72572963832838
- 1:53.103117362921836
- 0:12.725770044088186
- 1:53.103086792157896
- 0:12.725775728515902
- 1:53.103044556034405
- 0:12.726114912151582
- 1:53.102928875674365
- system:index:20181120T101319_20181120T101318_T32UQE
- system:time_start:1542708955000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.780279045685203
- 1:53.228469433964065
- 0:12.780260249115777
- 1:53.228441814270845
- 0:12.77543038697728
- 1:53.217562412244696
- 0:12.739310270115908
- 1:53.13542266000834
- 0:12.728100549285525
- 1:53.109853491351615
- 0:12.724916289044307
- 1:53.102239544994525
- 0:12.724944876686983
- 1:53.102206336164365
- 0:12.724934128503463
- 1:53.10216604915207
- 0:12.725908682061162
- 1:53.10161574904621
- 0:12.728661339636364
- 1:53.10112123722702
- 0:12.748535086067859
- 1:53.098261331452946
- 0:13.652290513662207
- 1:52.971682145467504
- 0:13.655595608613734
- 1:52.971357908781464
- 0:13.656502337907042
- 1:52.971368092899226
- 0:13.656649568936219
- 1:52.97143936569143
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.781271130469108
- 1:53.229064273801384
- 0:12.781185960701718
- 1:53.22904855332755
- 0:12.780279045685203
- 1:53.228469433964065
- system:index:20181120T101319_20181120T101318_T33UUU
- system:time_start:1542708962000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.741739457505428
- 1:53.14029835073285
- 0:12.741765424331588
- 1:53.14024763094913
- 0:12.742402930002275
- 1:53.139887693766205
- 0:12.742481528699424
- 1:53.13986280641939
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.186871547856214
- 1:54.13454025593314
- 0:13.186784343495452
- 1:54.13452481431928
- 0:13.18584474206795
- 1:54.13394396590292
- 0:13.184139417417779
- 1:54.13066075260304
- 0:13.179105008827989
- 1:54.11979629068143
- 0:13.104820949166282
- 1:53.95684025537145
- 0:13.075763502907204
- 1:53.892731969592525
- 0:12.907302376990629
- 1:53.516911092781946
- 0:12.741714693688795
- 1:53.14086008767931
- 0:12.741711125361416
- 1:53.140837358471806
- 0:12.741739457505428
- 1:53.14029835073285
- system:index:20181120T101319_20181120T101318_T33UUV
- system:time_start:1542708955000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.340755384541932
- 1:52.21542887620287
- 0:12.340862063272986
- 1:52.2153357822552
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.555977714582466
- 1:52.42015905653217
- 0:13.58141227486768
- 1:52.66462973258604
- 0:13.607216215529668
- 1:52.909081548449485
- 0:13.633401978044326
- 1:53.1535650894477
- 0:13.631877295996782
- 1:53.15419911561641
- 0:13.583221120640879
- 1:53.161488204809366
- 0:12.763880667506111
- 1:53.19024325056476
- 0:12.762800407641231
- 1:53.18859183058963
- 0:12.566379928380504
- 1:52.742674358002255
- 0:12.374136544265772
- 1:52.29634659381762
- 0:12.3473848714764
- 1:52.23342823593394
- 0:12.343106882320134
- 1:52.22329538359655
- 0:12.340944804327114
- 1:52.21795084273152
- 0:12.340755384541932
- 1:52.21542887620287
- system:index:20181120T101319_20181120T101557_T32UQD
- system:time_start:1542708970000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.633401978044326
- 1:53.1535650894477
- 0:13.631877370190578
- 1:53.15419902331385
- 0:13.550533763408394
- 1:53.16652152585974
- 0:13.519557586903169
- 1:53.1709423419666
- 0:13.456691623919012
- 1:53.17979337765791
- 0:13.36099773763064
- 1:53.19305783518407
- 0:12.890464301703986
- 1:53.256870409659626
- 0:12.852216662590807
- 1:53.26189207105261
- 0:12.819297079954836
- 1:53.26619067427382
- 0:12.80237410348166
- 1:53.26835250284326
- 0:12.798709350069922
- 1:53.26846950334457
- 0:12.797684563828264
- 1:53.26791722069908
- 0:12.79431193893208
- 1:53.260442987260426
- 0:12.728105347544368
- 1:53.109806842753
- 0:12.725846885577788
- 1:53.10447177702695
- 0:12.725724832002642
- 1:53.10306191839942
- 0:12.726126457495925
- 1:53.102924871376366
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20181120T101319_20181120T101557_T32UQE
- system:time_start:1542708962000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.515944000935256
- 1:53.17143277889916
- 0:13.484367524125485
- 1:53.17588979066414
- 0:13.445565804644406
- 1:53.181323162022544
- 0:13.403144192022147
- 1:53.18723492000538
- 0:13.320981413611136
- 1:53.19851164461965
- 0:13.080580571434947
- 1:53.23102256517093
- 0:13.05885573574767
- 1:53.23390994795484
- 0:12.781208847655067
- 1:53.22906311039193
- 0:12.780270019604284
- 1:53.2284637308401
- 0:12.576998212483987
- 1:52.76698604468566
- 0:12.377848967004082
- 1:52.305206114433766
- 0:12.347747329679839
- 1:52.234375892584694
- 0:12.34783920796015
- 1:52.23283577590173
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.664905090153672
- 1:52.70310138879898
- 0:13.651054738485204
- 1:53.1508882943977
- 0:13.648947528690124
- 1:53.151616225030686
- 0:13.62688742975951
- 1:53.1549631152855
- 0:13.54390788068496
- 1:53.16746258541437
- 0:13.515944000935256
- 1:53.17143277889916
- system:index:20181120T101319_20181120T101557_T33UUU
- system:time_start:1542708970000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.633314035438051
- 1:53.15387142562334
- 0:13.63323544643417
- 1:53.15395143948258
- 0:13.626888342765616
- 1:53.15496300907258
- 0:13.54390788068496
- 1:53.16746258541437
- 0:13.515944000935256
- 1:53.17143277889916
- 0:13.484367524125485
- 1:53.17588979066414
- 0:13.449175271392868
- 1:53.180830811319346
- 0:13.406754604499536
- 1:53.18674384411419
- 0:12.907722093448497
- 1:53.254545380177
- 0:12.79902992075829
- 1:53.26877397296998
- 0:12.798000388571033
- 1:53.26875497182835
- 0:12.785879525779764
- 1:53.241493223476844
- 0:12.741710469834633
- 1:53.14085036482337
- 0:12.74174134114443
- 1:53.14026117692548
- 0:12.742448260286974
- 1:53.139862161179856
- 0:13.63317833821813
- 1:53.15342027017572
- 0:13.6333261588493
- 1:53.153491585314406
- 0:13.633314035438051
- 1:53.15387142562334
- system:index:20181120T101319_20181120T101557_T33UUV
- system:time_start:1542708962000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181123T102339_20181123T102334_T32UQD
- system:time_start:1542968767836
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181123T102339_20181123T102334_T32UQE
- system:time_start:1542968753488
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181123T102339_20181123T102334_T33UUU
- system:time_start:1542968766998
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181123T102339_20181123T102334_T33UUV
- system:time_start:1542968752936
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.78011778400726
- 1:53.189728437459465
- 0:12.780059962821387
- 1:53.18970098820822
- 0:12.779987953319829
- 1:53.18969120155885
- 0:12.779970021672177
- 1:53.18967143831008
- 0:12.77892864836053
- 1:53.18808060489716
- 0:12.571185470166272
- 1:52.714466628537515
- 0:12.368128279972018
- 1:52.24039283843023
- 0:12.359563811174862
- 1:52.22012926079719
- 0:12.358480014396974
- 1:52.21745267174427
- 0:12.358289565148626
- 1:52.21493075116629
- 0:12.358346061464848
- 1:52.21488764475964
- 0:12.358396217105119
- 1:52.214837640457525
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- system:index:20181125T101331_20181125T101402_T32UQD
- system:time_start:1543140965000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.177787452924548
- 1:54.07562500415912
- 0:13.177698492858793
- 1:54.075613921972916
- 0:13.17667357174114
- 1:54.07507853619384
- 0:13.170792812919716
- 1:54.062303421546034
- 0:12.958537728199037
- 1:53.59510697604761
- 0:12.925319879922958
- 1:53.520646505660245
- 0:12.822982197029082
- 1:53.28920798796393
- 0:12.74749703026218
- 1:53.11621282984735
- 0:12.74185440692195
- 1:53.10289836152574
- 0:12.741865443932928
- 1:53.10283118624093
- 0:12.742494742500357
- 1:53.10241070616153
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.177787452924548
- 1:54.07562500415912
- system:index:20181125T101331_20181125T101402_T32UQE
- system:time_start:1543140951000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.797325764330308
- 1:53.22933105965169
- 0:12.797305867414078
- 1:53.22931200108877
- 0:12.796458627756703
- 1:53.22821172169778
- 0:12.795639855790117
- 1:53.22657079890313
- 0:12.79322219684979
- 1:53.22113017984789
- 0:12.577744673732731
- 1:52.729504718080676
- 0:12.366901420432047
- 1:52.23751485878327
- 0:12.365369216653047
- 1:52.23370305021702
- 0:12.365397478045905
- 1:52.23366992395837
- 0:12.36538741946945
- 1:52.233629670401534
- 0:12.366018116442667
- 1:52.233269527961596
- 0:12.366095279261126
- 1:52.23324479257642
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.797437748606528
- 1:53.22936423863998
- 0:12.797390204028552
- 1:53.22933749502596
- 0:12.797325764330308
- 1:53.22933105965169
- system:index:20181125T101331_20181125T101402_T33UUU
- system:time_start:1543140965000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.20431069959926
- 1:54.1348017543702
- 0:13.204176036363258
- 1:54.13475563095131
- 0:13.200798745676742
- 1:54.127673866987124
- 0:13.195760891125897
- 1:54.11681113991705
- 0:12.95871888857528
- 1:53.59574597956818
- 0:12.87804153389213
- 1:53.414172927097916
- 0:12.852107767454738
- 1:53.355449588206135
- 0:12.822211567744013
- 1:53.287476591811064
- 0:12.786788626602117
- 1:53.20644501719618
- 0:12.758711747219007
- 1:53.141711024718504
- 0:12.7587855397095
- 1:53.140295255347056
- 0:12.759205201768523
- 1:53.140178791943626
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20431069959926
- 1:54.1348017543702
- system:index:20181125T101331_20181125T101402_T33UUV
- system:time_start:1543140950000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181128T102351_20181128T102346_T32UQD
- system:time_start:1543400762000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181128T102351_20181128T102346_T32UQE
- system:time_start:1543400748000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181128T102351_20181128T102346_T33UUU
- system:time_start:1543400761000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181128T102351_20181128T102346_T33UUV
- system:time_start:1543400747000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.339033089518912
- 1:52.21585513506976
- 0:12.339044602618555
- 1:52.215788004200945
- 0:12.339665530842824
- 1:52.21536971780287
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.763030626195047
- 1:53.19027014496963
- 0:12.762008019628402
- 1:53.18971740911867
- 0:12.643101510325502
- 1:52.92113113008673
- 0:12.52574500457965
- 1:52.65241753565763
- 0:12.40660944574022
- 1:52.37528418723617
- 0:12.378675402430009
- 1:52.30970825586124
- 0:12.354028928955959
- 1:52.25158798477224
- 0:12.341191314454308
- 1:52.22119103229699
- 0:12.339033089518912
- 1:52.21585513506976
- system:index:20181130T101349_20181130T101352_T32UQD
- system:time_start:1543572969000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.157666602911316
- 1:54.0763232186458
- 0:13.157602088564097
- 1:54.076293588907156
- 0:13.157524437431535
- 1:54.07627810616896
- 0:13.157509771348709
- 1:54.076257319661515
- 0:13.15401267840094
- 1:54.068822108739234
- 0:13.11885024280187
- 1:53.99177560758523
- 0:13.07566292140825
- 1:53.896643939059274
- 0:12.89863575329782
- 1:53.501282641476486
- 0:12.725045676096533
- 1:53.10557656510889
- 0:12.72482764558999
- 1:53.10305568870727
- 0:12.724884871855402
- 1:53.10301236844161
- 0:12.724935572812791
- 1:53.10296224910445
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- system:index:20181130T101349_20181130T101352_T32UQE
- system:time_start:1543572954000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.779474862956416
- 1:53.229030778206116
- 0:12.779421035165264
- 1:53.229000534027406
- 0:12.779350618449682
- 1:53.22898721870926
- 0:12.779335508935143
- 1:53.228966634678166
- 0:12.778520439965025
- 1:53.22733176205254
- 0:12.531962804289488
- 1:52.66678463702803
- 0:12.500596756051625
- 1:52.5943687936692
- 0:12.374619673884933
- 1:52.300278142794696
- 0:12.347623384391419
- 1:52.23654197105303
- 0:12.346869795927754
- 1:52.23435398754314
- 0:12.346956201035182
- 1:52.23290598233438
- 0:12.34701835988953
- 1:52.23286589538151
- 0:12.347075204827759
- 1:52.2328186345825
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20181130T101349_20181130T101352_T33UUU
- system:time_start:1543572968000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.185035769184287
- 1:54.13451259511774
- 0:13.184948684759714
- 1:54.13449713890046
- 0:13.184009136459661
- 1:54.133916273171835
- 0:13.18230391505844
- 1:54.130633039533045
- 0:13.172239436869198
- 1:54.10890518272004
- 0:13.117961791151881
- 1:53.989948246545346
- 0:13.073100393606403
- 1:53.89107106286744
- 0:13.000444112891287
- 1:53.72968326033804
- 0:12.74157372151041
- 1:53.14355569502912
- 0:12.74078594333307
- 1:53.14137030033242
- 0:12.740861967787668
- 1:53.1399220765322
- 0:12.740982727061406
- 1:53.13983436566791
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.185035769184287
- 1:54.13451259511774
- system:index:20181130T101349_20181130T101352_T33UUV
- system:time_start:1543572953000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.951296290514737
- 1:52.56094039409075
- 0:11.951334539206416
- 1:52.56092078899148
- 0:11.957909494721825
- 1:52.55958318799009
- 0:11.982661896238854
- 1:52.55464456155556
- 0:13.525882972538238
- 1:52.25468469165088
- 0:13.531060349960459
- 1:52.2536756135712
- 0:13.537411678300394
- 1:52.25252889764147
- 0:13.538596419014295
- 1:52.25248331260943
- 0:13.538750270460577
- 1:52.252547060719365
- 0:13.585756074726726
- 1:52.70603019488709
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.97202400825622
- 1:52.88693357067609
- 0:11.949985749648375
- 1:52.56184609576588
- 0:11.950005296840503
- 1:52.56179436292731
- 0:11.951296290514737
- 1:52.56094039409075
- system:index:20181203T102359_20181203T102401_T32UQD
- system:time_start:1543832764000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181203T102359_20181203T102401_T32UQE
- system:time_start:1543832752000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.027692556281512
- 1:52.87802352978147
- 0:12.050322484136961
- 1:52.544047245228356
- 0:12.050352496930087
- 1:52.54402812445895
- 0:12.050346037516556
- 1:52.54400202222714
- 0:12.05036986978185
- 1:52.54398486028652
- 0:12.05129945528789
- 1:52.54346266942683
- 0:12.06313771351932
- 1:52.538889371910614
- 0:13.500902269163056
- 1:52.25617770945746
- 0:13.533541034003612
- 1:52.253528252564955
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- system:index:20181203T102359_20181203T102401_T33UUU
- system:time_start:1543832764000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181203T102359_20181203T102401_T33UUV
- system:time_start:1543832751473
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.779170612163252
- 1:53.18973269650771
- 0:12.779099907485334
- 1:53.189729198149884
- 0:12.778082829242006
- 1:53.18865350937734
- 0:12.564987762869514
- 1:52.70386001260977
- 0:12.356811445984274
- 1:52.21858872376888
- 0:12.355727872913944
- 1:52.21591200330842
- 0:12.355686522122612
- 1:52.21536463801643
- 0:12.355705479345447
- 1:52.21531275995217
- 0:12.356282006782225
- 1:52.2149242597196
- 0:12.356355447195682
- 1:52.21489573258679
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.779221789695521
- 1:53.18975694371358
- 0:12.779170612163252
- 1:53.18973269650771
- system:index:20181205T101401_20181205T101359_T32UQD
- system:time_start:1544004965000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.1758947456536
- 1:54.07569080652169
- 0:13.174846941971548
- 1:54.07514340262464
- 0:13.173702625823182
- 1:54.07299838363556
- 0:13.115195705647649
- 1:53.945486220687
- 0:13.083737572835203
- 1:53.87640009070987
- 0:12.948539316550447
- 1:53.57546918242214
- 0:12.75337822209704
- 1:53.13221794611371
- 0:12.744392047308295
- 1:53.111453537249034
- 0:12.741003263275246
- 1:53.103456111308596
- 0:12.740927615229124
- 1:53.10258443634549
- 0:12.741329170550383
- 1:53.102447423292084
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20181205T101401_20181205T101359_T32UQE
- system:time_start:1544004950000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.363680346730153
- 1:52.233302894271276
- 0:12.363711593651075
- 1:52.23329110002262
- 0:12.364029179299148
- 1:52.2332022464992
- 0:12.36407591385611
- 1:52.23319975601033
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.796539607416358
- 1:53.229347659022785
- 0:12.796454527620273
- 1:53.22933193907784
- 0:12.795547286253809
- 1:53.22875294728239
- 0:12.795528586988688
- 1:53.22872531821891
- 0:12.578747597436468
- 1:52.73545995313271
- 0:12.366646138460002
- 1:52.241825836313446
- 0:12.363581120017532
- 1:52.234200592498674
- 0:12.363577895638254
- 1:52.23417796925182
- 0:12.363625789119014
- 1:52.23336967763223
- 0:12.363669668947216
- 1:52.233341314941036
- 0:12.363680346730153
- 1:52.233302894271276
- system:index:20181205T101401_20181205T101359_T33UUU
- system:time_start:1544004964000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.202364132511752
- 1:54.134772647557774
- 0:13.199788039842915
- 1:54.12981708859371
- 0:13.140371261116838
- 1:54.00054523509861
- 0:13.112046402111622
- 1:53.93861559571524
- 0:13.086293393213143
- 1:53.88211284718112
- 0:12.957786787259943
- 1:53.59626941975081
- 0:12.944703605272919
- 1:53.56691684650635
- 0:12.89498825459007
- 1:53.454930304699545
- 0:12.793111202629307
- 1:53.223285581799196
- 0:12.7658045798352
- 1:53.16073820742623
- 0:12.757791643835752
- 1:53.142242908868994
- 0:12.757788063786037
- 1:53.14222018003405
- 0:12.7578909921712
- 1:53.14024408578724
- 0:12.758011695290277
- 1:53.140156275882006
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20181205T101401_20181205T101359_T33UUV
- system:time_start:1544004949000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181208T102401_20181208T102407_T32UQD
- system:time_start:1544264762000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181208T102401_20181208T102407_T32UQE
- system:time_start:1544264748000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181208T102401_20181208T102407_T33UUU
- system:time_start:1544264761000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181208T102401_20181208T102407_T33UUV
- system:time_start:1544264747000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76482270565064
- 1:53.19021345073392
- 0:12.763800162246701
- 1:53.189660721638475
- 0:12.567820511180301
- 1:52.743980076147814
- 0:12.412470049303717
- 1:52.38267023754168
- 0:12.373767850157453
- 1:52.29149994723778
- 0:12.351258469195399
- 1:52.23817501595157
- 0:12.345899482780528
- 1:52.2253747445396
- 0:12.342657993225467
- 1:52.21736266438473
- 0:12.342508882076514
- 1:52.21537920063189
- 0:12.342615558131351
- 1:52.21528610500772
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20181210T101409_20181210T101406_T32UQD
- system:time_start:1544436967636
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.725757358904135
- 1:53.1034039447821
- 0:12.72576846379912
- 1:53.10333684940628
- 0:12.726397815475355
- 1:53.10291638196706
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16132503150331
- 1:54.076196558271874
- 0:13.161200353300458
- 1:54.07616921587228
- 0:13.160151192824651
- 1:54.07509792362344
- 0:13.157832082726422
- 1:54.07030940579866
- 0:12.940350074840733
- 1:53.589771606147316
- 0:12.728012054923914
- 1:53.1087303263879
- 0:12.725757358904135
- 1:53.1034039447821
- system:index:20181210T101409_20181210T101406_T32UQE
- system:time_start:1544436952744
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.782106921044008
- 1:53.22907981326423
- 0:12.781169728144663
- 1:53.228481431306875
- 0:12.779530111487187
- 1:53.2251927344108
- 0:12.584188687371483
- 1:52.781699610730605
- 0:12.52752681492065
- 1:52.651045705854834
- 0:12.440051968067529
- 1:52.447396510188845
- 0:12.408226996613932
- 1:52.37278312207028
- 0:12.385781989089073
- 1:52.31995038202512
- 0:12.37033592467575
- 1:52.28345591888811
- 0:12.357227563365303
- 1:52.252407158601216
- 0:12.351070493715543
- 1:52.2376998989842
- 0:12.349534765499143
- 1:52.23387588420302
- 0:12.349587012967245
- 1:52.23299942829067
- 0:12.349999074282813
- 1:52.23288430462691
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- system:index:20181210T101409_20181210T101406_T33UUU
- system:time_start:1544436966775
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.187789414253729
- 1:54.134554120659864
- 0:13.187756157648018
- 1:54.13453606395144
- 0:13.187711519430382
- 1:54.13454026829069
- 0:13.187681766071147
- 1:54.13452605463354
- 0:13.18677199690235
- 1:54.13396364961977
- 0:13.18675205310825
- 1:54.13393750871453
- 0:13.18590416209274
- 1:54.13230538748428
- 0:13.183386086551888
- 1:54.126872517922706
- 0:12.960887149930018
- 1:53.63542961646303
- 0:12.743366344417854
- 1:53.143589725249164
- 0:12.742578544162324
- 1:53.14140433374735
- 0:12.742654492549057
- 1:53.139956109647244
- 0:12.742717610963888
- 1:53.139915794618986
- 0:12.74277521244768
- 1:53.1398683173219
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20181210T101409_20181210T101406_T33UUV
- system:time_start:1544436952145
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181213T102419_20181213T102422_T32UQD
- system:time_start:1544696764000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181213T102419_20181213T102422_T32UQE
- system:time_start:1544696750000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181213T102419_20181213T102422_T33UUU
- system:time_start:1544696763000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181213T102419_20181213T102422_T33UUV
- system:time_start:1544696749000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.770168487798811
- 1:53.19004417384519
- 0:12.769124044796131
- 1:53.18893916587096
- 0:12.768033396122325
- 1:53.18680381664877
- 0:12.677813828783332
- 1:52.982932378254645
- 0:12.656773493540673
- 1:52.93501182205751
- 0:12.622542243160991
- 1:52.85673024302616
- 0:12.533668747399895
- 1:52.6516413445765
- 0:12.362680669614132
- 1:52.24972231890071
- 0:12.350836288555403
- 1:52.220917074362525
- 0:12.348658115612404
- 1:52.21553489740746
- 0:12.349309421675445
- 1:52.21509613223508
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20181215T101421_20181215T101420_T32UQD
- system:time_start:1544868965000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.731123073675972
- 1:53.1032356355305
- 0:12.73113416840054
- 1:53.10316853996826
- 0:12.731763603008538
- 1:53.10274802959604
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.167727071677572
- 1:54.0759745426715
- 0:13.167582078984049
- 1:54.075931024468964
- 0:13.166440718341544
- 1:54.07379078444509
- 0:13.164125490259108
- 1:54.0690119460859
- 0:12.946177873345691
- 1:53.589039643002074
- 0:12.733378576527532
- 1:53.10856197055164
- 0:12.731123073675972
- 1:53.1032356355305
- system:index:20181215T101421_20181215T101420_T32UQE
- system:time_start:1544868950000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.787465196888514
- 1:53.229179494044594
- 0:12.786579290438194
- 1:53.22802856536715
- 0:12.784946349069687
- 1:53.224754150416565
- 0:12.77447309315355
- 1:53.20136091130564
- 0:12.680771161054027
- 1:52.98971524868624
- 0:12.61881452039988
- 1:52.84821986022637
- 0:12.542327519719867
- 1:52.67185568097071
- 0:12.52428389245304
- 1:52.62993608083037
- 0:12.36112334654108
- 1:52.24601896840213
- 0:12.356523875636052
- 1:52.23457223230468
- 0:12.35660803327783
- 1:52.233157013902044
- 0:12.357020108873456
- 1:52.2330418617511
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20181215T101421_20181215T101420_T33UUU
- system:time_start:1544868964000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.748437901176727
- 1:53.13997917848326
- 0:12.748485558043402
- 1:53.13997650710138
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.194214264617418
- 1:54.134650661851175
- 0:13.194165429266228
- 1:54.1346240970834
- 0:13.194093865737795
- 1:54.13461733242861
- 0:13.193202569450467
- 1:54.13350001617228
- 0:13.190680463952223
- 1:54.12806111870767
- 0:12.968452987028199
- 1:53.63852506609675
- 0:12.751180531667075
- 1:53.14859430654676
- 0:12.747988640723776
- 1:53.14097883602863
- 0:12.747985105262968
- 1:53.140956186490016
- 0:12.748027378396277
- 1:53.140147767512445
- 0:12.748071926703943
- 1:53.140119312904865
- 0:12.74808351636687
- 1:53.1400774960488
- 0:12.748437901176727
- 1:53.13997917848326
- system:index:20181215T101421_20181215T101420_T33UUV
- system:time_start:1544868949000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181218T102431_20181218T102426_T32UQD
- system:time_start:1545128762000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181218T102431_20181218T102426_T32UQE
- system:time_start:1545128748000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181218T102431_20181218T102426_T33UUU
- system:time_start:1545128761000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181218T102431_20181218T102426_T33UUV
- system:time_start:1545128747000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.782748065881174
- 1:53.18961558281252
- 0:12.782670575039683
- 1:53.18960505805122
- 0:12.781616699817695
- 1:53.18799522184085
- 0:12.573467729612137
- 1:52.71520736682043
- 0:12.3700052202054
- 1:52.24195824550427
- 0:12.3614395413005
- 1:52.22169483874875
- 0:12.359275409263265
- 1:52.21635066265077
- 0:12.359173050367668
- 1:52.21499550398486
- 0:12.359212877860276
- 1:52.21496511013061
- 0:12.359218926345967
- 1:52.2149228299139
- 0:12.359563728085199
- 1:52.21480436697526
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.782805891018155
- 1:53.18964303045649
- 0:12.782748065881174
- 1:53.18961558281252
- system:index:20181220T101429_20181220T101427_T32UQD
- system:time_start:1545300968895
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.179521834219166
- 1:54.07556468975354
- 0:13.17844234447921
- 1:54.07446297080515
- 0:13.176121212382284
- 1:54.06967492753633
- 0:13.171437119268711
- 1:54.05958252544907
- 0:13.132767175315966
- 1:53.975105792645586
- 0:13.105903276369176
- 1:53.916120758752434
- 0:12.946882856211019
- 1:53.56257130118263
- 0:12.79063615184657
- 1:53.20875044437989
- 0:12.755780823175597
- 1:53.128904014789065
- 0:12.747922904624078
- 1:53.11080264164859
- 0:12.744517498112987
- 1:53.102767340161336
- 0:12.745177607698865
- 1:53.102326231312716
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20181220T101429_20181220T101427_T32UQE
- system:time_start:1545300954028
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.800132273537326
- 1:53.22941400928025
- 0:12.800084611601811
- 1:53.229387279330716
- 0:12.8000202827751
- 1:53.22938083329877
- 0:12.800000383642763
- 1:53.22936177528467
- 0:12.799152083205813
- 1:53.22826028527891
- 0:12.595715788990468
- 1:52.76628796742201
- 0:12.396404445238362
- 1:52.30399812329897
- 0:12.368593072595198
- 1:52.23863180132534
- 0:12.367059864633255
- 1:52.23481781688305
- 0:12.367056527964298
- 1:52.234795205248005
- 0:12.367141694239294
- 1:52.233358264357875
- 0:12.367203845658409
- 1:52.23331816520175
- 0:12.367260532090347
- 1:52.23327082643053
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20181220T101429_20181220T101427_T33UUU
- system:time_start:1545300968038
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.206035591335285
- 1:54.13482742028549
- 0:13.205154750548479
- 1:54.13313339167212
- 0:13.197595806124465
- 1:54.11683863744744
- 0:13.130721259837745
- 1:53.97073032620215
- 0:13.103269333649495
- 1:53.91042980841066
- 0:13.07838214006332
- 1:53.855556765696356
- 0:13.02963152233505
- 1:53.747427517755334
- 0:12.96801218506221
- 1:53.60992884189275
- 0:12.796731057608158
- 1:53.222813151601464
- 0:12.76941935930124
- 1:53.16026651782222
- 0:12.761400641951797
- 1:53.141761701245926
- 0:12.761474285437021
- 1:53.140345852072876
- 0:12.761894065639474
- 1:53.140229365369834
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20181220T101429_20181220T101427_T33UUV
- system:time_start:1545300953446
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181223T102429_20181223T102536_T32UQD
- system:time_start:1545560766000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181223T102429_20181223T102536_T32UQE
- system:time_start:1545560752000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181223T102429_20181223T102536_T33UUU
- system:time_start:1545560766000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181223T102429_20181223T102536_T33UUV
- system:time_start:1545560752000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.783701955530614
- 1:53.18961457223044
- 0:12.78361497893178
- 1:53.189603159624006
- 0:12.782616966960687
- 1:53.18906402235799
- 0:12.670227872777515
- 1:52.93567593302218
- 0:12.621674115627298
- 1:52.82491616729876
- 0:12.498674764068328
- 1:52.54123992079876
- 0:12.377332675095282
- 1:52.25739897055632
- 0:12.373045466416988
- 1:52.247267607664824
- 0:12.360111450926466
- 1:52.21578729980275
- 0:12.360067282499982
- 1:52.21520262355948
- 0:12.360706409200855
- 1:52.214771823797705
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.783701955530614
- 1:53.18961457223044
- system:index:20181225T101421_20181225T101424_T32UQD
- system:time_start:1545732966000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.18047176869407
- 1:54.075502307456084
- 0:13.180392444512764
- 1:54.07549201609842
- 0:13.179299391420205
- 1:54.07388664668172
- 0:13.165249080968612
- 1:54.04360592390148
- 0:12.952456442650549
- 1:53.57372062414996
- 0:12.744580422277027
- 1:53.10334379575144
- 0:12.74453283714113
- 1:53.10279636932658
- 0:12.744551686193885
- 1:53.10274452660911
- 0:12.745135978596695
- 1:53.102353940166594
- 0:12.7452107334036
- 1:53.102325136110736
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.180531077165108
- 1:54.07552954468758
- 0:13.18047176869407
- 1:54.075502307456084
- system:index:20181225T101421_20181225T101424_T32UQE
- system:time_start:1545732951000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.800937462696211
- 1:53.22942890605349
- 0:12.800051167823145
- 1:53.22827807649794
- 0:12.79923240849041
- 1:53.226637411094465
- 0:12.793582589383929
- 1:53.21412406288012
- 0:12.674243505772248
- 1:52.94481001454674
- 0:12.620259101692156
- 1:52.82181303487031
- 0:12.591808887822445
- 1:52.75649741074353
- 0:12.377167531153749
- 1:52.25716857536295
- 0:12.371785384288794
- 1:52.24409837989056
- 0:12.370252483907356
- 1:52.240286437961984
- 0:12.367965476330603
- 1:52.234287963650466
- 0:12.368017321723944
- 1:52.233412155130594
- 0:12.368429275130294
- 1:52.23329688980264
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20181225T101421_20181225T101424_T33UUU
- system:time_start:1545732965000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.761881980053655
- 1:53.140232765565884
- 0:12.76192949326127
- 1:53.14023002081146
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.207064149388168
- 1:54.13484277343027
- 0:13.207008860720022
- 1:54.13481269894267
- 0:13.20693128952468
- 1:54.13479856834846
- 0:13.204376753819037
- 1:54.12988568060487
- 0:13.199337239751854
- 1:54.119022086632334
- 0:12.979969864598845
- 1:53.63494411605863
- 0:12.765439966971883
- 1:53.150481543277124
- 0:12.761432970034297
- 1:53.14123256886771
- 0:12.761429349922645
- 1:53.141209761149796
- 0:12.761471455277933
- 1:53.140401408052774
- 0:12.761515999709212
- 1:53.140372947699525
- 0:12.7615275370384
- 1:53.140331050151644
- 0:12.761881980053655
- 1:53.140232765565884
- system:index:20181225T101421_20181225T101424_T33UUV
- system:time_start:1545732950000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20181228T102431_20181228T102427_T32UQD
- system:time_start:1545992764000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20181228T102431_20181228T102427_T32UQE
- system:time_start:1545992750000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20181228T102431_20181228T102427_T33UUU
- system:time_start:1545992763000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20181228T102431_20181228T102427_T33UUV
- system:time_start:1545992749000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.354782769249859
- 1:52.21503053706143
- 0:12.354889426563327
- 1:52.2149374297044
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.777312537321633
- 1:53.18981758887346
- 0:12.776191896001201
- 1:53.18762453975324
- 0:12.655048095725924
- 1:52.91455746279541
- 0:12.630771023807489
- 1:52.859177017737146
- 0:12.614251614891733
- 1:52.82136495208564
- 0:12.496710940356326
- 1:52.54993270650288
- 0:12.380686534876315
- 1:52.278349882545044
- 0:12.35709594878711
- 1:52.22235821414056
- 0:12.354932408932758
- 1:52.21701397956893
- 0:12.354782769249859
- 1:52.21503053706143
- system:index:20181230T101429_20181230T101429_T32UQD
- system:time_start:1546164970000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.174064963701438
- 1:54.0757227651205
- 0:13.173982021720883
- 1:54.07570661227921
- 0:13.171656930234143
- 1:54.07090942193719
- 0:13.165790066641826
- 1:54.05815931349911
- 0:12.951151232091943
- 1:53.584017974744526
- 0:12.741521579394075
- 1:53.109385262676966
- 0:12.739261453351101
- 1:53.10405056734206
- 0:12.73914386779627
- 1:53.102696164289526
- 0:12.739184267271973
- 1:53.10266558865694
- 0:12.739189935498196
- 1:53.10262335241303
- 0:12.739540555666961
- 1:53.10250363560193
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.174129191270419
- 1:54.07575224960105
- 0:13.174064963701438
- 1:54.0757227651205
- system:index:20181230T101429_20181230T101429_T32UQE
- system:time_start:1546164956000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.361858723623293
- 1:52.233624606038106
- 0:12.361876823467359
- 1:52.23355123842134
- 0:12.36255213972577
- 1:52.23316564107286
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.795579144599454
- 1:53.229329837400506
- 0:12.794641815385987
- 1:53.22873163776566
- 0:12.79218625902318
- 1:53.2238095995772
- 0:12.663255402779996
- 1:52.933265010933944
- 0:12.645768575460506
- 1:52.89353628481357
- 0:12.581687169429351
- 1:52.74658006872702
- 0:12.423698347590582
- 1:52.37959631599144
- 0:12.378816429209355
- 1:52.273932288511844
- 0:12.363390568625332
- 1:52.23743646081437
- 0:12.361858723623293
- 1:52.233624606038106
- system:index:20181230T101429_20181230T101429_T33UUU
- system:time_start:1546164970000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.200537862936475
- 1:54.1341692445041
- 0:13.200518404370152
- 1:54.13414186560062
- 0:13.194632645863432
- 1:54.12164858556757
- 0:13.192114535402379
- 1:54.11621701241858
- 0:12.974075339105159
- 1:53.63484453629655
- 0:12.760817243480787
- 1:53.15309200763033
- 0:12.756811392195429
- 1:53.143843756422456
- 0:12.756022954399816
- 1:53.14165852363337
- 0:12.756098445495471
- 1:53.14021028504698
- 0:12.756219188036157
- 1:53.14012255659633
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20155707068725
- 1:54.13476060723407
- 0:13.201469961166016
- 1:54.13474516515951
- 0:13.200537862936475
- 1:54.1341692445041
- system:index:20181230T101429_20181230T101429_T33UUV
- system:time_start:1546164955000
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190721T102029_20190721T102325_T32UQD
- system:time_start:1563704779829
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190721T102029_20190721T102325_T32UQE
- system:time_start:1563704765481
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190721T102029_20190721T102325_T33UUU
- system:time_start:1563704778992
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190721T102029_20190721T102325_T33UUV
- system:time_start:1563704764929
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.34168907146296
- 1:52.21575011367923
- 0:12.341674801377115
- 1:52.21571344448307
- 0:12.342254639251774
- 1:52.215322782323035
- 0:12.342328189217527
- 1:52.21529425333978
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.764884951809924
- 1:53.190211446324525
- 0:12.764823644200579
- 1:53.19018236495399
- 0:12.76474339318115
- 1:53.1901674518241
- 0:12.762563072193032
- 1:53.18589760222019
- 0:12.566093917939556
- 1:52.739175052402906
- 0:12.373808828574967
- 1:52.29203859149587
- 0:12.34598061974804
- 1:52.22645192783853
- 0:12.341663293191306
- 1:52.215780575460904
- 0:12.34168907146296
- 1:52.21575011367923
- system:index:20190723T101031_20190723T101347_T32UQD
- system:time_start:1563876978867
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.161265634092809
- 1:54.07616932237182
- 0:13.161186448966417
- 1:54.07615900299976
- 0:13.160094442130859
- 1:54.07455391502032
- 0:13.157778254071529
- 1:54.06977153707984
- 0:13.048064443621191
- 1:53.828632756302305
- 0:12.939672486507215
- 1:53.58736533103388
- 0:12.72674121696607
- 1:53.10444403118626
- 0:12.726623933168487
- 1:53.103089369108545
- 0:12.726664338509591
- 1:53.10305879801998
- 0:12.726669984527817
- 1:53.103016482529746
- 0:12.727020751124243
- 1:53.102896874268325
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16132503150331
- 1:54.076196558271874
- 0:13.161265634092809
- 1:54.07616932237182
- system:index:20190723T101031_20190723T101347_T32UQE
- system:time_start:1563876963966
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.782169318157482
- 1:53.22908096376881
- 0:12.782115486091206
- 1:53.229050721050825
- 0:12.782045065904459
- 1:53.229037407614626
- 0:12.782029954212417
- 1:53.229016824006884
- 0:12.779585938681453
- 1:53.22411488128425
- 0:12.766703364301247
- 1:53.195281339553034
- 0:12.585831908790201
- 1:52.78416087225114
- 0:12.408227032414153
- 1:52.372783200749446
- 0:12.350256408639073
- 1:52.236601200887215
- 0:12.349502806802896
- 1:52.2344131371633
- 0:12.34958913719436
- 1:52.232965209486686
- 0:12.34965125956089
- 1:52.23292504239801
- 0:12.349707993021882
- 1:52.23287779178739
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20190723T101031_20190723T101347_T33UUU
- system:time_start:1563876978007
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.742658906229076
- 1:53.140270078972826
- 0:12.74268285358533
- 1:53.140252708702725
- 0:12.743299222353093
- 1:53.139904740386555
- 0:12.743377783865311
- 1:53.139879772963084
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.187789414253729
- 1:54.134554120659864
- 0:13.187734038855233
- 1:54.13452404854737
- 0:13.18765649395019
- 1:54.134509903256344
- 0:13.185104249204453
- 1:54.129596621156
- 0:13.18006974920914
- 1:54.11873217493539
- 0:13.091651116687505
- 1:53.92480878996071
- 0:12.925366005271613
- 1:53.55471577565633
- 0:12.761880231218175
- 1:53.18440109881459
- 0:12.742640555792947
- 1:53.14034100247589
- 0:12.742668830610713
- 1:53.14030730652133
- 0:12.742658906229076
- 1:53.140270078972826
- system:index:20190723T101031_20190723T101347_T33UUV
- system:time_start:1563876963367
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190726T102031_20190726T102028_T32UQD
- system:time_start:1564136776109
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190726T102031_20190726T102028_T32UQE
- system:time_start:1564136761763
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190726T102031_20190726T102028_T33UUU
- system:time_start:1564136775272
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190726T102031_20190726T102028_T33UUV
- system:time_start:1564136761212
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.76398886948041
- 1:53.19023984379334
- 0:12.763901918737115
- 1:53.19022841411509
- 0:12.762904256521997
- 1:53.18968917613695
- 0:12.759544558457774
- 1:53.18221374922274
- 0:12.553192912898263
- 1:52.7117698654546
- 0:12.35146149503455
- 1:52.240867574514795
- 0:12.345022543108367
- 1:52.22539961341672
- 0:12.34178118684302
- 1:52.21738750914008
- 0:12.341632129123935
- 1:52.21540404221279
- 0:12.341738806516933
- 1:52.21531094742687
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76398886948041
- 1:53.19023984379334
- system:index:20190728T101029_20190728T101332_T32UQD
- system:time_start:1564308982044
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.161214576864792
- 1:54.07620037090388
- 0:13.16009416735523
- 1:54.074553607204585
- 0:13.15659478626829
- 1:54.06711386343393
- 0:13.140256235833748
- 1:54.03205712766319
- 0:12.93186728166314
- 1:53.571701736716676
- 0:12.728198568264705
- 1:53.110883216416816
- 0:12.725939994059502
- 1:53.10554824516258
- 0:12.725721892419093
- 1:53.10302762351784
- 0:12.725829818206178
- 1:53.102934183059716
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20190728T101029_20190728T101332_T32UQE
- system:time_start:1564308967151
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.348760726234525
- 1:52.2329684870615
- 0:12.348791972211918
- 1:52.232956697388154
- 0:12.349109570044238
- 1:52.23286796906207
- 0:12.3491562609599
- 1:52.232865406945926
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780372953412835
- 1:53.22904757588839
- 0:12.78031780217799
- 1:53.22901655681269
- 0:12.780241149397227
- 1:53.229000410693736
- 0:12.760926982528936
- 1:53.185462419108205
- 0:12.553012576887967
- 1:52.710922739879095
- 0:12.349410892429178
- 1:52.23604260949884
- 0:12.348657252989659
- 1:52.23385456770962
- 0:12.348706149804894
- 1:52.23303526265844
- 0:12.348749959291572
- 1:52.2330069965133
- 0:12.348760726234525
- 1:52.2329684870615
- system:index:20190728T101029_20190728T101332_T33UUU
- system:time_start:1564308981182
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.18767857844998
- 1:54.13455239878436
- 0:13.185104367982493
- 1:54.12959686189466
- 0:13.175861298082204
- 1:54.110039189898494
- 0:13.170832022604548
- 1:54.09917549912969
- 0:12.978074498271576
- 1:53.67455856425608
- 0:12.789056234395531
- 1:53.24964392540586
- 0:12.760926832528003
- 1:53.18546210137347
- 0:12.75450949646285
- 1:53.1707756076999
- 0:12.742498316454892
- 1:53.14303373157943
- 0:12.741710591057466
- 1:53.14084834879615
- 0:12.741756522598076
- 1:53.139973371917
- 0:12.742176266728972
- 1:53.13985696582617
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20190728T101029_20190728T101332_T33UUV
- system:time_start:1564308966554
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190731T102029_20190731T102031_T32UQD
- system:time_start:1564568779212
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190731T102029_20190731T102031_T32UQE
- system:time_start:1564568764860
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190731T102029_20190731T102031_T33UUU
- system:time_start:1564568778374
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190731T102029_20190731T102031_T33UUV
- system:time_start:1564568764309
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.342515628940113
- 1:52.21546891872591
- 0:12.342561422375752
- 1:52.215396262540246
- 0:12.342906325321275
- 1:52.215277842740136
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76482270565064
- 1:53.19021345073392
- 0:12.763800803439192
- 1:53.1896610695282
- 0:12.761572245381945
- 1:53.18484834147312
- 0:12.55677766743962
- 1:52.71759852597318
- 0:12.35653908110477
- 1:52.24989757202321
- 0:12.343700289725163
- 1:52.21950089052763
- 0:12.342617404029543
- 1:52.21682410703429
- 0:12.342515628940113
- 1:52.21546891872591
- system:index:20190802T101031_20190802T101344_T32UQD
- system:time_start:1564740978359
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.162176116286494
- 1:54.07616704800311
- 0:13.161128342524737
- 1:54.07561953493587
- 0:13.159984737065118
- 1:54.073474369192084
- 0:13.154120442264642
- 1:54.06072249251055
- 0:12.980435711786486
- 1:53.67830203095613
- 0:12.810038468301292
- 1:53.295559355999735
- 0:12.785228538495549
- 1:53.23914461897401
- 0:12.747012423784028
- 1:53.15184706684407
- 0:12.73915368398589
- 1:53.133745378806566
- 0:12.730174015349913
- 1:53.11297980362347
- 0:12.726787824775872
- 1:53.104981966154924
- 0:12.72660839905358
- 1:53.1029098113671
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20190802T101031_20190802T101344_T32UQE
- system:time_start:1564740963464
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.349590768189444
- 1:52.233279128551914
- 0:12.34961437565138
- 1:52.233261892774394
- 0:12.350220814327281
- 1:52.232915781503344
- 0:12.350297972620714
- 1:52.232891058104
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.781271130469108
- 1:53.229064273801384
- 0:12.781217299827844
- 1:53.22903403059643
- 0:12.781146956762196
- 1:53.22902062470779
- 0:12.78113173223519
- 1:53.22900005331173
- 0:12.778687876467938
- 1:53.22409808719175
- 0:12.776272525824938
- 1:53.21865713947169
- 0:12.561382326524262
- 1:52.728090154843294
- 0:12.35110260055837
- 1:52.237161203050576
- 0:12.349571846798087
- 1:52.23334920412578
- 0:12.349600117824092
- 1:52.23331608213305
- 0:12.349590768189444
- 1:52.233279128551914
- system:index:20190802T101031_20190802T101344_T33UUU
- system:time_start:1564740977499
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.187688001432614
- 1:54.13397628157728
- 0:13.187668594478177
- 1:54.133948726538186
- 0:13.180117035087944
- 1:54.11765422712584
- 0:13.002389728788653
- 1:53.7270187931389
- 0:12.812501669103664
- 1:53.30132459914797
- 0:12.78430540871046
- 1:53.237148121638974
- 0:12.745773692613744
- 1:53.1490314741065
- 0:12.742582685595503
- 1:53.14141590160279
- 0:12.742579154024105
- 1:53.14139325165706
- 0:12.742654492549057
- 1:53.139956109647244
- 0:12.74277521244768
- 1:53.1398683173219
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.188707134450901
- 1:54.134567909956466
- 0:13.188620044447584
- 1:54.13455245688145
- 0:13.187688001432614
- 1:54.13397628157728
- system:index:20190802T101031_20190802T101344_T33UUV
- system:time_start:1564740962867
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190805T102031_20190805T102440_T32UQD
- system:time_start:1565000775485
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190805T102031_20190805T102440_T32UQE
- system:time_start:1565000761129
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190805T102031_20190805T102440_T33UUU
- system:time_start:1565000774648
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190805T102031_20190805T102440_T33UUV
- system:time_start:1565000760579
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.763896049399985
- 1:53.19024274823601
- 0:12.762851774719545
- 1:53.18913768062684
- 0:12.761761642295646
- 1:53.187002579507116
- 0:12.748424368553389
- 1:53.15773969028653
- 0:12.55100429199427
- 1:52.70670860668918
- 0:12.357823511041186
- 1:52.25525773242476
- 0:12.3492605855809
- 1:52.23499367071813
- 0:12.341740754091795
- 1:52.216849265041766
- 0:12.341634745745344
- 1:52.21543832527799
- 0:12.342029606415018
- 1:52.21530276620358
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20190807T101029_20190807T101242_T32UQD
- system:time_start:1565172981151
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.161214576864792
- 1:54.07620037090388
- 0:13.16009511158163
- 1:54.07455502484312
- 0:13.158962735088933
- 1:54.072430716352365
- 0:13.153152762114381
- 1:54.060216918664004
- 0:13.149657929216326
- 1:54.052781320274114
- 0:12.943941200281756
- 1:53.59909768745441
- 0:12.74282203870941
- 1:53.1449632527639
- 0:12.72599039162001
- 1:53.10609528542138
- 0:12.72484333932733
- 1:53.103385443880654
- 0:12.72550356488007
- 1:53.10294445298239
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20190807T101029_20190807T101242_T32UQE
- system:time_start:1565172966261
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.348713177063733
- 1:52.23325938617633
- 0:12.348736674938074
- 1:52.23324216223377
- 0:12.349343225353035
- 1:52.23289604451834
- 0:12.349420383394529
- 1:52.23287132178483
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780372953412835
- 1:53.22904757588839
- 0:12.780325432758708
- 1:53.22902082410421
- 0:12.780261010229578
- 1:53.22901437786359
- 0:12.780241089756851
- 1:53.22899523635428
- 0:12.779393426369044
- 1:53.22789359724922
- 0:12.502397254579368
- 1:52.59386718543449
- 0:12.355599761414634
- 1:52.25021239151714
- 0:12.349442879030402
- 1:52.23550361258723
- 0:12.348693049697252
- 1:52.2333265438157
- 0:12.348722212395355
- 1:52.23329513841112
- 0:12.348713177063733
- 1:52.23325938617633
- system:index:20190807T101029_20190807T101242_T33UUU
- system:time_start:1565172980289
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.740866364502406
- 1:53.14023604616143
- 0:12.740890312247492
- 1:53.140218676301686
- 0:12.74150668569911
- 1:53.139870718618795
- 0:12.741585246767121
- 1:53.13984575256457
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.187789414253729
- 1:54.134554120659864
- 0:13.187702208497234
- 1:54.13453867983262
- 0:13.186770584525494
- 1:54.13396279087688
- 0:13.186751063067717
- 1:54.13393550246606
- 0:13.18002277172207
- 1:54.11981052619644
- 0:12.958776172371442
- 1:53.63215718263973
- 0:12.74244241047921
- 1:53.144113129834814
- 0:12.740847636644975
- 1:53.14030617545985
- 0:12.740876250262316
- 1:53.140272944053216
- 0:12.740866364502406
- 1:53.14023604616143
- system:index:20190807T101029_20190807T101242_T33UUV
- system:time_start:1565172965663
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190810T102029_20190810T102030_T32UQD
- system:time_start:1565432778170
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190810T102029_20190810T102030_T32UQE
- system:time_start:1565432763816
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190810T102029_20190810T102030_T33UUU
- system:time_start:1565432777331
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190810T102029_20190810T102030_T33UUV
- system:time_start:1565432763265
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.764764541454852
- 1:53.19021526204042
- 0:12.762515464750686
- 1:53.1853584666861
- 0:12.756952270732441
- 1:53.173121309842244
- 0:12.564943079226024
- 1:52.73597170292972
- 0:12.376935383071208
- 1:52.29842511623467
- 0:12.351217850693407
- 1:52.23763653503678
- 0:12.345859023172311
- 1:52.224836271267705
- 0:12.342617404029543
- 1:52.21682410703429
- 0:12.342511499621796
- 1:52.21541348364187
- 0:12.342906325321275
- 1:52.215277842740136
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20190812T101031_20190812T101028_T32UQD
- system:time_start:1565604977395
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.726623933168487
- 1:53.103089369108545
- 0:12.726669984527817
- 1:53.103016482529746
- 0:12.727020751124243
- 1:53.102896874268325
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.162176116286494
- 1:54.07616704800311
- 0:13.161128342524737
- 1:54.07561953493587
- 0:13.15998477653128
- 1:54.07347444939173
- 0:13.155303616261765
- 1:54.06338022127657
- 0:13.149443093876222
- 1:54.05062966523826
- 0:12.935606421282973
- 1:53.57778491824121
- 0:12.72674125429695
- 1:53.10444411054635
- 0:12.726623933168487
- 1:53.103089369108545
- system:index:20190812T101031_20190812T101028_T32UQE
- system:time_start:1565604962497
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.349590768189444
- 1:52.233279128551914
- 0:12.34961437565138
- 1:52.233261892774394
- 0:12.350220814327281
- 1:52.232915781503344
- 0:12.350297972620714
- 1:52.232891058104
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.782169318157482
- 1:53.22908096376881
- 0:12.782121681422536
- 1:53.229054225198304
- 0:12.782051620410476
- 1:53.22904722341599
- 0:12.78118963076679
- 1:53.22792709511839
- 0:12.606796825336628
- 1:52.83179293026601
- 0:12.435449216681349
- 1:52.435426539346984
- 0:12.375002334542941
- 1:52.29381178324358
- 0:12.35032057266019
- 1:52.235523426501295
- 0:12.349570752103535
- 1:52.2333462747126
- 0:12.349599769038422
- 1:52.233314802153274
- 0:12.349590768189444
- 1:52.233279128551914
- system:index:20190812T101031_20190812T101028_T33UUU
- system:time_start:1565604976535
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.188643508796313
- 1:54.13456694679961
- 0:13.18768038989418
- 1:54.133971625779196
- 0:13.185127818323652
- 1:54.12905765585481
- 0:13.180093451506515
- 1:54.11819319261024
- 0:12.965459731472691
- 1:53.64413801405195
- 0:12.755462711773081
- 1:53.16971470415939
- 0:12.751457453975274
- 1:53.16046798392698
- 0:12.745858285123274
- 1:53.147414473929196
- 0:12.744262522662483
- 1:53.1436062856601
- 0:12.743474841833374
- 1:53.141421298878726
- 0:12.743550752185834
- 1:53.139973074630234
- 0:12.743671508508523
- 1:53.139885360662255
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20190812T101031_20190812T101028_T33UUV
- system:time_start:1565604961898
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190815T102031_20190815T102026_T32UQD
- system:time_start:1565864774418
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190815T102031_20190815T102026_T32UQE
- system:time_start:1565864760070
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190815T102031_20190815T102026_T33UUU
- system:time_start:1565864773581
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190815T102031_20190815T102026_T33UUV
- system:time_start:1565864759520
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.735347059381974
- 1:53.120317929530096
- 0:12.73537919151593
- 1:53.12026872475406
- 0:12.786825281056531
- 1:53.113240902855324
- 0:13.110428269894822
- 1:53.06875650060281
- 0:13.614997351577463
- 1:52.99758420641147
- 0:13.616495170344631
- 1:52.99752595757236
- 0:13.616651823867441
- 1:52.99758961706901
- 0:13.634034600698282
- 1:53.15942775214035
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.765781079828303
- 1:53.19018312044206
- 0:12.765694013321587
- 1:53.19017170464163
- 0:12.7647292305519
- 1:53.189650202695496
- 0:12.764692178934753
- 1:53.18962274471238
- 0:12.762468158066905
- 1:53.18481997061015
- 0:12.756857765939824
- 1:53.172044336867394
- 0:12.736662407895881
- 1:53.12572840949729
- 0:12.735530207674397
- 1:53.12305657933463
- 0:12.735295820580756
- 1:53.12035660963128
- 0:12.735347059381974
- 1:53.120317929530096
- system:index:20190817T101029_20190817T101030_T32UQD
- system:time_start:1566036971899
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.735339328556902
- 1:53.12085771602756
- 0:12.73597461687571
- 1:53.12043338338177
- 0:12.743241896679367
- 1:53.11916601622914
- 0:12.859488895928417
- 1:53.10334818160405
- 0:12.886071420094646
- 1:53.09978340548338
- 0:12.90328760473426
- 1:53.0976314614684
- 0:12.909749239051786
- 1:53.09702688055489
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.163034499165272
- 1:54.07613731268385
- 0:13.16186765967002
- 1:54.073948790333
- 0:13.138432918870466
- 1:54.0229448303896
- 0:12.963981154051105
- 1:53.63864164624537
- 0:12.792842184307192
- 1:53.25401338552172
- 0:12.756857765939824
- 1:53.172044336867394
- 0:12.735538054101719
- 1:53.12314675166168
- 0:12.735339328556902
- 1:53.12085771602756
- system:index:20190817T101029_20190817T101030_T32UQE
- system:time_start:1566036964956
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.734738685546729
- 1:53.12071506000243
- 0:12.734750280970399
- 1:53.12067325580716
- 0:12.736613324401754
- 1:53.120156512026036
- 0:12.74175149675748
- 1:53.119352423670584
- 0:12.74792679028146
- 1:53.11848001423965
- 0:12.75650781236888
- 1:53.117293346004104
- 0:12.82603082940568
- 1:53.10779444921997
- 0:13.643571431299046
- 1:52.99316004901831
- 0:13.65436419569627
- 1:52.99166162471215
- 0:13.655872003283147
- 1:52.991678736621374
- 0:13.65601927645933
- 1:52.99174995004203
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.782169318157482
- 1:53.22908096376881
- 0:12.782037395050342
- 1:53.22903381329281
- 0:12.75630338473979
- 1:53.170809610135805
- 0:12.73466518167742
- 1:53.121295522612144
- 0:12.73469416058433
- 1:53.12074350071341
- 0:12.734738685546729
- 1:53.12071506000243
- system:index:20190817T101029_20190817T101030_T33UUU
- system:time_start:1566036971389
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.743546097874644
- 1:53.1400629573672
- 0:12.743602204682283
- 1:53.13999260886355
- 0:12.743968704643127
- 1:53.13989098806998
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.190479136135586
- 1:54.134594569107264
- 0:13.1895146674389
- 1:54.133998394094796
- 0:13.1777432238935
- 1:54.10898899793894
- 0:13.170199758428778
- 1:54.09269369380223
- 0:12.976633747854528
- 1:53.66671280411327
- 0:12.786833510780934
- 1:53.24043196700469
- 0:12.756303272317831
- 1:53.170809371876544
- 0:12.746698278363414
- 1:53.14850936344423
- 0:12.743507213394125
- 1:53.14089394627626
- 0:12.74350368117564
- 1:53.14087129654084
- 0:12.743546097874644
- 1:53.1400629573672
- system:index:20190817T101029_20190817T101030_T33UUV
- system:time_start:1566036964377
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.7647292305519
- 1:53.189650202695496
- 0:12.764692178934753
- 1:53.18962274471238
- 0:12.762468195570941
- 1:53.18482005004249
- 0:12.550523035277243
- 1:52.700786691251054
- 0:12.343453739790261
- 1:52.21626126463883
- 0:12.343412566392528
- 1:52.215713314121714
- 0:12.343431575372271
- 1:52.21566151620112
- 0:12.34400816208325
- 1:52.21527308091121
- 0:12.344081602371041
- 1:52.21524456232905
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.765781079828303
- 1:53.19018312044206
- 0:12.765694013321587
- 1:53.19017170464163
- 0:12.7647292305519
- 1:53.189650202695496
- system:index:20190817T101029_20190817T101605_T32UQD
- system:time_start:1566036979860
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.635549256353519
- 1:53.17345576291365
- 0:13.634024996362633
- 1:53.17408935767617
- 0:13.629583449236003
- 1:53.17480550001986
- 0:13.554434013424476
- 1:53.18634584749415
- 0:13.507499135661668
- 1:53.192993016803804
- 0:13.331991422185563
- 1:53.217328692071675
- 0:12.918061947198181
- 1:53.27323580412261
- 0:12.874465687197056
- 1:53.27897995065006
- 0:12.83619631482562
- 1:53.283996767379584
- 0:12.81392715006318
- 1:53.28687185353266
- 0:12.808433938128509
- 1:53.28704762655215
- 0:12.807384735699932
- 1:53.28594181320443
- 0:12.792842334917138
- 1:53.254013703499034
- 0:12.729987483258048
- 1:53.11082709512372
- 0:12.72772868968855
- 1:53.10549216184339
- 0:12.727502659766188
- 1:53.1028817306831
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20190817T101029_20190817T101605_T32UQE
- system:time_start:1566036971434
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650418682593344
- 1:53.171168513111624
- 0:13.650228605790465
- 1:53.17138650008593
- 0:13.648811717964383
- 1:53.171931131028884
- 0:13.560360345965554
- 1:53.18546261764584
- 0:13.539604077500288
- 1:53.188446539336056
- 0:13.50801717305738
- 1:53.19290980698351
- 0:13.472813468813372
- 1:53.197857734073104
- 0:13.430379013667988
- 1:53.20377909422759
- 0:13.366256834694221
- 1:53.21262643636878
- 0:13.199975203399513
- 1:53.23504389438844
- 0:13.19182516475725
- 1:53.2360017435829
- 0:12.782057427100266
- 1:53.22907893030189
- 0:12.57333517321807
- 1:52.75288352119993
- 0:12.368993879516486
- 1:52.27641147156858
- 0:12.352825827659768
- 1:52.237739265495044
- 0:12.35129008393397
- 1:52.233915256428475
- 0:12.351342322444006
- 1:52.2330388786527
- 0:12.351754277566911
- 1:52.23292375950425
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.664595069056382
- 1:52.71325714854092
- 0:13.650418682593344
- 1:53.171168513111624
- system:index:20190817T101029_20190817T101605_T33UUU
- system:time_start:1566036979145
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.74354895722674
- 1:53.1400074014884
- 0:12.743968704643127
- 1:53.13989098806998
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.650414106166583
- 1:53.17131525599166
- 0:13.648811717964383
- 1:53.171931131028884
- 0:13.560360345965554
- 1:53.18546261764584
- 0:13.539603963341778
- 1:53.18844655252363
- 0:13.469202893296771
- 1:53.19835075094741
- 0:13.42676748793657
- 1:53.20427083594169
- 0:13.369869979563108
- 1:53.21213648270521
- 0:12.894053822565764
- 1:53.2764219267023
- 0:12.857816469906574
- 1:53.28117075515577
- 0:12.809779456089917
- 1:53.287313338111346
- 0:12.807850896818689
- 1:53.28727791403881
- 0:12.796506406363479
- 1:53.26218987553453
- 0:12.786833548404113
- 1:53.240432046486895
- 0:12.756303272317831
- 1:53.170809371876544
- 0:12.746698278363414
- 1:53.14850936344423
- 0:12.743503065717892
- 1:53.14088388135263
- 0:12.74354895722674
- 1:53.1400074014884
- system:index:20190817T101029_20190817T101605_T33UUV
- system:time_start:1566036971154
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190820T102029_20190820T102459_T32UQD
- system:time_start:1566296776770
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190820T102029_20190820T102459_T32UQE
- system:time_start:1566296762412
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190820T102029_20190820T102459_T33UUU
- system:time_start:1566296775931
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190820T102029_20190820T102459_T33UUV
- system:time_start:1566296761860
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.341663648019583
- 1:52.21578136073642
- 0:12.341674801377115
- 1:52.21571344448307
- 0:12.342295715934085
- 1:52.21529514309721
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76482270565064
- 1:53.19021345073392
- 0:12.763802387664429
- 1:53.18966189953399
- 0:12.762704699528312
- 1:53.187512240265576
- 0:12.756009415126538
- 1:53.17261122290122
- 0:12.629394951598373
- 1:52.88539314923722
- 0:12.50452993731056
- 1:52.59800159901114
- 0:12.37060140017968
- 1:52.284574886752665
- 0:12.366312776098997
- 1:52.274443595552334
- 0:12.341663648019583
- 1:52.21578136073642
- system:index:20190822T101031_20190822T101027_T32UQD
- system:time_start:1566468976049
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.72635632985471
- 1:53.102944150816064
- 0:12.726431085244831
- 1:53.10291535994919
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16132503150331
- 1:54.076196558271874
- 0:13.161200353300458
- 1:54.07616921587228
- 0:13.160151192824651
- 1:54.07509792362344
- 0:13.157832082726422
- 1:54.07030940579866
- 0:13.047863133663478
- 1:53.8289094598955
- 0:12.939220350744604
- 1:53.587380263242565
- 0:12.725800330737272
- 1:53.10393392448327
- 0:12.725749723518895
- 1:53.10334930722701
- 0:12.72635632985471
- 1:53.102944150816064
- system:index:20190822T101031_20190822T101027_T32UQE
- system:time_start:1566468961153
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.781217299827844
- 1:53.22903403059643
- 0:12.781141472867725
- 1:53.229019633552035
- 0:12.779502214077723
- 1:53.22573170679102
- 0:12.583389468524413
- 1:52.78006478347373
- 0:12.504776405271663
- 1:52.59877325087378
- 0:12.502427910529793
- 1:52.59332831232376
- 0:12.36567168598165
- 1:52.273099866913256
- 0:12.349506746589398
- 1:52.23442490154301
- 0:12.349503461209059
- 1:52.23440212047015
- 0:12.349583735006762
- 1:52.2330550051596
- 0:12.349627618509007
- 1:52.233026648461546
- 0:12.34963919457014
- 1:52.23298484301327
- 0:12.349999074282813
- 1:52.23288430462691
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.781271130469108
- 1:53.229064273801384
- 0:12.781217299827844
- 1:53.22903403059643
- system:index:20190822T101031_20190822T101027_T33UUU
- system:time_start:1566468975189
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.187694406707116
- 1:54.134552669564414
- 0:13.186778772259919
- 1:54.133404679089836
- 0:13.185080678452728
- 1:54.13013559027427
- 0:13.175014945132206
- 1:54.108408013009495
- 0:12.959656952008562
- 1:53.63271157727682
- 0:12.748964842552423
- 1:53.15664477488044
- 0:12.74496195004671
- 1:53.147397599110455
- 0:12.743366270582221
- 1:53.143589315980996
- 0:12.742578544162324
- 1:53.14140433374735
- 0:12.742654492549057
- 1:53.139956109647244
- 0:12.74277521244768
- 1:53.1398683173219
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20190822T101031_20190822T101027_T33UUV
- system:time_start:1566468960554
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190825T102031_20190825T102430_T32UQD
- system:time_start:1566728772923
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190825T102031_20190825T102430_T32UQE
- system:time_start:1566728758577
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190825T102031_20190825T102430_T33UUU
- system:time_start:1566728772087
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190825T102031_20190825T102430_T33UUV
- system:time_start:1566728758027
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.7674802725699
- 1:53.19012929803857
- 0:12.766435950304796
- 1:53.18902425922219
- 0:12.765345393781208
- 1:53.186888887195444
- 0:12.748568517268115
- 1:53.149100045277024
- 0:12.550063734661546
- 1:52.69513391658046
- 0:12.35584746392126
- 1:52.240742760392926
- 0:12.348327444366607
- 1:52.22260741208916
- 0:12.346164937835635
- 1:52.21726316579829
- 0:12.34601572268607
- 1:52.215279703124324
- 0:12.346122393387603
- 1:52.21518660414758
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20190827T101029_20190827T101554_T32UQD
- system:time_start:1566900978128
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.151120270485606
- 1:53.863361117804075
- 0:13.123175393135066
- 1:53.86702465338448
- 0:13.078077134834281
- 1:53.87288680000392
- 0:13.072493519565228
- 1:53.87307671695634
- 0:13.071382638791897
- 1:53.871429241456084
- 0:13.06794281437268
- 1:53.864253000253036
- 0:13.060996045610379
- 1:53.84910860585627
- 0:13.032040151984727
- 1:53.78532290319588
- 0:12.84094342217957
- 1:53.35878913612938
- 0:12.748568367537642
- 1:53.14909972767919
- 0:12.732857477765869
- 1:53.112895609743106
- 0:12.729470728458327
- 1:53.10489778136264
- 0:12.729291243089765
- 1:53.10282562519421
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.663446146729573
- 1:53.429732446158724
- 0:13.70317656906579
- 1:53.788018950059566
- 0:13.70169057777597
- 1:53.78902389841505
- 0:13.663937143615875
- 1:53.79428509352893
- 0:13.151120270485606
- 1:53.863361117804075
- system:index:20190827T101029_20190827T101554_T32UQE
- system:time_start:1566900964903
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35349767901293
- 1:52.23296649743856
- 0:12.353544372306482
- 1:52.23296393328994
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.7839117009891
- 1:53.22908418230497
- 0:12.783835983850446
- 1:53.22906977493141
- 0:12.783010905925504
- 1:53.22741536137325
- 0:12.77817991630279
- 1:53.216534861814296
- 0:12.564090355830258
- 1:52.72733653905707
- 0:12.35458142082511
- 1:52.23777882536442
- 0:12.353049444156035
- 1:52.233964709799665
- 0:12.353046117532593
- 1:52.23394209777632
- 0:12.353094257147454
- 1:52.23313380838706
- 0:12.353138065494448
- 1:52.23310554037209
- 0:12.35314974750102
- 1:52.2330637229293
- 0:12.35349767901293
- 1:52.23296649743856
- system:index:20190827T101029_20190827T101554_T33UUU
- system:time_start:1566900977267
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.630358033023583
- 1:53.7984323344444
- 0:13.628728401599506
- 1:53.79898616096589
- 0:13.220953203340036
- 1:53.85404185739476
- 0:13.07408060307529
- 1:53.87335178857289
- 0:13.072127568112391
- 1:53.87332045492064
- 0:13.071257444784974
- 1:53.87162543481076
- 0:13.061309875454688
- 1:53.84988851394212
- 0:13.033198381047226
- 1:53.78794063004625
- 0:12.933812868535506
- 1:53.56726876729724
- 0:12.874340423880232
- 1:53.434066324136495
- 0:12.840288046203597
- 1:53.35739413087897
- 0:12.808776049209097
- 1:53.28615160614493
- 0:12.746867727477005
- 1:53.14527596739001
- 0:12.745271535788477
- 1:53.14146686479962
- 0:12.745268002271656
- 1:53.141444214971926
- 0:12.745343340786802
- 1:53.140007060229685
- 0:12.745463944507522
- 1:53.13991927709296
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20190827T101029_20190827T101554_T33UUV
- system:time_start:1566900964529
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190830T102029_20190830T102552_T32UQD
- system:time_start:1567160774946
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.694623808526554
- 1:53.71745512375297
- 0:13.694603422433048
- 1:53.71750024245848
- 0:13.294333145815537
- 1:53.79947851097569
- 0:13.004024806977492
- 1:53.85271438708464
- 0:12.594119742583759
- 1:53.926145297685146
- 0:12.20765034776827
- 1:53.988896692719315
- 0:12.062711903683805
- 1:54.00994570256441
- 0:12.062648176508322
- 1:54.009948301110754
- 0:12.051454222833351
- 1:54.00752941115904
- 0:12.051420661484695
- 1:54.00749287350403
- 0:12.051355557257992
- 1:54.007469229094426
- 0:12.019436662388438
- 1:53.56566889094649
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.988464475701429
- 1:53.12375052159264
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.6593231850764
- 1:53.39210444320756
- 0:13.694757003366698
- 1:53.71273756194149
- 0:13.694672715043781
- 1:53.71742296313967
- 0:13.694623808526554
- 1:53.71745512375297
- system:index:20190830T102029_20190830T102552_T32UQE
- system:time_start:1567160762445
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190830T102029_20190830T102552_T33UUU
- system:time_start:1567160774106
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63191742422354
- 1:53.730474073372676
- 0:13.631906698283233
- 1:53.73051367840092
- 0:13.572183907636916
- 1:53.74708771115292
- 0:12.711885114582953
- 1:53.904206061088914
- 0:12.161040520383896
- 1:53.998177063018005
- 0:11.979847033165122
- 1:54.02181310322001
- 0:11.954950768376966
- 1:54.02388287792683
- 0:11.949398044113204
- 1:54.024284005673834
- 0:11.949349170224073
- 1:54.024276956747904
- 0:11.94664486538303
- 1:54.023668743307475
- 0:11.946609990258793
- 1:54.02362969634713
- 0:11.946545082923958
- 1:54.023601254270694
- 0:11.979081250407482
- 1:53.57372449633692
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010870575835755
- 1:53.123733817593966
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.63273807680673
- 1:53.72524085179593
- 0:13.631962328957501
- 1:53.73044872740099
- 0:13.63191742422354
- 1:53.730474073372676
- system:index:20190830T102029_20190830T102552_T33UUV
- system:time_start:1567160762098
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.765663843042015
- 1:53.19018684272034
- 0:12.76454385219265
- 1:53.18799358243105
- 0:12.60810270448097
- 1:52.83315520488445
- 0:12.45432320913989
- 1:52.4780540469764
- 0:12.42515749363084
- 1:52.4098258649764
- 0:12.366027024793755
- 1:52.270674167436646
- 0:12.34353476601548
- 1:52.21733822792947
- 0:12.343385643399108
- 1:52.21535435145997
- 0:12.34349220841784
- 1:52.2152612666215
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20190901T101031_20190901T101134_T32UQD
- system:time_start:1567332974305
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.162119972179344
- 1:54.076168972010606
- 0:13.16095352063542
- 1:54.073981078630965
- 0:13.158638991029164
- 1:54.06920211321264
- 0:13.14809971251251
- 1:54.04635839853262
- 0:12.939974256350068
- 1:53.58573630927771
- 0:12.736569019884225
- 1:53.12465231517685
- 0:12.729847507460718
- 1:53.10921242724581
- 0:12.727588900401054
- 1:53.1038775171143
- 0:12.727538296949442
- 1:53.103293231603466
- 0:12.728186491637366
- 1:53.102860283553746
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20190901T101031_20190901T101134_T32UQE
- system:time_start:1567332959407
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.783067440516646
- 1:53.22909773761695
- 0:12.782937777570242
- 1:53.22905309969255
- 0:12.782112942319293
- 1:53.227398824819836
- 0:12.76600210312987
- 1:53.19149200096447
- 0:12.595412836192647
- 1:52.80404775550256
- 0:12.506515783992628
- 1:52.599349462409414
- 0:12.419987907162414
- 1:52.39786043981512
- 0:12.36661408347639
- 1:52.27204177906033
- 0:12.358137605046785
- 1:52.251887862161205
- 0:12.351980250101528
- 1:52.23718076637026
- 0:12.350428885573585
- 1:52.23331761772451
- 0:12.351143026931723
- 1:52.232910039294005
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783067440516646
- 1:53.22909773761695
- system:index:20190901T101031_20190901T101134_T33UUU
- system:time_start:1567332973445
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.743555174348522
- 1:53.14028704380366
- 0:12.743579121510306
- 1:53.14026967332839
- 0:12.744195374717378
- 1:53.1399217119857
- 0:12.744273936451517
- 1:53.13989674387769
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.188707134450901
- 1:54.134567909956466
- 0:13.188651874751306
- 1:54.13453782531795
- 0:13.188574328593898
- 1:54.134523680726595
- 0:13.18686928558611
- 1:54.131241524692484
- 0:13.183504218535763
- 1:54.124177972294795
- 0:13.18098733494555
- 1:54.11874608133379
- 0:12.959799950171028
- 1:53.62974727502276
- 0:12.743536749801194
- 1:53.14035805912447
- 0:12.743565099842764
- 1:53.14032427125112
- 0:12.743555174348522
- 1:53.14028704380366
- system:index:20190901T101031_20190901T101134_T33UUV
- system:time_start:1567332958808
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190904T102021_20190904T102045_T32UQD
- system:time_start:1567592771043
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190904T102021_20190904T102045_T32UQE
- system:time_start:1567592756695
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190904T102021_20190904T102045_T33UUU
- system:time_start:1567592770207
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190904T102021_20190904T102045_T33UUV
- system:time_start:1567592756144
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.34604721835388
- 1:52.21565710864206
- 0:12.346058327905945
- 1:52.21558911370089
- 0:12.346679219677698
- 1:52.215170787336795
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76757320945312
- 1:53.19012637801493
- 0:12.76743778289539
- 1:53.19008831763625
- 0:12.76638459727116
- 1:53.188478572031215
- 0:12.76303382309006
- 1:53.181024052286894
- 0:12.758555118147768
- 1:53.17091156677555
- 0:12.549932577236781
- 1:52.69351883237025
- 0:12.34604721835388
- 1:52.21565710864206
- system:index:20190906T101029_20190906T101026_T32UQD
- system:time_start:1567764975990
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16589798332256
- 1:54.076038016493854
- 0:13.165834903032223
- 1:54.07600907724234
- 0:13.165758422727619
- 1:54.075995499665126
- 0:13.165742543049896
- 1:54.075975017855264
- 0:13.164611501588752
- 1:54.07385392309473
- 0:13.161112828009587
- 1:54.066417684638125
- 0:13.152938193410222
- 1:54.048889924039955
- 0:12.938720601646727
- 1:53.577142720422565
- 0:12.729470802071091
- 1:53.104898190424784
- 0:12.729299073625894
- 1:53.10291552257381
- 0:12.729356296922628
- 1:53.102872200009585
- 0:12.729406956332893
- 1:53.102821999336875
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- system:index:20190906T101029_20190906T101026_T32UQE
- system:time_start:1567764961109
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.353926994270395
- 1:52.23398442579291
- 0:12.353923776789278
- 1:52.233961802165275
- 0:12.353975166800112
- 1:52.2330979356567
- 0:12.354387127274883
- 1:52.2329828058287
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.784863641922332
- 1:53.22913110253703
- 0:12.784746051010995
- 1:53.229097352985605
- 0:12.783884883867907
- 1:53.227978483233905
- 0:12.783066633413522
- 1:53.22633747541894
- 0:12.758938051921744
- 1:53.17193832091349
- 0:12.563766774869302
- 1:52.72517181887501
- 0:12.372412168324978
- 1:52.278106394499815
- 0:12.355459052614957
- 1:52.237798448352905
- 0:12.353926994270395
- 1:52.23398442579291
- system:index:20190906T101029_20190906T101026_T33UUU
- system:time_start:1567764975129
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.745357557972188
- 1:53.14035793877885
- 0:12.745346774557802
- 1:53.1403176332089
- 0:12.745987975206573
- 1:53.13995568623895
- 0:12.74606653738458
- 1:53.13993071676165
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.192378551411378
- 1:54.13462310639914
- 0:13.19232328591681
- 1:54.1345930237902
- 0:13.192245734750017
- 1:54.13457888199775
- 0:13.190540368267014
- 1:54.131296779672375
- 0:13.187174600825315
- 1:54.1242333339427
- 0:13.182140686017847
- 1:54.11337000563144
- 0:12.968245669685825
- 1:53.642836892396794
- 0:12.758937901991844
- 1:53.17193800323401
- 0:12.746924134823233
- 1:53.14419790199701
- 0:12.74532890977644
- 1:53.14039109199735
- 0:12.745357557972188
- 1:53.14035793877885
- system:index:20190906T101029_20190906T101026_T33UUV
- system:time_start:1567764960514
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190909T102029_20190909T102024_T32UQD
- system:time_start:1568024772651
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190909T102029_20190909T102024_T32UQE
- system:time_start:1568024758292
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190909T102029_20190909T102024_T33UUU
- system:time_start:1568024771810
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190909T102029_20190909T102024_T33UUV
- system:time_start:1568024757741
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76746489011659
- 1:53.19012980090629
- 0:12.766385612822308
- 1:53.18847996487569
- 0:12.765298265003933
- 1:53.186350858599106
- 0:12.753042288689974
- 1:53.15921300868106
- 0:12.551234225768734
- 1:52.69860671308399
- 0:12.353849262540603
- 1:52.23756168897594
- 0:12.34741006603269
- 1:52.222093849171955
- 0:12.345247720165043
- 1:52.2167495414328
- 0:12.345141556577392
- 1:52.21533885791241
- 0:12.345536529007013
- 1:52.21520327400931
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20190911T101021_20190911T101023_T32UQD
- system:time_start:1568196972060
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.163958352415612
- 1:54.0761052864967
- 0:13.162838834156739
- 1:54.07445996238911
- 0:13.161706050076722
- 1:54.07233528968085
- 0:13.09623506033221
- 1:53.92940451276964
- 0:13.039302161507926
- 1:53.80396753825257
- 0:12.95396809877594
- 1:53.614147494157955
- 0:12.807092011867391
- 1:53.282701247528315
- 0:12.753042026509492
- 1:53.15921245282121
- 0:12.730601955832892
- 1:53.107569682887004
- 0:12.729470728458327
- 1:53.10489778136264
- 0:12.729291243089765
- 1:53.10282562519421
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20190911T101021_20190911T101023_T32UQE
- system:time_start:1568196957167
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.783841354447798
- 1:53.22907077829644
- 0:12.783826127740516
- 1:53.22905020732677
- 0:12.782196366001338
- 1:53.22578181579425
- 0:12.779780508632138
- 1:53.22034089407615
- 0:12.564045310334755
- 1:52.72814496535803
- 0:12.352953611247969
- 1:52.23558258663926
- 0:12.352203558766043
- 1:52.233405377804296
- 0:12.352232609777843
- 1:52.23337398305629
- 0:12.352223715591935
- 1:52.23333829808336
- 0:12.35224717723526
- 1:52.23332099479753
- 0:12.35285371974349
- 1:52.23297485631962
- 0:12.352930878792233
- 1:52.23295013092273
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.7839117009891
- 1:53.22908418230497
- 0:12.783841354447798
- 1:53.22907077829644
- system:index:20190911T101021_20190911T101023_T33UUU
- system:time_start:1568196971200
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.190432197536348
- 1:54.134593866401765
- 0:13.188704687009047
- 1:54.131268927870245
- 0:13.186186207849198
- 1:54.12583611593542
- 0:13.071132682334806
- 1:53.8743188758017
- 0:13.038865405360486
- 1:53.80313630340122
- 0:12.953354836558717
- 1:53.61291546945909
- 0:12.807142935329455
- 1:53.2828847839624
- 0:12.749274945738783
- 1:53.15071609112988
- 0:12.74608351689761
- 1:53.143101319176715
- 0:12.745295708004182
- 1:53.14091636433483
- 0:12.74534154763084
- 1:53.140041387094804
- 0:12.745761298331546
- 1:53.1399249663481
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20190911T101021_20190911T101023_T33UUV
- system:time_start:1568196956571
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.947172339177401
- 1:52.49335935170953
- 0:11.94720026633357
- 1:52.493324803496776
- 0:11.957508417639202
- 1:52.488190648495966
- 0:12.83577457963532
- 1:52.31991283146369
- 0:13.46459115288727
- 1:52.196290386184266
- 0:13.52835008183601
- 1:52.183591869481035
- 0:13.53107132427389
- 1:52.18403548291443
- 0:13.53116909416543
- 1:52.1840822528216
- 0:13.531981682770322
- 1:52.186237987082485
- 0:13.55694986097158
- 1:52.42956901382098
- 0:13.582276471427535
- 1:52.67287405041717
- 0:13.607968966306135
- 1:52.91616033348985
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.969795596199413
- 1:52.85434514761018
- 0:11.945616669379511
- 1:52.496649507221164
- 0:11.947172339177401
- 1:52.49335935170953
- system:index:20190914T102021_20190914T102022_T32UQD
- system:time_start:1568456768821
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190914T102021_20190914T102022_T32UQE
- system:time_start:1568456755650
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.056865760508806
- 1:52.472943521842566
- 0:12.056909776308927
- 1:52.472911661139314
- 0:12.067737981838025
- 1:52.46993507852591
- 0:12.087507750044596
- 1:52.46502590660889
- 0:12.11616188369255
- 1:52.45925212045197
- 0:12.929181134193167
- 1:52.299867342287776
- 0:13.170365681044304
- 1:52.255834104716676
- 0:13.215475507208275
- 1:52.24950797193961
- 0:13.23776282192157
- 1:52.24948291257782
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004609348085067
- 1:53.211994482054486
- 0:12.030049361315935
- 1:52.84354981296473
- 0:12.054940619752717
- 1:52.47507290531094
- 0:12.056865760508806
- 1:52.472943521842566
- system:index:20190914T102021_20190914T102022_T33UUU
- system:time_start:1568456768347
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190914T102021_20190914T102022_T33UUV
- system:time_start:1568456755101
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.771157339912396
- 1:53.19001282361873
- 0:12.771022054792494
- 1:53.18997483525667
- 0:12.769968654159955
- 1:53.18836488246438
- 0:12.590260239924314
- 1:52.778920351447695
- 0:12.528956136763114
- 1:52.637211010087086
- 0:12.379627889100519
- 1:52.28755456086411
- 0:12.351753725164492
- 1:52.22143084389196
- 0:12.349590861207597
- 1:52.21608650439993
- 0:12.349525102677145
- 1:52.21521438999514
- 0:12.349919967976357
- 1:52.21507880121461
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.771157339912396
- 1:53.19001282361873
- system:index:20190916T101029_20190916T101024_T32UQD
- system:time_start:1568628973422
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.16858235640346
- 1:54.07591558926901
- 0:13.168503045926293
- 1:54.07590528860904
- 0:13.167411617667844
- 1:54.07430136232039
- 0:13.166278560572447
- 1:54.07217665773672
- 0:12.948765076620301
- 1:53.59246208789245
- 0:12.736388712192246
- 1:53.11224512366071
- 0:12.733001399185838
- 1:53.10424729550069
- 0:12.73288396395587
- 1:53.102892888102616
- 0:12.732924403711861
- 1:53.1028623940977
- 0:12.732930042151779
- 1:53.102820078553826
- 0:12.73328069768653
- 1:53.102700461824654
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.168641764479014
- 1:54.07594282072079
- 0:13.16858235640346
- 1:54.07591558926901
- system:index:20190916T101029_20190916T101024_T32UQE
- system:time_start:1568628958543
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.788347942329697
- 1:53.22919589596413
- 0:12.78668679321568
- 1:53.22586542679502
- 0:12.771386247447726
- 1:53.19159278353634
- 0:12.764151482276992
- 1:53.175273166446246
- 0:12.642773402003096
- 1:52.899411242580086
- 0:12.584225415443477
- 1:52.76497528666943
- 0:12.528378081796099
- 1:52.63595656223481
- 0:12.379746480034468
- 1:52.28798171284044
- 0:12.358937843353425
- 1:52.2384158792569
- 0:12.357405556712958
- 1:52.23460193931534
- 0:12.357402336728974
- 1:52.234579315644936
- 0:12.357487684547298
- 1:52.23314240166912
- 0:12.357606532289704
- 1:52.23305497486679
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20190916T101029_20190916T101024_T33UUU
- system:time_start:1568628972562
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.195132098279165
- 1:54.134664473899086
- 0:13.195076828438731
- 1:54.134634392812515
- 0:13.19500482976157
- 1:54.134621243108974
- 0:13.19498913612012
- 1:54.13460072501633
- 0:13.192446178200914
- 1:54.129707118707366
- 0:13.189927221965744
- 1:54.124274334163324
- 0:12.974712505812334
- 1:53.64995873551173
- 0:12.764151332275965
- 1:53.17527284876112
- 0:12.749724818802562
- 1:53.14209070448765
- 0:12.749721244612264
- 1:53.14206797529453
- 0:12.749824640077989
- 1:53.14009188281926
- 0:12.749887755566416
- 1:53.140051563449134
- 0:12.74994523886021
- 1:53.14000409451679
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- system:index:20190916T101029_20190916T101024_T33UUV
- system:time_start:1568628957949
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190919T102019_20190919T102022_T32UQD
- system:time_start:1568888770295
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190919T102019_20190919T102022_T32UQE
- system:time_start:1568888755924
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190919T102019_20190919T102022_T33UUU
- system:time_start:1568888769446
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190919T102019_20190919T102022_T33UUV
- system:time_start:1568888755374
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35570615011581
- 1:52.21506491659587
- 0:12.355712128587966
- 1:52.21502272658689
- 0:12.356056928546968
- 1:52.21490427517713
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.776533667193602
- 1:53.189842268854285
- 0:12.77648249315502
- 1:53.189818020226106
- 0:12.77641179087453
- 1:53.189814519992794
- 0:12.775394716729348
- 1:53.18873881351944
- 0:12.566976464303124
- 1:52.71189501757281
- 0:12.36329397534457
- 1:52.23459431460849
- 0:12.357932092023342
- 1:52.221794657958
- 0:12.355768459789395
- 1:52.21645056670829
- 0:12.355666246891957
- 1:52.21509539934004
- 0:12.35570615011581
- 1:52.21506491659587
- system:index:20190921T101031_20190921T101152_T32UQD
- system:time_start:1569060973969
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.1758947456536
- 1:54.07569080652169
- 0:13.174846941971548
- 1:54.07514340262464
- 0:13.173702665328547
- 1:54.0729984638287
- 0:13.164337003963881
- 1:54.0528127364712
- 0:12.985024382411089
- 1:53.65952985390914
- 0:12.809198373983468
- 1:53.265903922613695
- 0:12.781055097327966
- 1:53.20203947133381
- 0:12.750740454925273
- 1:53.132840685175644
- 0:12.738320432000112
- 1:53.10354047952119
- 0:12.738269784187684
- 1:53.10295627337756
- 0:12.738917690626058
- 1:53.10252328670888
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20190921T101031_20190921T101152_T32UQE
- system:time_start:1569060959102
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.793752186574276
- 1:53.22929605592394
- 0:12.79286610641176
- 1:53.22814517267123
- 0:12.79123272051174
- 1:53.22487100141054
- 0:12.785585516201836
- 1:53.212357236770174
- 0:12.780755890666846
- 1:53.20147795495114
- 0:12.571092457254325
- 1:52.72127574066129
- 0:12.365832086176772
- 1:52.240728443848404
- 0:12.364299343261298
- 1:52.23691518129015
- 0:12.363545192795442
- 1:52.234727837933434
- 0:12.363631154857377
- 1:52.233279881621726
- 0:12.363749996306545
- 1:52.23319244773965
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20190921T101031_20190921T101152_T33UUU
- system:time_start:1569060973111
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.754290490405042
- 1:53.140557601716864
- 0:12.75430949635191
- 1:53.14048710356684
- 0:12.754995849830674
- 1:53.14009949614467
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.202474988719048
- 1:54.134774353559735
- 0:13.202354412690664
- 1:54.1347409667669
- 0:13.201463968063903
- 1:54.13362494532405
- 0:13.200612314709858
- 1:54.131986856828156
- 0:13.190537913142029
- 1:54.110260511490736
- 0:12.998287335838842
- 1:53.68892269640784
- 0:12.809741081616272
- 1:53.267288566865915
- 0:12.780755777954147
- 1:53.20147771662317
- 0:12.755075081765899
- 1:53.142732202599994
- 0:12.754290490405042
- 1:53.140557601716864
- system:index:20190921T101031_20190921T101152_T33UUV
- system:time_start:1569060958514
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190924T102021_20190924T102418_T32UQD
- system:time_start:1569320771883
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190924T102021_20190924T102418_T32UQE
- system:time_start:1569320757520
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190924T102021_20190924T102418_T33UUU
- system:time_start:1569320771039
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190924T102021_20190924T102418_T33UUV
- system:time_start:1569320756972
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.782744517919369
- 1:53.18961388101879
- 0:12.782664280415458
- 1:53.18959906172867
- 0:12.781567797309375
- 1:53.18745377067118
- 0:12.769254192834843
- 1:53.15977958764138
- 0:12.571144521391318
- 1:52.70853149993289
- 0:12.37729181216191
- 1:52.25686050205654
- 0:12.36015210721358
- 1:52.21632610608639
- 0:12.360049753582059
- 1:52.21497053370892
- 0:12.36008954515554
- 1:52.21494006101848
- 0:12.360095518417069
- 1:52.214897870950345
- 0:12.360440430314808
- 1:52.21477939348762
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.782805891018155
- 1:53.18964303045649
- 0:12.782744517919369
- 1:53.18961388101879
- system:index:20190926T101029_20190926T101317_T32UQD
- system:time_start:1569492973783
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.744537292299654
- 1:53.10281390209974
- 0:12.744548324217543
- 1:53.102746726723964
- 0:12.745177607698865
- 1:53.102326231312716
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.179616514613032
- 1:54.07556134587529
- 0:13.179471527459597
- 1:54.07551792520433
- 0:13.178329245794783
- 1:54.07337733869507
- 0:13.173643704121373
- 1:54.063283837760835
- 0:12.964016308966391
- 1:53.600322234883784
- 0:12.759170634998043
- 1:53.13689203692872
- 0:12.746794267020142
- 1:53.10813972080957
- 0:12.744537292299654
- 1:53.10281390209974
- system:index:20190926T101029_20190926T101317_T32UQE
- system:time_start:1569492958919
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.36841742958801
- 1:52.233300205239175
- 0:12.368464056749355
- 1:52.23329772437092
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.800132273537326
- 1:53.22941400928025
- 0:12.800078412978673
- 1:53.22938377630461
- 0:12.800002559832352
- 1:53.22936939344993
- 0:12.798361846027555
- 1:53.22608170998648
- 0:12.791110873255572
- 1:53.20976240593073
- 0:12.579210657580562
- 1:52.72710681851567
- 0:12.371785704602136
- 1:52.244099086819745
- 0:12.36793756101009
- 1:52.23483757915845
- 0:12.367934262356883
- 1:52.234814798826505
- 0:12.368014037818167
- 1:52.233467653723736
- 0:12.368057842284399
- 1:52.2334393793518
- 0:12.368069508065338
- 1:52.23339756038309
- 0:12.36841742958801
- 1:52.233300205239175
- system:index:20190926T101029_20190926T101317_T33UUU
- system:time_start:1569492972927
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.207064149388168
- 1:54.13484277343027
- 0:13.207030991672445
- 1:54.1348247100807
- 0:13.2069863851926
- 1:54.13482900300765
- 0:13.206956694120908
- 1:54.13481470177387
- 0:13.206044695980514
- 1:54.13425130647371
- 0:13.206025386567324
- 1:54.13422374209539
- 0:13.200985505078998
- 1:54.123361496683
- 0:12.980346013247646
- 1:53.63656867703458
- 0:12.764599351065247
- 1:53.14938651818298
- 0:12.761404948428424
- 1:53.14177133158123
- 0:12.761401327460781
- 1:53.14174877415874
- 0:12.761476062364789
- 1:53.140311525147276
- 0:12.761539210552943
- 1:53.14027127810665
- 0:12.761596798993509
- 1:53.14022379049045
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20190926T101029_20190926T101317_T33UUV
- system:time_start:1569492958337
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20190929T102029_20190929T102023_T32UQD
- system:time_start:1569752771543
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20190929T102029_20190929T102023_T32UQE
- system:time_start:1569752757170
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20190929T102029_20190929T102023_T33UUU
- system:time_start:1569752770696
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20190929T102029_20190929T102023_T33UUV
- system:time_start:1569752756620
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35215265847831
- 1:52.21510538984749
- 0:12.352259319809054
- 1:52.21501228500432
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.773752712888957
- 1:53.18993052850071
- 0:12.7727068661875
- 1:53.18882419354189
- 0:12.758179439938113
- 1:53.15635236888281
- 0:12.642689252445692
- 1:52.89496962809796
- 0:12.586577928344559
- 1:52.76661951690967
- 0:12.529667592808385
- 1:52.635031107758294
- 0:12.392141787498929
- 1:52.313099451590425
- 0:12.364231411104372
- 1:52.246979599728334
- 0:12.352342741952022
- 1:52.217627327116716
- 0:12.35215265847831
- 1:52.21510538984749
- system:index:20191001T101031_20191001T101058_T32UQD
- system:time_start:1569924975554
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.73471262306172
- 1:53.10305947160492
- 0:12.734734023636733
- 1:53.10304105167326
- 0:12.73529913691355
- 1:53.10266344716866
- 0:12.735373778948235
- 1:53.10263466229215
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.170470900668464
- 1:54.075879298328516
- 0:13.170406053192936
- 1:54.07584954264915
- 0:13.170322721240364
- 1:54.07583258481689
- 0:13.059419089083784
- 1:53.832835980116045
- 0:12.949870365692101
- 1:53.58972708154567
- 0:12.734700566008874
- 1:53.103124003383456
- 0:12.734726425985373
- 1:53.10309308876333
- 0:12.73471262306172
- 1:53.10305947160492
- system:index:20191001T101031_20191001T101058_T32UQE
- system:time_start:1569924960673
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.79015852330426
- 1:53.22865311457911
- 0:12.790139716206827
- 1:53.228625496825636
- 0:12.58677149120812
- 1:52.76718526025601
- 0:12.529354928547246
- 1:52.634358316828184
- 0:12.445811446440292
- 1:52.439427716896716
- 0:12.38999731292796
- 1:52.30817304308898
- 0:12.359911074175457
- 1:52.2368175194277
- 0:12.359156929473183
- 1:52.234629680411054
- 0:12.359242929924493
- 1:52.23318165886791
- 0:12.35936181141565
- 1:52.23309430858301
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.791150680901357
- 1:53.22924788026149
- 0:12.79106560942914
- 1:53.22923215576939
- 0:12.79015852330426
- 1:53.22865311457911
- system:index:20191001T101031_20191001T101058_T33UUU
- system:time_start:1569924974696
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.752022966538428
- 1:53.14004690288711
- 0:12.752070512057402
- 1:53.14004424212454
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.197885700448566
- 1:54.13470568721752
- 0:13.197798479344788
- 1:54.134690255044376
- 0:13.196858793512751
- 1:54.13410948444565
- 0:13.196000038978353
- 1:54.13245717845143
- 0:13.193480463525
- 1:54.12702453067442
- 0:12.971653055837228
- 1:53.63803993586682
- 0:12.75476630749599
- 1:53.14866195851935
- 0:12.751573793067301
- 1:53.1410465748542
- 0:12.751570141784205
- 1:53.14102393777147
- 0:12.751612480653352
- 1:53.14021558555988
- 0:12.751657027928069
- 1:53.140187129420035
- 0:12.751668576191882
- 1:53.14014523282662
- 0:12.752022966538428
- 1:53.14004690288711
- system:index:20191001T101031_20191001T101058_T33UUV
- system:time_start:1569924960080
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191004T102031_20191004T102025_T32UQD
- system:time_start:1570184773287
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191004T102031_20191004T102025_T32UQE
- system:time_start:1570184758936
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191004T102031_20191004T102025_T33UUU
- system:time_start:1570184772448
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191004T102031_20191004T102025_T33UUV
- system:time_start:1570184758386
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.3548398917003
- 1:52.215376674698035
- 0:12.354825495313301
- 1:52.2153400195199
- 0:12.355405269312582
- 1:52.21494928738571
- 0:12.35547878390611
- 1:52.21492067070585
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.776533667193602
- 1:53.189842268854285
- 0:12.776472341431822
- 1:53.18981319486815
- 0:12.776392074776957
- 1:53.18979829110462
- 0:12.775295884179094
- 1:53.187653021733134
- 0:12.761902319935986
- 1:53.15785371043964
- 0:12.55715747968872
- 1:52.689524319586894
- 0:12.35697405195404
- 1:52.22074273592606
- 0:12.354813976177777
- 1:52.21540707251841
- 0:12.3548398917003
- 1:52.215376674698035
- system:index:20191006T101029_20191006T101025_T32UQD
- system:time_start:1570356974659
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.738634715048317
- 1:53.102535735677804
- 0:12.73868179512291
- 1:53.10253070885298
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.175043666517018
- 1:54.07572041678763
- 0:13.174991211307923
- 1:54.07569630602985
- 0:13.174918998306431
- 1:54.07569317162905
- 0:13.17386907867797
- 1:54.074621461510375
- 0:12.96553058124052
- 1:53.616462910442884
- 0:12.761902132544604
- 1:53.15785331342294
- 0:12.738367193065947
- 1:53.104079069885174
- 0:12.73824960877448
- 1:53.10272433476309
- 0:12.73829000866937
- 1:53.10269375945503
- 0:12.738295640613664
- 1:53.10265144386573
- 0:12.738634715048317
- 1:53.102535735677804
- system:index:20191006T101029_20191006T101025_T32UQE
- system:time_start:1570356959792
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.362764316374774
- 1:52.233609918359214
- 0:12.36275442975186
- 1:52.23357079900345
- 0:12.363385168478946
- 1:52.23321075129476
- 0:12.363462330544499
- 1:52.23318601790734
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.793845209929541
- 1:53.229297793031286
- 0:12.793797556812747
- 1:53.22927106006364
- 0:12.793727596601604
- 1:53.229264053999664
- 0:12.79286516363486
- 1:53.228143938305884
- 0:12.790445053133036
- 1:53.22269700811228
- 0:12.582116255542688
- 1:52.74685847947242
- 0:12.3781287919295
- 1:52.27067955185826
- 0:12.365018237363929
- 1:52.23963112837022
- 0:12.363485605171462
- 1:52.235817833763974
- 0:12.362735271135678
- 1:52.233641316039055
- 0:12.362764316374774
- 1:52.233609918359214
- system:index:20191006T101029_20191006T101025_T33UUU
- system:time_start:1570356973801
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20155707068725
- 1:54.13476060723407
- 0:13.201501790707997
- 1:54.134730529700406
- 0:13.201429783891166
- 1:54.13471738454504
- 0:13.201414085039588
- 1:54.13469686749807
- 0:13.200565659219585
- 1:54.13306482852186
- 0:13.195526736614294
- 1:54.12220105737625
- 0:12.991702994377148
- 1:53.67451825763693
- 0:12.792046871070271
- 1:53.22650278814334
- 0:12.760704992761195
- 1:53.15524769209847
- 0:12.755102757458033
- 1:53.14219222895599
- 0:12.7550991793614
- 1:53.14216950000159
- 0:12.755202263438264
- 1:53.14019340633951
- 0:12.755265263500737
- 1:53.1401530960153
- 0:12.755322856291144
- 1:53.14010561183849
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20191006T101029_20191006T101025_T33UUV
- system:time_start:1570356959204
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191009T102029_20191009T102303_T32UQD
- system:time_start:1570616772228
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191009T102029_20191009T102303_T32UQE
- system:time_start:1570616757862
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191009T102029_20191009T102303_T33UUU
- system:time_start:1570616771383
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191009T102029_20191009T102303_T33UUV
- system:time_start:1570616757312
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.770923894083213
- 1:53.188890630738996
- 0:12.77090975275373
- 1:53.188869786583865
- 0:12.565639366827714
- 1:52.72272888991962
- 0:12.364925030804121
- 1:52.25613468642259
- 0:12.347800727000726
- 1:52.2156073523444
- 0:12.347826288551305
- 1:52.21557641804841
- 0:12.347811833223517
- 1:52.21553935733922
- 0:12.348391641300296
- 1:52.215148662523
- 0:12.348465191336654
- 1:52.215120129257784
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77205341171535
- 1:53.189984455111734
- 0:12.772002205964496
- 1:53.18996012467941
- 0:12.771931545216242
- 1:53.18995670075439
- 0:12.770923894083213
- 1:53.188890630738996
- system:index:20191011T101031_20191011T101027_T32UQD
- system:time_start:1570788976576
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.168522100362525
- 1:54.075946987355934
- 0:13.167354984080752
- 1:54.07375860799841
- 0:13.16267199258205
- 1:54.063664718499
- 0:13.122890114991336
- 1:53.977064854646024
- 0:13.117052999822281
- 1:53.964312286203274
- 0:13.085576059038425
- 1:53.89522707948685
- 0:12.953815733226712
- 1:53.6028189486858
- 0:12.745136819747175
- 1:53.13031906037398
- 0:12.736155114906913
- 1:53.10955397893015
- 0:12.733895684093607
- 1:53.10421924896823
- 0:12.73377339104298
- 1:53.102809400294376
- 0:12.734175019481304
- 1:53.10267232274587
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20191011T101031_20191011T101027_T32UQE
- system:time_start:1570788961691
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.356130592807508
- 1:52.233025498108056
- 0:12.356177177757813
- 1:52.23302294438185
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.789354406658127
- 1:53.22921453474213
- 0:12.789269337961034
- 1:53.229198808734495
- 0:12.788362190021376
- 1:53.22861976344325
- 0:12.788343498404663
- 1:53.2285921329763
- 0:12.574747369190044
- 1:52.74347096204568
- 0:12.365688317429761
- 1:52.257992326998
- 0:12.35874591410063
- 1:52.241649245819985
- 0:12.355682346161204
- 1:52.234023811519045
- 0:12.355678982116471
- 1:52.234001121059585
- 0:12.355727060200536
- 1:52.23319283110955
- 0:12.35577097763295
- 1:52.23316455033117
- 0:12.35578265677635
- 1:52.23312273261885
- 0:12.356130592807508
- 1:52.233025498108056
- system:index:20191011T101031_20191011T101027_T33UUU
- system:time_start:1570788975717
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.195955002636959
- 1:54.1346767410007
- 0:13.195039106754708
- 1:54.13352881572118
- 0:13.192493118836175
- 1:54.128629272572574
- 0:13.186610074832256
- 1:54.116134498670874
- 0:13.181577228889505
- 1:54.105271263008646
- 0:13.120592224643278
- 1:53.972190424838324
- 0:13.09066126230144
- 1:53.906454357395965
- 0:13.036029488525935
- 1:53.785829391132815
- 0:12.957110479643083
- 1:53.610282603372355
- 0:12.7497769685212
- 1:53.14100312402568
- 0:12.749807700564672
- 1:53.140413935591106
- 0:12.750514595526058
- 1:53.140014864968485
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20191011T101031_20191011T101027_T33UUV
- system:time_start:1570788961099
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191014T102031_20191014T102207_T32UQD
- system:time_start:1571048774181
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191014T102031_20191014T102207_T32UQE
- system:time_start:1571048759821
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191014T102031_20191014T102207_T33UUU
- system:time_start:1571048773342
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191014T102031_20191014T102207_T33UUV
- system:time_start:1571048759271
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.775575301600075
- 1:53.18987268756791
- 0:12.77455257021069
- 1:53.18932006063074
- 0:12.580016804850516
- 1:52.74631044054873
- 0:12.389602261345331
- 1:52.30291884724889
- 0:12.38101478054768
- 1:52.28265784203089
- 0:12.362783543168328
- 1:52.23946581432899
- 0:12.356341014737117
- 1:52.22399859473252
- 0:12.353097773533177
- 1:52.21598687159505
- 0:12.353032030747377
- 1:52.21511475115176
- 0:12.353426862583117
- 1:52.214979070645825
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20191016T101029_20191016T101025_T32UQD
- system:time_start:1571220975027
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.172177125052377
- 1:54.075820024866374
- 0:13.169828047611624
- 1:54.07097295513673
- 0:13.163961656221353
- 1:54.058222755062474
- 0:12.952834691667487
- 1:53.59232747168652
- 0:12.74655154294993
- 1:53.12595718870019
- 0:12.739826271484072
- 1:53.11051799997133
- 0:12.737566328178575
- 1:53.10518326948413
- 0:12.73734757961189
- 1:53.10266276004764
- 0:12.737455449369756
- 1:53.102569229117115
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20191016T101029_20191016T101025_T32UQE
- system:time_start:1571220960151
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.792946960017524
- 1:53.22928111453111
- 0:12.792861923400888
- 1:53.229265471022224
- 0:12.791947380974987
- 1:53.22868165366474
- 0:12.791121715409593
- 1:53.227026583670124
- 0:12.788704560070752
- 1:53.22158584414833
- 0:12.590975808371391
- 1:52.771586828721055
- 0:12.421968559081261
- 1:52.37901900701885
- 0:12.383261423423335
- 1:52.2880597696502
- 0:12.361666493196784
- 1:52.23685682241715
- 0:12.360912326699774
- 1:52.23466898617175
- 0:12.36099825365733
- 1:52.233220963963866
- 0:12.361117097803955
- 1:52.23313353311593
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792946960017524
- 1:53.22928111453111
- system:index:20191016T101029_20191016T101025_T33UUU
- system:time_start:1571220974168
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.753815525121068
- 1:53.14008076341404
- 0:12.75386307157694
- 1:53.140078101813764
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.199721305900828
- 1:54.1347331701791
- 0:13.1996341991672
- 1:54.13471772653277
- 0:13.198694460228305
- 1:54.13413697325252
- 0:13.196988061579555
- 1:54.13085394150673
- 0:13.191950283394196
- 1:54.1199899941256
- 0:12.972637479253246
- 1:53.63643837584386
- 0:12.758155669460228
- 1:53.15250246748015
- 0:12.754150477106599
- 1:53.14325411489704
- 0:12.75336224945472
- 1:53.141068875311774
- 0:12.753405001534972
- 1:53.140249373826045
- 0:12.753449472503858
- 1:53.14022100860806
- 0:12.753461018779772
- 1:53.140179111840965
- 0:12.753815525121068
- 1:53.14008076341404
- system:index:20191016T101029_20191016T101025_T33UUV
- system:time_start:1571220959561
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191019T102029_20191019T102031_T32UQD
- system:time_start:1571480772412
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191019T102029_20191019T102031_T32UQE
- system:time_start:1571480758052
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191019T102029_20191019T102031_T33UUU
- system:time_start:1571480771570
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191019T102029_20191019T102031_T33UUV
- system:time_start:1571480757502
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.344319274651111
- 1:52.215675575320205
- 0:12.344305001246756
- 1:52.21563890660015
- 0:12.34488482635363
- 1:52.21524823044386
- 0:12.344958376350009
- 1:52.21521969962544
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.765781079828303
- 1:53.19018312044206
- 0:12.765719619892588
- 1:53.190153972528826
- 0:12.765639481081697
- 1:53.19013904779327
- 0:12.76454385219265
- 1:53.18799358243105
- 0:12.559634682391687
- 1:52.71994121000365
- 0:12.359293314797789
- 1:52.251438091388664
- 0:12.345372827353712
- 1:52.21837409513201
- 0:12.344293462484721
- 1:52.21570595916048
- 0:12.344319274651111
- 1:52.215675575320205
- system:index:20191021T101041_20191021T101549_T32UQD
- system:time_start:1571652977069
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.65047562818741
- 1:53.31106829306764
- 0:13.67676159810121
- 1:53.55067652564074
- 0:13.703428415109576
- 1:53.79026608985177
- 0:13.730487840400786
- 1:54.0298738791867
- 0:13.72985040787125
- 1:54.03030293541645
- 0:13.726213748234114
- 1:54.030993061943015
- 0:13.704540602215108
- 1:54.03400478797733
- 0:13.478593155138961
- 1:54.06478237594763
- 0:13.163973987158545
- 1:54.07610473335661
- 0:13.162894452198907
- 1:54.07500232257308
- 0:12.993756626183457
- 1:53.7037632960851
- 0:12.827735026591352
- 1:53.332230102864486
- 0:12.798379307295376
- 1:53.26570972504389
- 0:12.744377949634918
- 1:53.14221589958748
- 0:12.72752594158379
- 1:53.10330157766308
- 0:12.728186491637366
- 1:53.102860283553746
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20191021T101041_20191021T101549_T32UQE
- system:time_start:1571652962224
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.352260437684798
- 1:52.2330858288843
- 0:12.352272120645715
- 1:52.233044011531376
- 0:12.352632005037993
- 1:52.23294346381509
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783067440516646
- 1:53.22909773761695
- 0:12.783019802521324
- 1:53.22907099947731
- 0:12.782949854089134
- 1:53.22906398596202
- 0:12.782088729145473
- 1:53.22794502069499
- 0:12.781270509686664
- 1:53.226304089034706
- 0:12.771612463533588
- 1:53.20454399175688
- 0:12.562773951282843
- 1:52.72703967867012
- 0:12.35829778260013
- 1:52.249193690330756
- 0:12.352139670901556
- 1:52.23448408392291
- 0:12.352136383625094
- 1:52.23446130295566
- 0:12.352216629109822
- 1:52.23311409652528
- 0:12.352260437684798
- 1:52.2330858288843
- system:index:20191021T101041_20191021T101549_T33UUU
- system:time_start:1571652976208
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.62228069728497
- 1:54.04444030515152
- 0:13.621594589017253
- 1:54.04482867617352
- 0:13.619707319858685
- 1:54.045357233669876
- 0:13.432686900195254
- 1:54.07111263673957
- 0:13.389358763914398
- 1:54.07701226748164
- 0:13.323885661997364
- 1:54.085825924350715
- 0:13.235323404901086
- 1:54.09750365611578
- 0:13.179012202087302
- 1:54.104757388929755
- 0:13.177055156185558
- 1:54.10472776429662
- 0:13.175300787667423
- 1:54.10194404638458
- 0:13.165245408162695
- 1:54.08021308397582
- 0:12.851492674464565
- 1:53.38586784228039
- 0:12.828008498229739
- 1:53.332896152898336
- 0:12.798953561121087
- 1:53.26708968710006
- 0:12.743514244477765
- 1:53.140306257657144
- 0:12.744240780465814
- 1:53.13989608693616
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.636815958007146
- 1:53.599076116289304
- 0:13.62228069728497
- 1:54.04444030515152
- system:index:20191021T101041_20191021T101549_T33UUV
- system:time_start:1571652961954
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191024T102111_20191024T102420_T32UQD
- system:time_start:1571912774480
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191024T102111_20191024T102420_T32UQE
- system:time_start:1571912760119
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191024T102111_20191024T102420_T33UUU
- system:time_start:1571912773641
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191024T102111_20191024T102420_T33UUV
- system:time_start:1571912759569
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77463338723428
- 1:53.189902561767724
- 0:12.773552727497496
- 1:53.188251330262496
- 0:12.748950880103308
- 1:53.132897696722175
- 0:12.590083222007213
- 1:52.77137038896955
- 0:12.43396235084398
- 1:52.40957023026475
- 0:12.376969953556705
- 1:52.27575799353317
- 0:12.352302205745223
- 1:52.21708924615902
- 0:12.35215265847831
- 1:52.21510538984749
- 0:12.352259319809054
- 1:52.21501228500432
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20191026T101029_20191026T101554_T32UQD
- system:time_start:1572084974791
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.650373211657415
- 1:53.31012758293638
- 0:13.676557830455526
- 1:53.54883236342029
- 0:13.675922907281437
- 1:53.54926373205653
- 0:13.655352620693028
- 1:53.55223223655831
- 0:13.617849413941297
- 1:53.55746816055626
- 0:13.09172624136159
- 1:53.62901015427824
- 0:13.008322005597487
- 1:53.639932109223906
- 0:12.985890845575929
- 1:53.642841131979765
- 0:12.97959192187815
- 1:53.643591698629315
- 0:12.976755475863133
- 1:53.64368612688021
- 0:12.975654561572581
- 1:53.6420370648006
- 0:12.956177071052014
- 1:53.598963168201514
- 0:12.74448085837429
- 1:53.12278413415796
- 0:12.73657855057869
- 1:53.104134983053996
- 0:12.7364562157422
- 1:53.10272505016687
- 0:12.736857769432548
- 1:53.10258805406959
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20191026T101029_20191026T101554_T32UQE
- system:time_start:1572084963325
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.791940561638654
- 1:53.229262499003376
- 0:12.790279167199605
- 1:53.22593224004523
- 0:12.784632130556739
- 1:53.21341849668651
- 0:12.747657806642291
- 1:53.130186429263404
- 0:12.602734369419235
- 1:52.8004193269024
- 0:12.514603214720808
- 1:52.597361398535746
- 0:12.430371250516183
- 1:52.401324080943795
- 0:12.373864291874707
- 1:52.26842631333329
- 0:12.360006621980228
- 1:52.235199939530574
- 0:12.360003329020147
- 1:52.23517715869828
- 0:12.36012053155227
- 1:52.23320132106966
- 0:12.360239521921093
- 1:52.2331139581266
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20191026T101029_20191026T101554_T33UUU
- system:time_start:1572084973932
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.638219683530991
- 1:53.554172715653
- 0:13.63821463772857
- 1:53.554212165230794
- 0:13.636639605702305
- 1:53.55475078123883
- 0:13.615687166439153
- 1:53.55774957402547
- 0:13.097075265937264
- 1:53.62829489698785
- 0:13.05690505861419
- 1:53.63358284209252
- 0:12.979265021062616
- 1:53.64362725013445
- 0:12.976525410073304
- 1:53.643580959527085
- 0:12.976470902527604
- 1:53.643550721602054
- 0:12.976394260368751
- 1:53.64353645413791
- 0:12.975554164012475
- 1:53.64188333453322
- 0:12.955870722611015
- 1:53.598394519481566
- 0:12.752499503337852
- 1:53.14052766455607
- 0:12.75252777173321
- 1:53.14049396598934
- 0:12.752517017953336
- 1:53.1404532397571
- 0:12.753158085866042
- 1:53.14009126084125
- 0:12.753236649817087
- 1:53.140066285886796
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.638260832954172
- 1:53.554146072661865
- 0:13.638219683530991
- 1:53.554172715653
- system:index:20191026T101029_20191026T101554_T33UUV
- system:time_start:1572084962873
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191029T102039_20191029T102520_T32UQD
- system:time_start:1572344772016
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191029T102039_20191029T102520_T32UQE
- system:time_start:1572344757658
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191029T102039_20191029T102520_T33UUU
- system:time_start:1572344771174
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191029T102039_20191029T102520_T33UUV
- system:time_start:1572344757108
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.765663843042015
- 1:53.19018684272034
- 0:12.76454385219265
- 1:53.18799358243105
- 0:12.743295655840146
- 1:53.14009164347715
- 0:12.544934682890053
- 1:52.68665294719252
- 0:12.350852458615421
- 1:52.23278997059129
- 0:12.346573774794136
- 1:52.222657414781274
- 0:12.344411376198115
- 1:52.21731289682122
- 0:12.344262303392304
- 1:52.21532950632163
- 0:12.34436897677078
- 1:52.21523640902108
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20191031T101141_20191031T101411_T32UQD
- system:time_start:1572516976994
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.163034499165272
- 1:54.07613731268385
- 0:13.161867935974444
- 1:54.073949351728146
- 0:13.15955348627767
- 1:54.069170639411226
- 0:13.156056710875813
- 1:54.06173522473754
- 0:13.123307854281437
- 1:53.99054322588287
- 0:13.09532354465726
- 1:53.929435702070506
- 0:13.037277460677519
- 1:53.80187710363784
- 0:12.947433509047029
- 1:53.60249036610059
- 0:12.861813063447855
- 1:53.40992446298349
- 0:12.828923421840182
- 1:53.335429875346456
- 0:12.743295356563246
- 1:53.140091008341976
- 0:12.732009326161734
- 1:53.11346118621465
- 0:12.728576358601472
- 1:53.104925301281035
- 0:12.728396966000375
- 1:53.10285372153078
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.163034499165272
- 1:54.07613731268385
- system:index:20191031T101141_20191031T101411_T32UQE
- system:time_start:1572516962102
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.782943261642453
- 1:53.22905409075062
- 0:12.782928035661886
- 1:53.22903351963882
- 0:12.778041122072318
- 1:53.21923119978966
- 0:12.774812035446239
- 1:53.212156649258354
- 0:12.772398259890272
- 1:53.20671654810935
- 0:12.559584615203153
- 1:52.72049988469913
- 0:12.351294153319072
- 1:52.233925525381395
- 0:12.3512908311449
- 1:52.23390266601697
- 0:12.351322963869144
- 1:52.233363831776245
- 0:12.351348793746146
- 1:52.23331310677836
- 0:12.35197609864331
- 1:52.23295514231432
- 0:12.352053257440266
- 1:52.23293041758327
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783067440516646
- 1:53.22909773761695
- 0:12.78301360702536
- 1:53.22906749538586
- 0:12.782943261642453
- 1:53.22905409075062
- system:index:20191031T101141_20191031T101411_T33UUU
- system:time_start:1572516976134
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.74353529375007
- 1:53.140354211436815
- 0:12.74355428241403
- 1:53.140283635604376
- 0:12.744240780465814
- 1:53.13989608693616
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.190479136135586
- 1:54.134594569107264
- 0:13.189516079933705
- 1:54.13399925279874
- 0:13.186963295660915
- 1:54.12908531979687
- 0:13.181928369933994
- 1:54.11822102328731
- 0:13.124243188749737
- 1:53.99274347339701
- 0:13.03628504081985
- 1:53.79985775131829
- 0:12.946679458098966
- 1:53.60093406451721
- 0:12.830408557856662
- 1:53.33887362399308
- 0:12.802162226450898
- 1:53.27470128853017
- 0:12.74431919059413
- 1:53.14252889253204
- 0:12.74353529375007
- 1:53.140354211436815
- system:index:20191031T101141_20191031T101411_T33UUV
- system:time_start:1572516961505
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191103T102211_20191103T102205_T32UQD
- system:time_start:1572776774198
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191103T102211_20191103T102205_T32UQE
- system:time_start:1572776759840
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191103T102211_20191103T102205_T33UUU
- system:time_start:1572776773361
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191103T102211_20191103T102205_T33UUV
- system:time_start:1572776759290
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.350145061860315
- 1:52.21509887809658
- 0:12.350218576410407
- 1:52.21507026508467
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.771157339912396
- 1:53.19001282361873
- 0:12.771013014193326
- 1:53.18996579641584
- 0:12.628777390414271
- 1:52.86733306236175
- 0:12.43236870813988
- 1:52.4117751980542
- 0:12.379627889100519
- 1:52.28755456086411
- 0:12.351753725164492
- 1:52.22143084389196
- 0:12.349590861207597
- 1:52.21608650439993
- 0:12.349546843053414
- 1:52.21550198558227
- 0:12.350145061860315
- 1:52.21509887809658
- system:index:20191105T101119_20191105T101115_T32UQD
- system:time_start:1572948973914
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.168576959408352
- 1:54.07591314402574
- 0:13.168493825917487
- 1:54.07589633207722
- 0:13.163801889971689
- 1:54.065784371020435
- 0:12.946956648528271
- 1:53.58766459609006
- 0:12.735213990865672
- 1:53.109043996353314
- 0:12.732954688480053
- 1:53.103709120796736
- 0:12.732907224287603
- 1:53.10316202386025
- 0:12.732926164761778
- 1:53.10311009100364
- 0:12.733510555239315
- 1:53.10271964560424
- 0:12.733585310409913
- 1:53.10269084971297
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.168641764479014
- 1:54.07594282072079
- 0:13.168576959408352
- 1:54.07591314402574
- system:index:20191105T101119_20191105T101115_T32UQE
- system:time_start:1572948959034
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.789292117208811
- 1:53.22921337629161
- 0:12.78835482393978
- 1:53.22861505001251
- 0:12.78752929816688
- 1:53.226960040218444
- 0:12.777054074146841
- 1:53.20356691078153
- 0:12.659454988224168
- 1:52.9375060590723
- 0:12.626120026965712
- 1:52.86131432531832
- 0:12.591328692121058
- 1:52.78130525891114
- 0:12.43317546537686
- 1:52.41379483150196
- 0:12.379746480034468
- 1:52.28798171284044
- 0:12.35740562779772
- 1:52.23460209640069
- 0:12.357402336728974
- 1:52.234579315644936
- 0:12.357487684547298
- 1:52.23314240166912
- 0:12.357606532289704
- 1:52.23305497486679
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20191105T101119_20191105T101115_T33UUU
- system:time_start:1572948973055
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.195972153591292
- 1:54.13466441864517
- 0:13.195942354079754
- 1:54.13465012719248
- 0:13.19503247061696
- 1:54.134087784588175
- 0:13.195012557917908
- 1:54.134061725637956
- 0:13.193316976743157
- 1:54.13079889032342
- 0:13.185763114053893
- 1:54.11450336247877
- 0:12.966134131911021
- 1:53.63012485077419
- 0:12.751349557032977
- 1:53.14536065836532
- 0:12.749752989607625
- 1:53.141551608532744
- 0:12.74974949027764
- 1:53.14152903829271
- 0:12.749824640077989
- 1:53.14009188281926
- 0:12.74994523886021
- 1:53.14000409451679
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19604990286127
- 1:54.13467819748574
- 0:13.195972153591292
- 1:54.13466441864517
- system:index:20191105T101119_20191105T101115_T33UUV
- system:time_start:1572948958440
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191108T102139_20191108T102508_T32UQD
- system:time_start:1573208770932
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191108T102139_20191108T102508_T32UQE
- system:time_start:1573208756571
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191108T102139_20191108T102508_T33UUU
- system:time_start:1573208770089
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191108T102139_20191108T102508_T33UUV
- system:time_start:1573208756021
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.768469211051766
- 1:53.190097961472695
- 0:12.768382291955183
- 1:53.190086615109344
- 0:12.76738495999646
- 1:53.18954762499355
- 0:12.76515609519147
- 1:53.18473512865757
- 0:12.751770913502758
- 1:53.154935655565815
- 0:12.552339288719095
- 1:52.7012720003849
- 0:12.35721297908212
- 1:52.247180046564694
- 0:12.351851176963034
- 1:52.23438009121014
- 0:12.344293462484721
- 1:52.21570595916048
- 0:12.344305001246756
- 1:52.21563890660015
- 0:12.344925792435054
- 1:52.2152206018519
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.768469211051766
- 1:53.190097961472695
- system:index:20191110T101241_20191110T101236_T32UQD
- system:time_start:1573380976254
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.164068809945578
- 1:54.076101470931754
- 0:13.163944125837071
- 1:54.07607413194085
- 0:13.162894452198907
- 1:54.07500232257308
- 0:13.13006396912119
- 1:54.00326381738208
- 0:13.103183666989938
- 1:53.944278623023074
- 0:12.925753430828458
- 1:53.54977552770231
- 0:12.751770688821232
- 1:53.15493517913916
- 0:12.730462060774714
- 1:53.10595507770761
- 0:12.72931477519476
- 1:53.10324519606772
- 0:12.729974974409227
- 1:53.10280417836021
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164068809945578
- 1:54.076101470931754
- system:index:20191110T101241_20191110T101236_T32UQE
- system:time_start:1573380961355
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.784863641922332
- 1:53.22913110253703
- 0:12.784816114971456
- 1:53.22910435290231
- 0:12.784751687922691
- 1:53.22909790952081
- 0:12.784731801349606
- 1:53.22907884839793
- 0:12.783884167901117
- 1:53.2279774748351
- 0:12.780650764812258
- 1:53.22089693365933
- 0:12.567190841701978
- 1:52.73549311424435
- 0:12.358265865170663
- 1:52.249732717995016
- 0:12.353639549619936
- 1:52.23883685920891
- 0:12.352107586890662
- 1:52.23502275837937
- 0:12.352104260903175
- 1:52.235000145958445
- 0:12.352221914697827
- 1:52.23302431242628
- 0:12.352284071614845
- 1:52.23298422228978
- 0:12.352340877596395
- 1:52.2329368800548
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- system:index:20191110T101241_20191110T101236_T33UUU
- system:time_start:1573380975394
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.190432197536348
- 1:54.134593866401765
- 0:13.188704687009047
- 1:54.131268927870245
- 0:13.186186207849198
- 1:54.12583611593542
- 0:13.164400107126927
- 1:54.07858202877165
- 0:13.130162765326881
- 1:54.00362288936237
- 0:13.105187612924393
- 1:53.9487554494165
- 0:13.009227595862699
- 1:53.73630234957218
- 0:12.747735854266239
- 1:53.14583177947422
- 0:12.746139676680071
- 1:53.14202273079013
- 0:12.746136066706297
- 1:53.14200017251614
- 0:12.74623951911743
- 1:53.14002401374648
- 0:12.746360272488303
- 1:53.139936296674904
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20191110T101241_20191110T101236_T33UUV
- system:time_start:1573380960759
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191113T102301_20191113T102419_T32UQD
- system:time_start:1573640773300
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191113T102301_20191113T102419_T32UQE
- system:time_start:1573640758948
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191113T102301_20191113T102419_T33UUU
- system:time_start:1573640772463
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191113T102301_20191113T102419_T33UUV
- system:time_start:1573640758397
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.351319961306558
- 1:52.21544301950192
- 0:12.351341086328869
- 1:52.21542465103492
- 0:12.351898480364321
- 1:52.21504898478459
- 0:12.351972030439846
- 1:52.215020449072554
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.772949454149359
- 1:53.1899559993205
- 0:12.772886435916584
- 1:53.18992610553391
- 0:12.772805123013438
- 1:53.18990897474915
- 0:12.759357218826228
- 1:53.159553004742826
- 0:12.553017425981766
- 1:52.687759782697825
- 0:12.351307589759621
- 1:52.215507693392894
- 0:12.351333149124478
- 1:52.21547675832635
- 0:12.351319961306558
- 1:52.21544301950192
- system:index:20191115T101209_20191115T101203_T32UQD
- system:time_start:1573812972437
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.17138550046946
- 1:54.07584756508845
- 0:13.17124677475469
- 1:54.075810036791545
- 0:13.170155180913216
- 1:54.07420614457563
- 0:13.169022069965628
- 1:54.07208154398487
- 0:13.133881672462213
- 1:53.99557648798559
- 0:12.985435650306476
- 1:53.66869085721073
- 0:12.83939353409902
- 1:53.34156923626932
- 0:12.73695605713985
- 1:53.108449560666884
- 0:12.734680602046184
- 1:53.10307679191295
- 0:12.73534065656124
- 1:53.1026357543057
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.17138550046946
- 1:54.07584756508845
- system:index:20191115T101209_20191115T101203_T32UQE
- system:time_start:1573812957565
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.359244686689928
- 1:52.233495655319146
- 0:12.359268256678773
- 1:52.23347833879072
- 0:12.359874709126922
- 1:52.233132248974556
- 0:12.359951870187796
- 1:52.23310751825068
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790252576440476
- 1:53.229231165558666
- 0:12.790198731550948
- 1:53.22920092722376
- 0:12.790128414523867
- 1:53.22918760707141
- 0:12.79011318272951
- 1:53.22916703709699
- 0:12.788482902528463
- 1:53.22589873011103
- 0:12.781235699218133
- 1:53.20957878592501
- 0:12.568339819667019
- 1:52.72283783974762
- 0:12.359975008413018
- 1:52.235739899401494
- 0:12.35922468730112
- 1:52.23356280318689
- 0:12.359253698918204
- 1:52.233531327943524
- 0:12.359244686689928
- 1:52.233495655319146
- system:index:20191115T101209_20191115T101203_T33UUU
- system:time_start:1573812971578
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19873982544178
- 1:54.134718522558515
- 0:13.197776641414855
- 1:54.13412327307909
- 0:13.19607019616706
- 1:54.13084015743138
- 0:13.18096680830653
- 1:54.09825050870169
- 0:13.133317635421594
- 1:53.9945028148364
- 0:12.960579891722945
- 1:53.613578384177124
- 0:12.842525349951849
- 1:53.34880344607249
- 0:12.757146814309317
- 1:53.15464134581034
- 0:12.753142348319518
- 1:53.1453944475511
- 0:12.75154557745499
- 1:53.14158550805888
- 0:12.751542076833175
- 1:53.14156293789693
- 0:12.751617113714017
- 1:53.14012570274559
- 0:12.751737747953547
- 1:53.14003799176532
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20191115T101209_20191115T101203_T33UUV
- system:time_start:1573812956975
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191118T102219_20191118T102220_T32UQD
- system:time_start:1574072769255
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191118T102219_20191118T102220_T32UQE
- system:time_start:1574072754893
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191118T102219_20191118T102220_T33UUU
- system:time_start:1574072768414
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191118T102219_20191118T102220_T33UUV
- system:time_start:1574072754342
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.766677065088482
- 1:53.19015471959899
- 0:12.766590148338272
- 1:53.19014337168467
- 0:12.765592224150264
- 1:53.18960401508263
- 0:12.74099047318709
- 1:53.13422779205613
- 0:12.73652240218921
- 1:53.12411430756755
- 0:12.677516963255918
- 1:52.98995725254346
- 0:12.517438937544904
- 1:52.620824161129846
- 0:12.360170753556542
- 1:52.2514131087463
- 0:12.345170495938847
- 1:52.21568189106539
- 0:12.345181678140396
- 1:52.215614053208206
- 0:12.345802574470953
- 1:52.215195731838925
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.766677065088482
- 1:53.19015471959899
- system:index:20191120T101321_20191120T101408_T32UQD
- system:time_start:1574244974882
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164863771418377
- 1:54.07607386356239
- 0:13.163696945429223
- 1:54.07388568726738
- 0:13.149713083955604
- 1:54.044144128123264
- 0:12.940753217194287
- 1:53.584361526979585
- 0:12.736522177932356
- 1:53.12411383130324
- 0:12.729753522637624
- 1:53.10813432314484
- 0:12.72857628714447
- 1:53.104924391530886
- 0:12.728404756704116
- 1:53.102943539710424
- 0:12.728512678183954
- 1:53.10285009668612
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20191120T101321_20191120T101408_T32UQE
- system:time_start:1574244960000
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.353138065494448
- 1:52.23310554037209
- 0:12.35314974750102
- 1:52.2330637229293
- 0:12.353509633452662
- 1:52.23296317210305
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.783880475534737
- 1:53.22909869349528
- 0:12.782964644785306
- 1:53.22851404252896
- 0:12.77085489329302
- 1:53.20183276259893
- 0:12.73713182699386
- 1:53.125670968503606
- 0:12.678005021416766
- 1:52.99127955047216
- 0:12.518465632136744
- 1:52.62307015645537
- 0:12.361489550879856
- 1:52.25466073213321
- 0:12.353799216329152
- 1:52.23614089616545
- 0:12.35304546428226
- 1:52.233953114391326
- 0:12.353094257147454
- 1:52.23313380838706
- 0:12.353138065494448
- 1:52.23310554037209
- system:index:20191120T101321_20191120T101408_T33UUU
- system:time_start:1574244974022
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.191460789016157
- 1:54.13460934995664
- 0:13.191404387985754
- 1:54.13457871611421
- 0:13.191331642964622
- 1:54.134564292871694
- 0:13.19131673274456
- 1:54.134543602671805
- 0:13.17786136071474
- 1:54.106294092997715
- 0:12.96977483161745
- 1:53.648796324778424
- 0:12.766029982992396
- 1:53.190952716754204
- 0:12.745971363535961
- 1:53.14525894191678
- 0:12.744375292291217
- 1:53.141449823864455
- 0:12.744371683614062
- 1:53.14142726568073
- 0:12.744447059872936
- 1:53.13999011108546
- 0:12.744510177556467
- 1:53.13994979497167
- 0:12.744567664581254
- 1:53.13990232898189
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- system:index:20191120T101321_20191120T101408_T33UUV
- system:time_start:1574244959403
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191123T102341_20191123T102417_T32UQD
- system:time_start:1574504771741
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191123T102341_20191123T102417_T32UQE
- system:time_start:1574504757380
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191123T102341_20191123T102417_T33UUU
- system:time_start:1574504770901
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191123T102341_20191123T102417_T33UUV
- system:time_start:1574504756830
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191128T102259_20191128T102255_T32UQD
- system:time_start:1574936766934
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191128T102259_20191128T102255_T32UQE
- system:time_start:1574936752562
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191128T102259_20191128T102255_T33UUU
- system:time_start:1574936766089
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191128T102259_20191128T102255_T33UUV
- system:time_start:1574936752012
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.769248017284418
- 1:53.19007334290295
- 0:12.768127933384847
- 1:53.187880277262465
- 0:12.761430669955187
- 1:53.172979576815415
- 0:12.650203781277101
- 1:52.9206429042935
- 0:12.61929133168174
- 1:52.849813760631875
- 0:12.587375426139227
- 1:52.77630935112495
- 0:12.526041224041167
- 1:52.634059770244335
- 0:12.49770520537784
- 1:52.5679821270823
- 0:12.360559208334779
- 1:52.24492559007767
- 0:12.348658115612404
- 1:52.21553489740746
- 0:12.349309421675445
- 1:52.21509613223508
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20191130T101401_20191130T101406_T32UQD
- system:time_start:1575108972895
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.731135708397183
- 1:53.10291848412278
- 0:12.731141499421486
- 1:53.102876235684505
- 0:12.731492117040062
- 1:53.10275654552164
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.167727071677572
- 1:54.0759745426715
- 0:13.167638124476865
- 1:54.075963451663135
- 0:13.166647552683557
- 1:54.075445826581095
- 0:13.166608891203975
- 1:54.07541789578743
- 0:13.163103194029171
- 1:54.06796766083715
- 0:12.945725759236506
- 1:53.58905451238475
- 0:12.733471898200193
- 1:53.10963840850868
- 0:12.731212778195252
- 1:53.10430345671089
- 0:12.731095418227554
- 1:53.10294904456808
- 0:12.731135708397183
- 1:53.10291848412278
- system:index:20191130T101401_20191130T101406_T32UQE
- system:time_start:1575108958013
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.78660619782882
- 1:53.229134262507095
- 0:12.78653036338455
- 1:53.229119869516154
- 0:12.784890688801262
- 1:53.22583201223663
- 0:12.702280373751915
- 1:53.03922604622323
- 0:12.616409883186256
- 1:52.84331595279118
- 0:12.528195736383116
- 1:52.6391898906334
- 0:12.496884834064176
- 1:52.566234226100796
- 0:12.359559685071147
- 1:52.24274646783524
- 0:12.356495931288176
- 1:52.23512117618806
- 0:12.356492602160113
- 1:52.235098563944774
- 0:12.356610115027298
- 1:52.23312271648747
- 0:12.35672896366825
- 1:52.23303529069652
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.786660037019558
- 1:53.229164502790226
- 0:12.78660619782882
- 1:53.229134262507095
- system:index:20191130T101401_20191130T101406_T33UUU
- system:time_start:1575108972036
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.194214264617418
- 1:54.134650661851175
- 0:13.194181119072345
- 1:54.13463259423957
- 0:13.194136400681664
- 1:54.13463689464847
- 0:13.194106719778988
- 1:54.134622589609684
- 0:13.193196770590385
- 1:54.13406024327819
- 0:13.19317685978163
- 1:54.13403418394897
- 0:13.19232877999553
- 1:54.13240201448527
- 0:12.971692670334045
- 1:53.646671160638924
- 0:12.755940904563245
- 1:53.16055276910153
- 0:12.747932245178442
- 1:53.142056773173984
- 0:12.747928672290211
- 1:53.142034043901376
- 0:12.748032058324812
- 1:53.14005796412216
- 0:12.748095174545098
- 1:53.140017645837496
- 0:12.748152772304147
- 1:53.1399701655918
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20191130T101401_20191130T101406_T33UUV
- system:time_start:1575108957417
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191203T102401_20191203T102415_T32UQD
- system:time_start:1575368769546
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191203T102401_20191203T102415_T32UQE
- system:time_start:1575368755185
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191203T102401_20191203T102415_T33UUU
- system:time_start:1575368768707
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191203T102401_20191203T102415_T33UUV
- system:time_start:1575368754636
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.77737185733962
- 1:53.1897864147228
- 0:12.777294335285337
- 1:53.18977580637917
- 0:12.776240782998906
- 1:53.188166155594125
- 0:12.772888335271853
- 1:53.180711942873145
- 0:12.56233313939834
- 1:52.69854307630059
- 0:12.35660463260314
- 1:52.21588746633128
- 0:12.35656330887178
- 1:52.215339686033566
- 0:12.356582264932339
- 1:52.21528780785391
- 0:12.357158678421357
- 1:52.2148993146211
- 0:12.357232228554231
- 1:52.214870775238836
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.777429674574151
- 1:53.189813865581186
- 0:12.77737185733962
- 1:53.1897864147228
- system:index:20191205T101309_20191205T101308_T32UQD
- system:time_start:1575540967752
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.176809275791
- 1:54.075659038276775
- 0:13.175759059066978
- 1:54.07511030263273
- 0:13.041215853682175
- 1:53.78123569873968
- 0:12.908652663608866
- 1:53.48719321682465
- 0:12.848456351093727
- 1:53.352070610516165
- 0:12.792016185279495
- 1:53.22435729433131
- 0:12.750458895641373
- 1:53.12961169831109
- 0:12.742603149923868
- 1:53.11150987601767
- 0:12.739214751061578
- 1:53.10351238696996
- 0:12.739139038362435
- 1:53.102640721225434
- 0:12.739540555666961
- 1:53.10250363560193
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20191205T101309_20191205T101308_T32UQE
- system:time_start:1575540952894
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.364547216350426
- 1:52.23336095013573
- 0:12.364558885949492
- 1:52.23331913152577
- 0:12.364918682368257
- 1:52.233218551919876
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.794743319258213
- 1:53.229314396484966
- 0:12.794695664881592
- 1:53.2292876639484
- 0:12.794625703689277
- 1:53.22928065850543
- 0:12.793764287175392
- 1:53.22816177283815
- 0:12.792945599682609
- 1:53.226520918350744
- 0:12.790528311282058
- 1:53.22108016208596
- 0:12.575954242045142
- 1:52.72973777597255
- 0:12.365991714567754
- 1:52.238034123751525
- 0:12.364458798569368
- 1:52.234220216566385
- 0:12.364455573562978
- 1:52.23419759335419
- 0:12.364503446531426
- 1:52.233389301550325
- 0:12.364547216350426
- 1:52.23336095013573
- system:index:20191205T101309_20191205T101308_T33UUU
- system:time_start:1575540966894
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.203282059813777
- 1:54.13478638665922
- 0:13.20155357288723
- 1:54.1314616196787
- 0:13.199033408592863
- 1:54.12602906520657
- 0:12.908749105679059
- 1:53.48753788430042
- 0:12.864850266823614
- 1:53.389123779133186
- 0:12.81066748042797
- 1:53.266766113697415
- 0:12.790528236049514
- 1:53.2210800031665
- 0:12.760004836866225
- 1:53.151458312813965
- 0:12.755999029507478
- 1:53.14220918720749
- 0:12.755995413312323
- 1:53.142186378904064
- 0:12.756098445495471
- 1:53.14021028504698
- 0:12.756219188036157
- 1:53.14012255659633
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20191205T101309_20191205T101308_T33UUV
- system:time_start:1575540952308
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191208T102319_20191208T102419_T32UQD
- system:time_start:1575800765361
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191208T102319_20191208T102419_T32UQE
- system:time_start:1575800750994
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191208T102319_20191208T102419_T33UUU
- system:time_start:1575800764517
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191208T102319_20191208T102419_T33UUV
- system:time_start:1575800750444
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.355405269312582
- 1:52.21494928738571
- 0:12.35547878390611
- 1:52.21492067070585
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.775637592103482
- 1:53.18987075604691
- 0:12.775550626078232
- 1:53.189859336455676
- 0:12.774554796276274
- 1:53.18932123827738
- 0:12.77345658313888
- 1:53.18717160407083
- 0:12.748857084370458
- 1:53.13182126449434
- 0:12.550240026040779
- 1:52.67543064285141
- 0:12.355934645880115
- 1:52.21861359082869
- 0:12.354851189492596
- 1:52.21593693694157
- 0:12.354807076877101
- 1:52.215352423748556
- 0:12.355405269312582
- 1:52.21494928738571
- system:index:20191210T101411_20191210T101409_T32UQD
- system:time_start:1575972970254
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.73734757961189
- 1:53.10266276004764
- 0:12.737455449369756
- 1:53.102569229117115
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.174948990239312
- 1:54.075723756475924
- 0:13.173869589068088
- 1:54.074621996868174
- 0:13.171549080450475
- 1:54.069834012100166
- 0:13.16805014852118
- 1:54.06239896612693
- 0:12.988153548288578
- 1:53.668600342320985
- 0:12.81176041168457
- 1:53.2744568630961
- 0:12.748856859862467
- 1:53.1318207882109
- 0:12.746598028731638
- 1:53.12649456692826
- 0:12.737519542314804
- 1:53.104644841140704
- 0:12.73734757961189
- 1:53.10266276004764
- system:index:20191210T101411_20191210T101409_T32UQE
- system:time_start:1575972955389
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.362736367166391
- 1:52.23364424529626
- 0:12.36275442975186
- 1:52.23357079900345
- 0:12.363429779356208
- 1:52.23318527441509
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.79288466762039
- 1:53.22927995828482
- 0:12.791947380974987
- 1:53.22868165366474
- 0:12.788677342662874
- 1:53.22212615181733
- 0:12.786260861935444
- 1:53.21668529895227
- 0:12.751715814498798
- 1:53.13835503586787
- 0:12.69016378176698
- 1:52.99799031031973
- 0:12.534457236094227
- 1:52.638241309568976
- 0:12.381197340264254
- 1:52.278301465625454
- 0:12.364268222624515
- 1:52.237455849979824
- 0:12.362736367166391
- 1:52.23364424529626
- system:index:20191210T101411_20191210T101409_T33UUU
- system:time_start:1575972969396
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20144637256129
- 1:54.13475896743524
- 0:13.198870487554808
- 1:54.12980371726535
- 0:13.195503471196746
- 1:54.12274046719384
- 0:13.192985126129937
- 1:54.11730884268457
- 0:13.000250797794056
- 1:53.69542837795015
- 0:12.811236024014661
- 1:53.27325002661116
- 0:12.783845455454697
- 1:53.21124566969115
- 0:12.754935143781115
- 1:53.14542837613929
- 0:12.75333820783807
- 1:53.14161937590457
- 0:12.753334668484982
- 1:53.14159672643144
- 0:12.753409667311587
- 1:53.14015957038269
- 0:12.753530299579868
- 1:53.140071857335464
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20191210T101411_20191210T101409_T33UUV
- system:time_start:1575972954800
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191213T102421_20191213T102424_T32UQD
- system:time_start:1576232766764
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191213T102421_20191213T102424_T32UQE
- system:time_start:1576232752405
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191213T102421_20191213T102424_T33UUU
- system:time_start:1576232765923
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191213T102421_20191213T102424_T33UUV
- system:time_start:1576232751855
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.782713053154616
- 1:53.18964595197851
- 0:12.78166827366903
- 1:53.18854106330814
- 0:12.780577043677194
- 1:53.18640592053379
- 0:12.65826942144186
- 1:52.910410657827114
- 0:12.537588252143063
- 1:52.634255063185705
- 0:12.446501033299787
- 1:52.42323638962783
- 0:12.393746935234109
- 1:52.29956171760567
- 0:12.368005813646535
- 1:52.23877712338224
- 0:12.361561587691957
- 1:52.223310172483785
- 0:12.358301974004224
- 1:52.21526056731913
- 0:12.358953008027196
- 1:52.21482176778806
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20191215T101329_20191215T101327_T32UQD
- system:time_start:1576404968424
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.743669205187837
- 1:53.10281174665722
- 0:12.743654009832554
- 1:53.102774944717794
- 0:12.744241782000772
- 1:53.102382150651984
- 0:12.744316423747552
- 1:53.102353359504775
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.178701999548382
- 1:54.075593219161334
- 0:13.178642576813344
- 1:54.07556599382762
- 0:13.178563371666748
- 1:54.07555568803041
- 0:13.177470233091157
- 1:54.07395014848619
- 0:13.067031433065914
- 1:53.831363327402464
- 0:12.957933432759154
- 1:53.58865058936639
- 0:12.743643237858361
- 1:53.10284267552208
- 0:12.743669205187837
- 1:53.10281174665722
- system:index:20191215T101329_20191215T101327_T32UQE
- system:time_start:1576404953551
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.80003928013
- 1:53.229412357398715
- 0:12.7991530262902
- 1:53.22826151958272
- 0:12.798334245129867
- 1:53.2266206874106
- 0:12.538152026634231
- 1:52.635620737016936
- 0:12.511491832679612
- 1:52.57409601957726
- 0:12.446715318505682
- 1:52.42380025576716
- 0:12.444382719003213
- 1:52.418354245614864
- 0:12.384711666945208
- 1:52.278379695492106
- 0:12.36927954430884
- 1:52.24188455511541
- 0:12.36621007438249
- 1:52.23424934214818
- 0:12.366262044611053
- 1:52.23337294929628
- 0:12.366674030030174
- 1:52.23325776962589
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20191215T101329_20191215T101327_T33UUU
- system:time_start:1576404967567
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.205128715905479
- 1:54.13423881238365
- 0:13.205108753155793
- 1:54.1342126752766
- 0:13.203412436168135
- 1:54.13094997037202
- 0:13.20089201947991
- 1:54.12551741057414
- 0:12.979452016602503
- 1:53.63628390126757
- 0:12.762946498272969
- 1:53.14665808713881
- 0:12.761349160536964
- 1:53.14284992588589
- 0:12.760564436039958
- 1:53.1406758430339
- 0:12.760593823809618
- 1:53.14064427342544
- 0:12.760583506021446
- 1:53.140605252194675
- 0:12.761224438706272
- 1:53.14024323582241
- 0:12.761303004647617
- 1:53.14021825470593
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.206146335473987
- 1:54.13482913537251
- 0:13.20605921898493
- 1:54.13481369722757
- 0:13.205128715905479
- 1:54.13423881238365
- system:index:20191215T101329_20191215T101327_T33UUV
- system:time_start:1576404952967
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.944921909089569
- 1:52.48558876138355
- 0:11.944932895751933
- 1:52.4855447245962
- 0:11.94800590498838
- 1:52.48464843696221
- 0:12.13665102746837
- 1:52.44633471028003
- 0:13.523190802822004
- 1:52.176235242518864
- 0:13.530676438519734
- 1:52.17621822126369
- 0:13.53075337527551
- 1:52.17622946440761
- 0:13.530929036239579
- 1:52.1763248120913
- 0:13.530976545678742
- 1:52.17636926651733
- 0:13.556185963149174
- 1:52.42217543241904
- 0:13.58175981001995
- 1:52.66794535466774
- 0:13.607706825521474
- 1:52.913696177043725
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.969418469365603
- 1:52.84882393570698
- 0:11.944879291453933
- 1:52.485620762883734
- 0:11.944921909089569
- 1:52.48558876138355
- system:index:20191218T102339_20191218T102427_T32UQD
- system:time_start:1576664764897
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191218T102339_20191218T102427_T32UQE
- system:time_start:1576664751642
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.055574586376775
- 1:52.465890994535286
- 0:12.055598323122458
- 1:52.465873773223414
- 0:12.056522710991334
- 1:52.4653534656327
- 0:12.056555833986765
- 1:52.465341052427874
- 0:12.060159243959422
- 1:52.46435046955268
- 0:12.109526165680418
- 1:52.45261578891143
- 0:12.26688102491302
- 1:52.42182536514234
- 0:12.993396513567331
- 1:52.28101385648445
- 0:13.177697063719899
- 1:52.248931025263026
- 0:13.190617779764871
- 1:52.24876950807942
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004609348085067
- 1:53.211994482054486
- 0:12.030361944296498
- 1:52.83897121938437
- 0:12.055550993304207
- 1:52.4659361773667
- 0:12.055574586376775
- 1:52.465890994535286
- system:index:20191218T102339_20191218T102427_T33UUU
- system:time_start:1576664764405
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191218T102339_20191218T102427_T33UUV
- system:time_start:1576664751092
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.789015912890292
- 1:53.18944546355215
- 0:12.78799352237602
- 1:53.188893235734994
- 0:12.783543833863146
- 1:53.179294779623284
- 0:12.776411903053976
- 1:53.16362145719394
- 0:12.660122730345925
- 1:52.90063928253859
- 0:12.547047300858504
- 1:52.64152722408796
- 0:12.488285244878547
- 1:52.50511921079698
- 0:12.457955588199553
- 1:52.43423457496667
- 0:12.399730013641998
- 1:52.29723056615893
- 0:12.372859915226808
- 1:52.23324127642645
- 0:12.36853513719186
- 1:52.22257044576608
- 0:12.366329786017152
- 1:52.2166882971642
- 0:12.366172924176201
- 1:52.2146158101576
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.789015912890292
- 1:53.18944546355215
- system:index:20191220T101431_20191220T101426_T32UQD
- system:time_start:1576836967785
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.750260061121972
- 1:53.102169521188785
- 0:12.750307032458482
- 1:53.102164501339914
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.185103813366958
- 1:54.075370269947705
- 0:13.185044498238733
- 1:54.075343035492864
- 0:13.184965208329507
- 1:54.07533282790417
- 0:13.183871916919317
- 1:54.07372734197899
- 0:13.073423050605461
- 1:53.83141598668495
- 0:12.964313676559744
- 1:53.5889787883499
- 0:12.749992931298626
- 1:53.103712878304194
- 0:12.749874970819222
- 1:53.102358161815026
- 0:12.749915365263368
- 1:53.10232758228839
- 0:12.749921020528246
- 1:53.10228534595035
- 0:12.750260061121972
- 1:53.102169521188785
- system:index:20191220T101431_20191220T101426_T32UQE
- system:time_start:1576836952923
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.373266987397038
- 1:52.23387631418428
- 0:12.373286236414762
- 1:52.233805783728464
- 0:12.37396144969251
- 1:52.233420201449036
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.806357023731266
- 1:53.229528829525826
- 0:12.805419563296239
- 1:53.22893062777181
- 0:12.80459331592687
- 1:53.227275651714855
- 0:12.548299168212797
- 1:52.64446364076725
- 0:12.545943060974224
- 1:52.63901955679152
- 0:12.485672792329096
- 1:52.49909319509944
- 0:12.456070087412314
- 1:52.429937054709626
- 0:12.398699688671527
- 1:52.29487583174513
- 0:12.374017990870016
- 1:52.23605325197516
- 0:12.373266987397038
- 1:52.23387631418428
- system:index:20191220T101431_20191220T101426_T33UUU
- system:time_start:1576836966930
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.766904324342649
- 1:53.14043547318933
- 0:12.766936059616366
- 1:53.140423509252756
- 0:12.767259654656877
- 1:53.140333736128575
- 0:12.767307208135058
- 1:53.140331068244734
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.211653495994458
- 1:54.1349110812111
- 0:13.211596669446912
- 1:54.13488016392635
- 0:13.211518179492563
- 1:54.13486419131161
- 0:12.989886064946349
- 1:53.64589919847493
- 0:12.773201415977221
- 1:53.15656079831745
- 0:12.766810700200798
- 1:53.14133340227459
- 0:12.766807188600017
- 1:53.14131083294819
- 0:12.766849129102088
- 1:53.14050239999895
- 0:12.766893671980705
- 1:53.14047393734763
- 0:12.766904324342649
- 1:53.14043547318933
- system:index:20191220T101431_20191220T101426_T33UUV
- system:time_start:1576836952344
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191223T102431_20191223T102430_T32UQD
- system:time_start:1577096765490
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191223T102431_20191223T102430_T32UQE
- system:time_start:1577096751108
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191223T102431_20191223T102430_T33UUU
- system:time_start:1577096764641
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191223T102431_20191223T102430_T33UUV
- system:time_start:1577096750559
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.781909872230218
- 1:53.1896715602609
- 0:12.781774521061513
- 1:53.18963350719861
- 0:12.780720737349915
- 1:53.188023739547916
- 0:12.589574502317321
- 1:52.754386227926226
- 0:12.402385185437614
- 1:52.32035999980196
- 0:12.374495551401608
- 1:52.25478185503857
- 0:12.3702092834182
- 1:52.2446505255257
- 0:12.358398710308911
- 1:52.21637595323789
- 0:12.358292163794015
- 1:52.21496495466037
- 0:12.358687034211828
- 1:52.21482933287204
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.781909872230218
- 1:53.1896715602609
- system:index:20191225T101329_20191225T101330_T32UQD
- system:time_start:1577268968862
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.743655568903678
- 1:53.10252487987755
- 0:12.743661231729384
- 1:53.10248264359418
- 0:12.744011853306585
- 1:53.102362911978354
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.178701999548382
- 1:54.075593219161334
- 0:13.178613038313427
- 1:54.07558213777721
- 0:13.177622256037962
- 1:54.0750645315708
- 0:13.177583266224968
- 1:54.075036217286744
- 0:13.129550377552855
- 1:53.97035919898847
- 0:13.101519346960947
- 1:53.90871490850562
- 0:12.92084139604814
- 1:53.50649195355687
- 0:12.743732981642955
- 1:53.103910177993775
- 0:12.743615171523961
- 1:53.10255545713274
- 0:12.743655568903678
- 1:53.10252487987755
- system:index:20191225T101329_20191225T101330_T32UQE
- system:time_start:1577268953989
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.799186553394795
- 1:53.229370710748015
- 0:12.79911647371673
- 1:53.2293637207833
- 0:12.79825391468925
- 1:53.2282436409448
- 0:12.59876540909071
- 1:52.77552149987782
- 0:12.40324326166787
- 1:52.322494119824114
- 0:12.400920857441935
- 1:52.31704728743451
- 0:12.371562577827584
- 1:52.24787114221218
- 0:12.367715234129141
- 1:52.238611967313616
- 0:12.366182175878189
- 1:52.23479829421691
- 0:12.366178949623007
- 1:52.23477567089294
- 0:12.36626400701125
- 1:52.23333866344433
- 0:12.36638284576196
- 1:52.23325122652834
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.799234100490509
- 1:53.229397453501655
- 0:12.799186553394795
- 1:53.229370710748015
- system:index:20191225T101329_20191225T101330_T33UUU
- system:time_start:1577268968004
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.205228492439293
- 1:54.13481540885739
- 0:13.205173206667242
- 1:54.13478533335439
- 0:13.205101195200244
- 1:54.134772190798316
- 0:13.205085493371662
- 1:54.13475167434909
- 0:13.204236848476866
- 1:54.133119668596144
- 0:13.184094694757619
- 1:54.08966812092349
- 0:13.128123567735285
- 1:53.967453687217
- 0:12.94460374850838
- 1:53.559633054096246
- 0:12.764487223995616
- 1:53.15154227281692
- 0:12.761293028523353
- 1:53.14392782202398
- 0:12.760504515634356
- 1:53.14174293325181
- 0:12.760579816551386
- 1:53.14029469395667
- 0:12.760642927644628
- 1:53.14025436807427
- 0:12.76070040347185
- 1:53.1402068932576
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20191225T101329_20191225T101330_T33UUV
- system:time_start:1577268953406
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20191228T102339_20191228T102333_T32UQD
- system:time_start:1577528766309
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20191228T102339_20191228T102333_T32UQE
- system:time_start:1577528751935
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20191228T102339_20191228T102333_T33UUU
- system:time_start:1577528765463
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20191228T102339_20191228T102333_T33UUV
- system:time_start:1577528751385
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.362675604451344
- 1:52.21484007741495
- 0:12.363070441877888
- 1:52.21470436060481
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.783639659910039
- 1:53.18961650866371
- 0:12.782619042522294
- 1:53.189065132733994
- 0:12.781520473089412
- 1:53.18691565944898
- 0:12.77816864576902
- 1:53.17946507298419
- 0:12.770338436023296
- 1:53.161903912043066
- 0:12.67923696612212
- 1:52.955268927859265
- 0:12.622607596205421
- 1:52.82542712344973
- 0:12.59287937798961
- 1:52.75671436059276
- 0:12.395008854079943
- 1:52.29304917229107
- 0:12.369229381779796
- 1:52.23172644898068
- 0:12.36386622186653
- 1:52.21892717196859
- 0:12.36278227299064
- 1:52.21625066041695
- 0:12.362675604451344
- 1:52.21484007741495
- system:index:20191230T101421_20191230T101423_T32UQD
- system:time_start:1577700968490
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.182300875495374
- 1:54.07543860171281
- 0:13.182221588739003
- 1:54.07542839197837
- 0:13.181128346116521
- 1:54.07382288493156
- 0:13.070585274966453
- 1:53.832726929719506
- 0:12.96137553527436
- 1:53.591504977164085
- 0:12.746841207468298
- 1:53.108678167829694
- 0:12.744580385847353
- 1:53.10334346606462
- 0:12.744509403903782
- 1:53.1025273313294
- 0:12.744549800864277
- 1:53.10249675374969
- 0:12.744555538319393
- 1:53.102454425827034
- 0:12.744906197557468
- 1:53.102334770600365
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.18236018662941
- 1:54.0754658378337
- 0:13.182300875495374
- 1:54.07543860171281
- system:index:20191230T101421_20191230T101423_T32UQE
- system:time_start:1577700953636
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.801030381272573
- 1:53.22943064895154
- 0:12.800998102093613
- 1:53.22941243846429
- 0:12.800954336607205
- 1:53.22941662179075
- 0:12.800925416741734
- 1:53.22940222362546
- 0:12.800037999751884
- 1:53.22883589033465
- 0:12.800019295706903
- 1:53.228808262148796
- 0:12.6798540586862
- 1:52.95678840313508
- 0:12.624295464506055
- 1:52.82944689827233
- 0:12.591128763323775
- 1:52.752706776201904
- 0:12.391391664569575
- 1:52.28446268854148
- 0:12.370570610690004
- 1:52.23489633712581
- 0:12.370567310140665
- 1:52.2348735569
- 0:12.370652185191528
- 1:52.23343654782583
- 0:12.370714335315151
- 1:52.23339644654765
- 0:12.370771164807428
- 1:52.23334917273138
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- system:index:20191230T101421_20191230T101423_T33UUU
- system:time_start:1577700967634
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.761881980053655
- 1:53.140232765565884
- 0:12.76192949326127
- 1:53.14023002081146
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20981785084631
- 1:54.13488378573648
- 0:13.209730611614141
- 1:54.13486836379394
- 0:13.208798314256093
- 1:54.13429234691714
- 0:13.208778884735743
- 1:54.134264796150404
- 0:13.20121896567878
- 1:54.11797157163747
- 0:12.981304483266065
- 1:53.63550621049964
- 0:12.766224401392938
- 1:53.15265387731677
- 0:12.761432895110152
- 1:53.14123241009672
- 0:12.761429349922645
- 1:53.141209761149796
- 0:12.761471455277933
- 1:53.140401408052774
- 0:12.761515999709212
- 1:53.140372947699525
- 0:12.7615275370384
- 1:53.140331050151644
- 0:12.761881980053655
- 1:53.140232765565884
- system:index:20191230T101421_20191230T101423_T33UUV
- system:time_start:1577700953053
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200720T102031_20200720T102321_T32UQD
- system:time_start:1595240776348
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200720T102031_20200720T102321_T32UQE
- system:time_start:1595240761984
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200720T102031_20200720T102321_T33UUU
- system:time_start:1595240775507
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200720T102031_20200720T102321_T33UUV
- system:time_start:1595240761434
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.782805891018155
- 1:53.18964303045649
- 0:12.782670575039683
- 1:53.18960505805122
- 0:12.781616699817695
- 1:53.18799522184085
- 0:12.7681699007649
- 1:53.15765516520103
- 0:12.568313025262833
- 1:52.70106143972083
- 0:12.372800270274068
- 1:52.24403687605295
- 0:12.3631524256446
- 1:52.22110626264292
- 0:12.360988113421916
- 1:52.21576216358445
- 0:12.36092226895137
- 1:52.21489004409983
- 0:12.361316995648837
- 1:52.21475434553356
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.782805891018155
- 1:53.18964303045649
- system:index:20200722T100559_20200722T100846_T32UQD
- system:time_start:1595412975741
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.180531077165108
- 1:54.07552954468758
- 0:13.180386047873672
- 1:54.07548604515737
- 0:13.17924365608908
- 1:54.07334539082468
- 0:13.173373581576998
- 1:54.06059455651616
- 0:12.968493070233583
- 1:53.6093484897654
- 0:12.768169750781377
- 1:53.157654847599105
- 0:12.74796975135947
- 1:53.111340869690906
- 0:12.744580385847353
- 1:53.10334346606462
- 0:12.744504640936894
- 1:53.10247179721841
- 0:12.744906197557468
- 1:53.102334770600365
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.180531077165108
- 1:54.07552954468758
- system:index:20200722T100559_20200722T100846_T32UQE
- system:time_start:1595412960886
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.36929503102329
- 1:52.233319799034646
- 0:12.36934162308654
- 1:52.23331723922401
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.800132273537326
- 1:53.22941400928025
- 0:12.800078412978673
- 1:53.22938377630461
- 0:12.800002559832352
- 1:53.22936939344993
- 0:12.7975467312685
- 1:53.22444821715271
- 0:12.79271229872508
- 1:53.21356825433561
- 0:12.592667359862773
- 1:52.75705423945531
- 0:12.396625784573724
- 1:52.30022590401728
- 0:12.369597678668551
- 1:52.2364944277048
- 0:12.368843110523876
- 1:52.23430657202575
- 0:12.368891638936079
- 1:52.23348725098939
- 0:12.368935407600265
- 1:52.233458897706846
- 0:12.368947072426712
- 1:52.233417078648536
- 0:12.36929503102329
- 1:52.233319799034646
- system:index:20200722T100559_20200722T100846_T33UUU
- system:time_start:1595412974886
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.207982130669402
- 1:54.1348564704584
- 0:13.20793311929686
- 1:54.1348298452332
- 0:13.207867368913714
- 1:54.134823626079324
- 0:13.207846828581378
- 1:54.13480458026111
- 0:13.20697089078438
- 1:54.133707199755854
- 0:13.205271203572902
- 1:54.130438385429585
- 0:13.200231432694766
- 1:54.119574832257214
- 0:12.97956794653542
- 1:53.63385856480401
- 0:12.763786870435787
- 1:53.147752848672745
- 0:12.762189379996194
- 1:53.1439446455989
- 0:12.761400799482823
- 1:53.14175976458211
- 0:12.761476062364789
- 1:53.140311525147276
- 0:12.761539210552943
- 1:53.14027127810665
- 0:12.761596798993509
- 1:53.14022379049045
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20200722T100559_20200722T100846_T33UUV
- system:time_start:1595412960307
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200725T101559_20200725T102124_T32UQD
- system:time_start:1595672773496
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200725T101559_20200725T102124_T32UQE
- system:time_start:1595672759124
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200725T101559_20200725T102124_T33UUU
- system:time_start:1595672772651
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200725T101559_20200725T102124_T33UUV
- system:time_start:1595672758575
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.728584472468253
- 1:53.094662908004935
- 0:12.728664917918747
- 1:53.09457578913283
- 0:12.756134179059924
- 1:53.09046885310524
- 0:12.803510953561291
- 1:53.08383492142501
- 0:12.835243300126756
- 1:53.07948697221557
- 0:13.605117518636936
- 1:52.972055382822866
- 0:13.613739090546394
- 1:52.97172034913897
- 0:13.61389561877453
- 1:52.97178399248494
- 0:13.634034600698282
- 1:53.15942775214035
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.770153104926015
- 1:53.19004467711716
- 0:12.769072872021415
- 1:53.188393707632834
- 0:12.76685364549628
- 1:53.183602219345964
- 0:12.761289477860887
- 1:53.171365304244695
- 0:12.75459791142229
- 1:53.15646533457339
- 0:12.731076656652922
- 1:53.102697772055166
- 0:12.728818275338327
- 1:53.09736285845369
- 0:12.728584472468253
- 1:53.094662908004935
- system:index:20200727T101031_20200727T101030_T32UQD
- system:time_start:1595844971721
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16854693755469
- 1:54.075946087342274
- 0:13.16746872770025
- 1:54.07484533640557
- 0:13.166332572744484
- 1:54.072714616037246
- 0:13.15578765943001
- 1:54.049870609537834
- 0:12.95296144437562
- 1:53.60338701205026
- 0:12.754597799053357
- 1:53.15646509635865
- 0:12.734412991618154
- 1:53.110148411691384
- 0:12.732153743177259
- 1:53.10481360548757
- 0:12.731981885770447
- 1:53.10283127775482
- 0:12.732089801506097
- 1:53.102737831309284
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20200727T101031_20200727T101030_T32UQE
- system:time_start:1595844964553
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.727967575135704
- 1:53.09525997548999
- 0:12.727993592616814
- 1:53.09520919993278
- 0:12.728959422889238
- 1:53.094663604098095
- 0:12.735348497967973
- 1:53.09315754439565
- 0:12.76740775746516
- 1:53.08863674885126
- 0:13.639033960627701
- 1:52.966946420340435
- 0:13.652204838369002
- 1:52.965385979646165
- 0:13.656686259430192
- 1:52.96543672372343
- 0:13.656833466527578
- 1:52.96550799082811
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.787558174922678
- 1:53.22918115744251
- 0:12.787473033048068
- 1:53.22916552174907
- 0:12.786558533590924
- 1:53.228581666960594
- 0:12.78573307808123
- 1:53.22692656188906
- 0:12.783316625640667
- 1:53.22148571927032
- 0:12.752776652977644
- 1:53.152401291481375
- 0:12.727942763673628
- 1:53.09582176801581
- 0:12.727939169860552
- 1:53.09579897300267
- 0:12.727967575135704
- 1:53.09525997548999
- system:index:20200727T101031_20200727T101030_T33UUU
- system:time_start:1595844971212
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.747988640723776
- 1:53.14097883602863
- 0:12.747985105262968
- 1:53.140956186490016
- 0:12.748030267873412
- 1:53.140092290997615
- 0:12.748450023497783
- 1:53.13997585925901
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.195132098279165
- 1:54.134664473899086
- 0:13.19501165751303
- 1:54.13463106532087
- 0:13.194121305700389
- 1:54.133515002344765
- 0:13.193270250613601
- 1:54.131877168164316
- 0:13.189903978741699
- 1:54.12481374640204
- 0:13.184869208948388
- 1:54.113950545295886
- 0:12.966432025976545
- 1:53.633366391997
- 0:12.752776390845083
- 1:53.15240073567248
- 0:12.747988640723776
- 1:53.14097883602863
- system:index:20200727T101031_20200727T101030_T33UUV
- system:time_start:1595844963958
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.348648391568425
- 1:52.21523928072888
- 0:12.349043256354099
- 1:52.21510369524913
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.555838863653284
- 1:52.418814786446504
- 0:13.581130529415425
- 1:52.66194137575473
- 0:13.606787524481748
- 1:52.90504930870121
- 0:13.632822053591479
- 1:53.148189209481664
- 0:13.631298645945625
- 1:53.14882280392361
- 0:13.62685935569902
- 1:53.14953872310022
- 0:13.550858329992137
- 1:53.161110831605576
- 0:13.534912688255018
- 1:53.16334107465688
- 0:12.770153104926015
- 1:53.19004467711716
- 0:12.769072872021415
- 1:53.188393707632834
- 0:12.76685364549628
- 1:53.183602219345964
- 0:12.761289477860887
- 1:53.171365304244695
- 0:12.754597986334913
- 1:53.15646549338322
- 0:12.577353386134225
- 1:52.75178756433263
- 0:12.4623264804671
- 1:52.48429573661015
- 0:12.348754700751313
- 1:52.216650449620545
- 0:12.348648391568425
- 1:52.21523928072888
- system:index:20200727T101031_20200727T101605_T32UQD
- system:time_start:1595844979438
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.631298645945625
- 1:53.14882280392361
- 0:13.62685935569902
- 1:53.14953872310022
- 0:13.550858518430234
- 1:53.161110726155215
- 0:13.514574496572353
- 1:53.16627326558789
- 0:13.430456245525846
- 1:53.17807485082517
- 0:13.387930902149597
- 1:53.18397018417944
- 0:12.917542142596053
- 1:53.24788696140775
- 0:12.852629890354367
- 1:53.25648176193639
- 0:12.82505126618088
- 1:53.26006949350995
- 0:12.80273017425494
- 1:53.26295050412714
- 0:12.801694800937284
- 1:53.26239252084628
- 0:12.790321845854356
- 1:53.237361888027166
- 0:12.754597799053357
- 1:53.15646509635865
- 0:12.734412991618154
- 1:53.110148411691384
- 0:12.732153743177259
- 1:53.10481360548757
- 0:12.731974085084227
- 1:53.10274146020476
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.632822053591479
- 1:53.148189209481664
- 0:13.631298645945625
- 1:53.14882280392361
- system:index:20200727T101031_20200727T101605_T32UQE
- system:time_start:1595844971243
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.786558533590924
- 1:53.228581666960594
- 0:12.785707534273426
- 1:53.22687536145531
- 0:12.60620299699476
- 1:52.81829310590885
- 0:12.576209227698115
- 1:52.74916565999739
- 0:12.374232948804417
- 1:52.27706775156521
- 0:12.357277951682162
- 1:52.236758597672306
- 0:12.356524004343068
- 1:52.23457073703132
- 0:12.356615427861735
- 1:52.233032763682395
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.66499011931871
- 1:52.70031525237577
- 0:13.651225735493824
- 1:53.14543353116635
- 0:13.649624934435773
- 1:53.14604929853907
- 0:13.643289605713441
- 1:53.147060043312585
- 0:13.544090476912064
- 1:53.16207077641991
- 0:13.516130013296621
- 1:53.16604107955221
- 0:13.48094927872043
- 1:53.170991624931304
- 0:13.442151652700016
- 1:53.176423919982945
- 0:13.392514246457267
- 1:53.18331609710232
- 0:13.024761618581529
- 1:53.23334965644781
- 0:12.787495773379822
- 1:53.22918001024985
- 0:12.786558533590924
- 1:53.228581666960594
- system:index:20200727T101031_20200727T101605_T33UUU
- system:time_start:1595844978845
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.599765492813832
- 1:53.153032092514195
- 0:13.599866504469798
- 1:53.153143344679506
- 0:13.599157535976882
- 1:53.15355317751418
- 0:13.596411402013404
- 1:53.15406770272448
- 0:13.544090705056329
- 1:53.16207075004853
- 0:13.516130013296621
- 1:53.16604107955221
- 0:13.48094927872043
- 1:53.170991624931304
- 0:13.442151652700016
- 1:53.176423919982945
- 0:13.39612450468519
- 1:53.18282536829241
- 0:12.904364301582458
- 1:53.24963141163112
- 0:12.802929873013591
- 1:53.26291194638981
- 0:12.801901191196725
- 1:53.262892987455295
- 0:12.789751048263296
- 1:53.236170928665736
- 0:12.787334086579284
- 1:53.2307311800248
- 0:12.752776428292593
- 1:53.15240081507376
- 0:12.747984378235628
- 1:53.14096878360056
- 0:12.748030267873412
- 1:53.140092290997615
- 0:12.748450023497783
- 1:53.13997585925901
- 0:13.599765492813832
- 1:53.153032092514195
- system:index:20200727T101031_20200727T101605_T33UUV
- system:time_start:1595844971092
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200730T102031_20200730T102528_T32UQD
- system:time_start:1596104776962
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200730T102031_20200730T102528_T32UQE
- system:time_start:1596104762599
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200730T102031_20200730T102528_T33UUU
- system:time_start:1596104776122
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200730T102031_20200730T102528_T33UUV
- system:time_start:1596104762050
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.78011778400726
- 1:53.189728437459465
- 0:12.780030849665643
- 1:53.18971710117874
- 0:12.779032784701212
- 1:53.189177859576525
- 0:12.58276805398228
- 1:52.74190991133693
- 0:12.390700276640954
- 1:52.294252586282006
- 0:12.38211416900633
- 1:52.27399163508983
- 0:12.368169106179563
- 1:52.2409311713277
- 0:12.358524332211472
- 1:52.218000153383784
- 0:12.35744411850287
- 1:52.215332239687605
- 0:12.357455597205258
- 1:52.21526510805941
- 0:12.358076319975005
- 1:52.21484672839702
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.78011778400726
- 1:53.189728437459465
- system:index:20200801T100559_20200801T101400_T32UQD
- system:time_start:1596276976682
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.176753240769763
- 1:54.07566095722995
- 0:13.175585669149168
- 1:54.07347258540701
- 0:13.156808964603234
- 1:54.032564367193295
- 0:12.952180667751836
- 1:53.580475863888836
- 0:12.752107726018908
- 1:53.127940663499146
- 0:12.74538013279309
- 1:53.11250186957689
- 0:12.741991101872218
- 1:53.104504354364764
- 0:12.741818864802248
- 1:53.102522040314405
- 0:12.741926764735663
- 1:53.10242858446197
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20200801T100559_20200801T101400_T32UQE
- system:time_start:1596276961818
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.365336523385336
- 1:52.23423991151142
- 0:12.365333116840565
- 1:52.234217142908015
- 0:12.365384367210732
- 1:52.23335334071362
- 0:12.365796350849795
- 1:52.23323816460375
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.797437748606528
- 1:53.22936423863998
- 0:12.797320126314577
- 1:53.22933050381703
- 0:12.796458627756703
- 1:53.22821172169778
- 0:12.795639855790117
- 1:53.22657079890313
- 0:12.778732197353573
- 1:53.18849316390688
- 0:12.578512832610343
- 1:52.731678460559465
- 0:12.382298375918552
- 1:52.2745491129691
- 0:12.369183991008963
- 1:52.24350143057054
- 0:12.365336523385336
- 1:52.23423991151142
- system:index:20200801T100559_20200801T101400_T33UUU
- system:time_start:1596276975826
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.757876703263605
- 1:53.14062811738896
- 0:12.7578946564973
- 1:53.14055464445989
- 0:12.75858099950652
- 1:53.14016701335713
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20431069959926
- 1:54.1348017543702
- 0:13.204190119044918
- 1:54.134768369763606
- 0:13.203299592644896
- 1:54.1336523652297
- 0:13.201600425240999
- 1:54.130383898613175
- 0:13.198232787404972
- 1:54.12332068559184
- 0:13.185646102909539
- 1:54.09616372992886
- 0:12.973089744094475
- 1:53.62700638106807
- 0:12.7650758941726
- 1:53.15748778660363
- 0:12.761069519990091
- 1:53.1482411205789
- 0:12.757876703263605
- 1:53.14062811738896
- system:index:20200801T100559_20200801T101400_T33UUV
- system:time_start:1596276961235
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200804T101559_20200804T101730_T32UQD
- system:time_start:1596536774321
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200804T101559_20200804T101730_T32UQE
- system:time_start:1596536759952
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200804T101559_20200804T101730_T33UUU
- system:time_start:1596536773476
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200804T101559_20200804T101730_T33UUV
- system:time_start:1596536759402
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.346067857303382
- 1:52.21530018033134
- 0:12.346097353459044
- 1:52.215286850538256
- 0:12.34640172745755
- 1:52.21518226024765
- 0:12.346447911422462
- 1:52.21517736523985
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.768469211051766
- 1:53.190097961472695
- 0:12.768406199995697
- 1:53.19006806476725
- 0:12.768324930984154
- 1:53.19005100975836
- 0:12.554751933923955
- 1:52.70362806822549
- 0:12.346124429375626
- 1:52.21672517321625
- 0:12.346022514710636
- 1:52.215369499168865
- 0:12.346062312491437
- 1:52.21533903154561
- 0:12.346067857303382
- 1:52.21530018033134
- system:index:20200806T101031_20200806T101511_T32UQD
- system:time_start:1596708979801
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.7302288803098
- 1:53.1032637360964
- 0:12.730239939389612
- 1:53.103196561207874
- 0:12.730869303285536
- 1:53.10277614756995
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16589798332256
- 1:54.076038016493854
- 0:13.165759388849166
- 1:54.076000467573635
- 0:13.164667892358308
- 1:54.074396533204194
- 0:13.163535203432627
- 1:54.07227211261839
- 0:13.16003675170251
- 1:54.06483558214608
- 0:12.943716451747115
- 1:53.586962060611086
- 0:12.7324840667888
- 1:53.1085900291094
- 0:12.7302288803098
- 1:53.1032637360964
- system:index:20200806T101031_20200806T101511_T32UQE
- system:time_start:1596708964907
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.354092777758861
- 1:52.232979037365375
- 0:12.354117068686591
- 1:52.23297679078603
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.78576190974339
- 1:53.229147840192944
- 0:12.785708071977394
- 1:53.2291175994228
- 0:12.78563760955342
- 1:53.22910420902562
- 0:12.785622494958233
- 1:53.229083625982476
- 0:12.784807166579988
- 1:53.227448795642665
- 0:12.581160749918617
- 1:52.76410362343992
- 0:12.381651424218209
- 1:52.30043434062481
- 0:12.353862911943901
- 1:52.235062343976196
- 0:12.353859587875386
- 1:52.235039484352406
- 0:12.353977176923102
- 1:52.23306372844898
- 0:12.354039297662343
- 1:52.23302355870905
- 0:12.354092777758861
- 1:52.232979037365375
- system:index:20200806T101031_20200806T101511_T33UUU
- system:time_start:1596708978941
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.19232328591681
- 1:54.1345930237902
- 0:13.192245734750017
- 1:54.13457888199775
- 0:13.189692899815451
- 1:54.12966569871446
- 0:13.182140686017847
- 1:54.11337000563144
- 0:13.099526925487798
- 1:53.93248489464305
- 0:13.065519385473065
- 1:53.85750759149617
- 0:12.767908646443829
- 1:53.18936943670089
- 0:12.7486604124216
- 1:53.1453098357838
- 0:12.747064093085637
- 1:53.1415007518362
- 0:12.747060595693416
- 1:53.14147818147908
- 0:12.74713585872318
- 1:53.14004102644257
- 0:12.74725646046883
- 1:53.13995324123949
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.192378551411378
- 1:54.13462310639914
- 0:13.19232328591681
- 1:54.1345930237902
- system:index:20200806T101031_20200806T101511_T33UUV
- system:time_start:1596708964312
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200809T102031_20200809T102029_T32UQD
- system:time_start:1596968777179
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200809T102031_20200809T102029_T32UQE
- system:time_start:1596968762827
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200809T102031_20200809T102029_T33UUU
- system:time_start:1596968776341
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200809T102031_20200809T102029_T33UUV
- system:time_start:1596968762276
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.353076008170598
- 1:52.21513979353879
- 0:12.353081954255183
- 1:52.215097525043284
- 0:12.353426862583117
- 1:52.214979070645825
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.774741601051723
- 1:53.18989914362019
- 0:12.774690429342392
- 1:53.18987489404389
- 0:12.774619728660376
- 1:53.189871392560335
- 0:12.773602732862084
- 1:53.18879566606253
- 0:12.76015848598489
- 1:53.15844834184765
- 0:12.555451212350878
- 1:52.69038509258288
- 0:12.355301717969336
- 1:52.22186965568563
- 0:12.353138281377943
- 1:52.21652535906219
- 0:12.353036177978616
- 1:52.21517018517357
- 0:12.353076008170598
- 1:52.21513979353879
- system:index:20200811T100559_20200811T101318_T32UQD
- system:time_start:1597140977204
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.17311985342091
- 1:54.07578726494335
- 0:13.172040259527778
- 1:54.074685176091684
- 0:13.158045717011445
- 1:54.04493523091648
- 0:12.971825309641012
- 1:53.6351431314322
- 0:12.789373499872948
- 1:53.22498115063618
- 0:12.74895069300718
- 1:53.13289729981368
- 0:12.738838329512502
- 1:53.109469570533115
- 0:12.73657855057869
- 1:53.104134983053996
- 0:12.7364562157422
- 1:53.10272505016687
- 0:12.736857769432548
- 1:53.10258805406959
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20200811T100559_20200811T101318_T32UQE
- system:time_start:1597140962338
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.791058424763653
- 1:53.22867088634062
- 0:12.791039120629287
- 1:53.22864474335097
- 0:12.790223595162391
- 1:53.22700995972465
- 0:12.787806576130201
- 1:53.22156911737376
- 0:12.582261841182472
- 1:52.752256616272135
- 0:12.380943182478441
- 1:52.28261256331216
- 0:12.362448810124766
- 1:52.23849440815406
- 0:12.360916199963615
- 1:52.23468059297776
- 0:12.360912977471141
- 1:52.23465796944583
- 0:12.36099825365733
- 1:52.233220963963866
- 0:12.361117097803955
- 1:52.23313353311593
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792048871934362
- 1:53.229264495186534
- 0:12.791963685502253
- 1:53.22924878381713
- 0:12.791058424763653
- 1:53.22867088634062
- system:index:20200811T100559_20200811T101318_T33UUU
- system:time_start:1597140976347
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.19966602881829
- 1:54.1347030916302
- 0:13.199588467635492
- 1:54.134688955436296
- 0:13.197882571432798
- 1:54.13140694752543
- 0:13.191150368028365
- 1:54.117281677298706
- 0:13.188632880649497
- 1:54.11184992154349
- 0:12.98616293259065
- 1:53.666873560809755
- 0:12.787806500912245
- 1:53.22156895845094
- 0:12.752470069150323
- 1:53.14106372345468
- 0:12.75246645557429
- 1:53.1410409153349
- 0:12.752494655292065
- 1:53.1405019863235
- 0:12.752520685101905
- 1:53.1404511723211
- 0:12.753158085866042
- 1:53.14009126084125
- 0:12.753236649817087
- 1:53.140066285886796
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.199721305900828
- 1:54.1347331701791
- 0:13.19966602881829
- 1:54.1347030916302
- system:index:20200811T100559_20200811T101318_T33UUV
- system:time_start:1597140961751
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200814T101559_20200814T102222_T32UQD
- system:time_start:1597400774681
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200814T101559_20200814T102222_T32UQE
- system:time_start:1597400760312
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200814T101559_20200814T102222_T33UUU
- system:time_start:1597400773838
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200814T101559_20200814T102222_T33UUV
- system:time_start:1597400759762
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.76751092407045
- 1:53.19012830462428
- 0:12.76648883313479
- 1:53.18957596434745
- 0:12.764260157985353
- 1:53.18476352306642
- 0:12.750875573778755
- 1:53.15496393965485
- 0:12.632087196158395
- 1:52.88558063275034
- 0:12.578192487229616
- 1:52.76201598151512
- 0:12.544251673030402
- 1:52.68370516508438
- 0:12.372070978214301
- 1:52.2807551176829
- 0:12.348489739138191
- 1:52.224761633293035
- 0:12.345247720165043
- 1:52.2167495414328
- 0:12.345141556577392
- 1:52.21533885791241
- 0:12.345536529007013
- 1:52.21520327400931
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20200816T101031_20200816T101030_T32UQD
- system:time_start:1597572979675
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.728452914596417
- 1:53.10300270690606
- 0:12.728458558449441
- 1:53.102960391400444
- 0:12.728809325623242
- 1:53.10284077721447
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164983314447332
- 1:54.076069714156716
- 0:13.16489441023952
- 1:54.076058700942774
- 0:13.163903754039763
- 1:54.07554098064015
- 0:13.163864742226465
- 1:54.07551258052058
- 0:13.053612050747763
- 1:53.834112085283294
- 0:12.944695510238002
- 1:53.59259655553208
- 0:12.730742007588843
- 1:53.109184391232525
- 0:12.728483196968584
- 1:53.10384942686057
- 0:12.728412510092898
- 1:53.103033278643835
- 0:12.728452914596417
- 1:53.10300270690606
- system:index:20200816T101031_20200816T101030_T32UQE
- system:time_start:1597572964786
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35223310078358
- 1:52.23337557719931
- 0:12.352222882061517
- 1:52.23333492943671
- 0:12.35285371974349
- 1:52.23297485631962
- 0:12.352930878792233
- 1:52.23295013092273
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.7839117009891
- 1:53.22908418230497
- 0:12.783835983850446
- 1:53.22906977493141
- 0:12.782196403598165
- 1:53.22578189526259
- 0:12.633528070125163
- 1:52.888976905332015
- 0:12.543525950377774
- 1:52.68213159940971
- 0:12.482448310188236
- 1:52.54002995922549
- 0:12.42407860032079
- 1:52.40334519415689
- 0:12.37068697839757
- 1:52.277528372021656
- 0:12.352205044523746
- 1:52.23340917116389
- 0:12.35223310078358
- 1:52.23337557719931
- system:index:20200816T101031_20200816T101030_T33UUU
- system:time_start:1597572978815
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.191411800736603
- 1:54.134582716632714
- 0:13.191340240150602
- 1:54.134575950048976
- 0:13.19045009153048
- 1:54.1334599335177
- 0:13.188751676004122
- 1:54.13019089813756
- 0:13.186233369696213
- 1:54.12475814939824
- 0:13.16947265997023
- 1:54.08836770945499
- 0:12.957095149066571
- 1:53.61999182104938
- 0:12.74924682016558
- 1:53.151255415221556
- 0:12.745243369998704
- 1:53.142005868797064
- 0:12.7452397990636
- 1:53.141983139405255
- 0:12.745343340786802
- 1:53.140007060229685
- 0:12.745463944507522
- 1:53.13991927709296
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.191460789016157
- 1:54.13460934995664
- 0:13.191411800736603
- 1:54.134582716632714
- system:index:20200816T101031_20200816T101030_T33UUV
- system:time_start:1597572964189
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.525829587720475
- 1:52.17613452304723
- 0:13.525952777113785
- 1:52.17616413810203
- 0:13.530947775709363
- 1:52.18193340869052
- 0:13.531652251988845
- 1:52.18300435884433
- 0:13.556699864890128
- 1:52.42714931454759
- 0:13.582107343271444
- 1:52.67126105463685
- 0:13.607883220530036
- 1:52.91535386885305
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.969519677391347
- 1:52.85030525984923
- 0:11.945074018512242
- 1:52.488533860142205
- 0:11.9795465237521
- 1:52.474146550365255
- 0:12.105069275430166
- 1:52.449327263153656
- 0:13.159902493294684
- 1:52.244690787873424
- 0:13.508316924152004
- 1:52.17680638575076
- 0:13.525829587720475
- 1:52.17613452304723
- system:index:20200819T102031_20200819T102257_T32UQD
- system:time_start:1597832775770
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200819T102031_20200819T102257_T32UQE
- system:time_start:1597832762608
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004609348085067
- 1:53.211994482054486
- 0:12.03034356932239
- 1:52.83924055880019
- 0:12.055515064577477
- 1:52.4664749032696
- 0:12.05555928424875
- 1:52.46644665557427
- 0:12.055570334345658
- 1:52.46640829589842
- 0:12.055601904041813
- 1:52.46639653831866
- 0:12.07000800232837
- 1:52.46243564055142
- 0:12.127306282050583
- 1:52.450890146460964
- 0:12.49886093257815
- 1:52.37732445388639
- 0:13.139032146238591
- 1:52.248330305041016
- 0:13.139071467510899
- 1:52.24832767674529
- 0:13.221366197097272
- 1:52.249236970320084
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- system:index:20200819T102031_20200819T102257_T33UUU
- system:time_start:1597832775302
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200819T102031_20200819T102257_T33UUV
- system:time_start:1597832762057
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77285662559716
- 1:53.18995891189564
- 0:12.771810856722684
- 1:53.18885264607414
- 0:12.755070084129164
- 1:53.15159343461642
- 0:12.555932869660937
- 1:52.69630696715346
- 0:12.361110768233331
- 1:52.24059294455195
- 0:12.355748742288974
- 1:52.22779322843793
- 0:12.35142545890154
- 1:52.217113746899436
- 0:12.351275923202813
- 1:52.21513030329841
- 0:12.351382585872479
- 1:52.21503719929329
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20200821T100559_20200821T101228_T32UQD
- system:time_start:1598004977322
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.170376072089784
- 1:54.07588256662869
- 0:13.16929789701841
- 1:54.074781824134
- 0:13.168161445096457
- 1:54.07265106116541
- 0:12.95924564637449
- 1:53.612353688701845
- 0:12.755069972677685
- 1:53.15159294591511
- 0:12.735968294871299
- 1:53.1074011303681
- 0:12.734836718498578
- 1:53.104729371434786
- 0:12.734664695858061
- 1:53.10274705412164
- 0:12.734772569932963
- 1:53.102653525755564
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20200821T100559_20200821T101228_T32UQE
- system:time_start:1598004962448
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.789227907791847
- 1:53.22916855575043
- 0:12.789213737181043
- 1:53.22914770307834
- 0:12.786797429820218
- 1:53.223708276278124
- 0:12.570214163158166
- 1:52.72908082546924
- 0:12.358315305836332
- 1:52.234083013020644
- 0:12.35831197858626
- 1:52.23406015394082
- 0:12.358344001925502
- 1:52.233521318702046
- 0:12.358369933397432
- 1:52.233470580374416
- 0:12.35899711215372
- 1:52.23311258460888
- 0:12.359074272963237
- 1:52.233087854550874
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.789354406658127
- 1:53.22921453474213
- 0:12.789299278435992
- 1:53.229183600125026
- 0:12.789227907791847
- 1:53.22916855575043
- system:index:20200821T100559_20200821T101228_T33UUU
- system:time_start:1598004976464
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.196912484881627
- 1:54.134661913032936
- 0:13.196834887822837
- 1:54.13464769449321
- 0:13.19512908603226
- 1:54.13136540881166
- 0:13.19260970569288
- 1:54.125932732097176
- 0:13.164125871313933
- 1:54.064015326686665
- 0:12.956425459755634
- 1:53.605685986475166
- 0:12.753057741207705
- 1:53.14701085664626
- 0:12.75067745183268
- 1:53.1410295100211
- 0:12.750673876061752
- 1:53.14100703167756
- 0:12.750716198727762
- 1:53.14019860015889
- 0:12.75076074626071
- 1:53.140170144402134
- 0:12.750772219724773
- 1:53.14012833958154
- 0:12.751138844379
- 1:53.14002668089653
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19696787477602
- 1:54.13469198006072
- 0:13.196912484881627
- 1:54.134661913032936
- system:index:20200821T100559_20200821T101228_T33UUV
- system:time_start:1598004961859
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200824T101559_20200824T102306_T32UQD
- system:time_start:1598264774660
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200824T101559_20200824T102306_T32UQE
- system:time_start:1598264760293
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200824T101559_20200824T102306_T33UUU
- system:time_start:1598264773819
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200824T101559_20200824T102306_T33UUV
- system:time_start:1598264759743
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.37805978669994
- 1:52.301630849743844
- 0:12.373767850157453
- 1:52.29149994723778
- 0:12.351258469195399
- 1:52.23817501595157
- 0:12.345899482780528
- 1:52.2253747445396
- 0:12.342657993225467
- 1:52.21736266438473
- 0:12.342502064257346
- 1:52.215289325602825
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.7647767488484
- 1:53.190214854043894
- 0:12.763697410651623
- 1:53.18856500927888
- 0:12.76261034280872
- 1:53.18643602684735
- 0:12.757046365203111
- 1:53.17419767571921
- 0:12.628769943512532
- 1:52.88325357732076
- 0:12.502288732243805
- 1:52.59213165829324
- 0:12.456720615455488
- 1:52.486078888428985
- 0:12.37805978669994
- 1:52.301630849743844
- system:index:20200826T101031_20200826T101345_T32UQD
- system:time_start:1598436979144
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:13.16132503150331
- 1:54.076196558271874
- 0:13.161265634092809
- 1:54.07616932237182
- 0:13.161192107754811
- 1:54.07615972771458
- 0:13.161173545713252
- 1:54.07614005102186
- 0:13.16009408842021
- 1:54.07455344680318
- 0:13.146057307256177
- 1:54.0442702259652
- 0:12.934000137426954
- 1:53.57513938341799
- 0:12.72683435535908
- 1:53.10552049744306
- 0:12.726616184766014
- 1:53.10299962986133
- 0:12.726673409844071
- 1:53.102956308676255
- 0:12.726724109117516
- 1:53.10290618854776
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- system:index:20200826T101031_20200826T101345_T32UQE
- system:time_start:1598436964247
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.349538837460226
- 1:52.23388590596267
- 0:12.349535513349139
- 1:52.23386329379732
- 0:12.349587012967245
- 1:52.23299942829067
- 0:12.349999074282813
- 1:52.23288430462691
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.781271130469108
- 1:53.229064273801384
- 0:12.781139361285334
- 1:53.22901718926141
- 0:12.533826712856031
- 1:52.66520481488327
- 0:12.505600134642338
- 1:52.59986969882767
- 0:12.422190767850505
- 1:52.40546236431188
- 0:12.37033592467575
- 1:52.28345591888811
- 0:12.357227563365303
- 1:52.252407158601216
- 0:12.351070493715543
- 1:52.2376998989842
- 0:12.349538837460226
- 1:52.23388590596267
- system:index:20200826T101031_20200826T101345_T33UUU
- system:time_start:1598436978284
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.187789414253729
- 1:54.134554120659864
- 0:13.18765649395019
- 1:54.134509903256344
- 0:13.185104288797135
- 1:54.12959670140223
- 0:13.176707537420691
- 1:54.11166999169797
- 0:13.171677856384617
- 1:54.10080636227999
- 0:12.961729046731561
- 1:53.63679249997048
- 0:12.75621897179184
- 1:53.172426319049606
- 0:12.749805023306232
- 1:53.1577394549763
- 0:12.744206744748208
- 1:53.14468585107667
- 0:12.742606782160548
- 1:53.14086691627679
- 0:12.742652659280724
- 1:53.139990357109866
- 0:12.74307255567875
- 1:53.139874014458805
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.187789414253729
- 1:54.134554120659864
- system:index:20200826T101031_20200826T101345_T33UUV
- system:time_start:1598436963648
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200829T102031_20200829T102249_T32UQD
- system:time_start:1598696776277
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200829T102031_20200829T102249_T32UQE
- system:time_start:1598696761931
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200829T102031_20200829T102249_T33UUU
- system:time_start:1598696775441
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200829T102031_20200829T102249_T33UUV
- system:time_start:1598696761380
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.771157339912396
- 1:53.19001282361873
- 0:12.77103558879404
- 1:53.18998505583035
- 0:12.77001863628758
- 1:53.188909301620235
- 0:12.762184987294857
- 1:53.17133661927857
- 0:12.757707608958569
- 1:53.16122417717277
- 0:12.555730738938792
- 1:52.69928120529021
- 0:12.358194261491986
- 1:52.23689822690607
- 0:12.349590858016148
- 1:52.21608675160477
- 0:12.349546843053414
- 1:52.21550198558227
- 0:12.350186135836818
- 1:52.21507123589608
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.771157339912396
- 1:53.19001282361873
- system:index:20200831T100559_20200831T100836_T32UQD
- system:time_start:1598868976985
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:13.168641764479014
- 1:54.07594282072079
- 0:13.168577115820348
- 1:54.07591321122711
- 0:13.168499567411065
- 1:54.07589772396526
- 0:13.16848477576376
- 1:54.07587695227676
- 0:13.164985962754706
- 1:54.06844207660716
- 0:12.959045404058578
- 1:53.615058805795165
- 0:12.757707534019781
- 1:53.16122401835523
- 0:12.733048071163141
- 1:53.10478589553952
- 0:12.732876122369643
- 1:53.102803241578165
- 0:12.73293334329074
- 1:53.102759917175284
- 0:12.732984112400624
- 1:53.10270970265352
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- system:index:20200831T100559_20200831T100836_T32UQE
- system:time_start:1598868962110
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.788456247501115
- 1:53.2291978959799
- 0:12.788423980308538
- 1:53.229179681404545
- 0:12.788380220186301
- 1:53.22918385933647
- 0:12.788351310336887
- 1:53.2291694575184
- 0:12.787465795615978
- 1:53.22860426360094
- 0:12.787446571124816
- 1:53.22857802806148
- 0:12.786631145197942
- 1:53.22694322555848
- 0:12.570832060761347
- 1:52.73394909612928
- 0:12.35968766233722
- 1:52.240591133609946
- 0:12.358155520236897
- 1:52.236777793068036
- 0:12.357401610605544
- 1:52.234590422547214
- 0:12.357487684547298
- 1:52.23314240166912
- 0:12.357549839525365
- 1:52.23310230834912
- 0:12.357606532289704
- 1:52.23305497486679
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- system:index:20200831T100559_20200831T100836_T33UUU
- system:time_start:1598868976127
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.195030665075528
- 1:54.13408663105945
- 0:13.195011250271353
- 1:54.13405907750564
- 0:13.189974256257953
- 1:54.123196390739956
- 0:13.019123891713429
- 1:53.74833315794155
- 0:12.85121275389409
- 1:53.37323518885237
- 0:12.756893843527873
- 1:53.159491668940845
- 0:12.74969705892592
- 1:53.14263042736108
- 0:12.74891287048811
- 1:53.14045603068317
- 0:12.74894230236621
- 1:53.140424543689946
- 0:12.748931886499122
- 1:53.14038553338755
- 0:12.749572926747515
- 1:53.14002349720101
- 0:12.749651489812399
- 1:53.13999852498525
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19604990286127
- 1:54.13467819748574
- 0:13.19596280170343
- 1:54.13466275069621
- 0:13.195030665075528
- 1:54.13408663105945
- system:index:20200831T100559_20200831T100836_T33UUV
- system:time_start:1598868961519
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200903T101559_20200903T101850_T32UQD
- system:time_start:1599128774215
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200903T101559_20200903T101850_T32UQE
- system:time_start:1599128759850
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200903T101559_20200903T101850_T33UUU
- system:time_start:1599128773374
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200903T101559_20200903T101850_T33UUV
- system:time_start:1599128759300
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.76398886948041
- 1:53.19023984379334
- 0:12.763853565845919
- 1:53.19020176617663
- 0:12.762800407641231
- 1:53.18859183058963
- 0:12.754972493692428
- 1:53.17102488419299
- 0:12.55701882365096
- 1:52.720559570291044
- 0:12.363312109626952
- 1:52.26967234649722
- 0:12.34190626562048
- 1:52.21901215309839
- 0:12.340823523857827
- 1:52.216335287698215
- 0:12.340779663144469
- 1:52.21575075952208
- 0:12.341419002855602
- 1:52.215320061274284
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76398886948041
- 1:53.19023984379334
- system:index:20200905T101031_20200905T101029_T32UQD
- system:time_start:1599300978211
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:13.159495820980238
- 1:54.07625994475034
- 0:13.159431616489902
- 1:54.076230450651416
- 0:13.159354277235602
- 1:54.07621535735254
- 0:13.159339298445612
- 1:54.07619469031127
- 0:13.157025241056584
- 1:54.071416696390145
- 0:13.04728497436372
- 1:53.83000831790072
- 0:12.938868369519314
- 1:53.58847116777378
- 0:12.725893513584355
- 1:53.10501029298455
- 0:12.725721892419093
- 1:53.10302762351784
- 0:12.725779155417639
- 1:53.10298438215142
- 0:12.725829818206178
- 1:53.102934183059716
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- system:index:20200905T101031_20200905T101029_T32UQE
- system:time_start:1599300963308
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.781271130469108
- 1:53.229064273801384
- 0:12.781238794163723
- 1:53.22904614871618
- 0:12.781195113073444
- 1:53.22905023174085
- 0:12.781166132985051
- 1:53.229035919661456
- 0:12.780280782767
- 1:53.22847058199984
- 0:12.780261489708527
- 1:53.22844443684786
- 0:12.779446490007368
- 1:53.226809571896325
- 0:12.568351352941754
- 1:52.74657709256459
- 0:12.361695792912057
- 1:52.265996588677254
- 0:12.349378652134831
- 1:52.23658130817327
- 0:12.348625112889989
- 1:52.23439348452583
- 0:12.348711444508785
- 1:52.232945478640815
- 0:12.348773602717586
- 1:52.2329053906267
- 0:12.348830410995706
- 1:52.232858050319095
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- system:index:20200905T101031_20200905T101029_T33UUU
- system:time_start:1599300977350
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.741753547111728
- 1:53.14002894007243
- 0:12.741809693828415
- 1:53.13995867190128
- 0:12.742176266728972
- 1:53.13985696582617
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.186807806518347
- 1:54.13453930466978
- 0:13.18584474206795
- 1:54.13394396590292
- 0:13.18498637911877
- 1:54.13229150491631
- 0:13.160686016425691
- 1:54.0796039930898
- 0:13.131461225366115
- 1:54.01550899230831
- 0:12.937487130083367
- 1:53.58486312855102
- 0:12.747312750484793
- 1:53.15391618369132
- 0:12.743310501719293
- 1:53.14466896069098
- 0:12.74171473209519
- 1:53.14085991660517
- 0:12.741711125361416
- 1:53.140837358471806
- 0:12.741753547111728
- 1:53.14002894007243
- system:index:20200905T101031_20200905T101029_T33UUV
- system:time_start:1599300962708
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200908T102031_20200908T102027_T32UQD
- system:time_start:1599560775187
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200908T102031_20200908T102027_T32UQE
- system:time_start:1599560760837
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200908T102031_20200908T102027_T33UUU
- system:time_start:1599560774350
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200908T102031_20200908T102027_T33UUV
- system:time_start:1599560760286
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.7674802725699
- 1:53.19012929803857
- 0:12.766435950304796
- 1:53.18902425922219
- 0:12.765345431295259
- 1:53.186888966628814
- 0:12.757518276922498
- 1:53.169325439728816
- 0:12.75304217632691
- 1:53.159212770455404
- 0:12.670611442028525
- 1:52.9718220518912
- 0:12.634092264393283
- 1:52.88821743208258
- 0:12.500880118658495
- 1:52.58003070569137
- 0:12.369619928002805
- 1:52.27165087750393
- 0:12.346027418539036
- 1:52.21560999917593
- 0:12.346679219677698
- 1:52.215170787336795
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20200910T100559_20200910T101115_T32UQD
- system:time_start:1599732976200
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164983314447332
- 1:54.076069714156716
- 0:13.164918788504293
- 1:54.07604008924969
- 0:13.164841244822815
- 1:54.076024599167276
- 0:13.164826456060391
- 1:54.076003826867186
- 0:13.161328255300223
- 1:54.068568835098475
- 0:12.94341487372132
- 1:53.58859119650822
- 0:12.730648663951873
- 1:53.10810796790256
- 0:12.729517418079118
- 1:53.105436047214596
- 0:12.729299073625894
- 1:53.10291552257381
- 0:12.729356296922628
- 1:53.102872200009585
- 0:12.729406956332893
- 1:53.102821999336875
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- system:index:20200910T100559_20200910T101115_T32UQE
- system:time_start:1599732961320
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.783910378826993
- 1:53.22908340696904
- 0:12.783833607266844
- 1:53.229067275939855
- 0:12.634419042610036
- 1:52.88899454828071
- 0:12.60670753958802
- 1:52.825316864310835
- 0:12.366997443956231
- 1:52.26557540014382
- 0:12.360835519413731
- 1:52.2508690112189
- 0:12.356990206380422
- 1:52.24160965898799
- 0:12.353926994270395
- 1:52.23398442579291
- 0:12.353923776789278
- 1:52.233961802165275
- 0:12.353971895893146
- 1:52.233153512588544
- 0:12.354015668480422
- 1:52.233125165657256
- 0:12.354027349532627
- 1:52.23308334812464
- 0:12.354387127274883
- 1:52.2329828058287
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.783910378826993
- 1:53.22908340696904
- system:index:20200910T100559_20200910T101115_T33UUU
- system:time_start:1599732975341
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.191361112759424
- 1:54.13403266910991
- 0:13.191341203840983
- 1:54.134006609401744
- 0:13.18879865847797
- 1:54.12911288367516
- 0:12.966561330764657
- 1:53.640111179426206
- 0:12.749275019659668
- 1:53.15071650043259
- 0:12.74527157320492
- 1:53.141466944192175
- 0:12.745268002271656
- 1:53.141444214971926
- 0:12.745338540563603
- 1:53.14009687588418
- 0:12.745383089645708
- 1:53.14006842242581
- 0:12.745394682282837
- 1:53.14002660583153
- 0:12.74574917615616
- 1:53.139928285254854
- 0:12.745796718395159
- 1:53.13992562742396
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.192378551411378
- 1:54.13462310639914
- 0:13.19229145583025
- 1:54.13460765646674
- 0:13.191361112759424
- 1:54.13403266910991
- system:index:20200910T100559_20200910T101115_T33UUV
- system:time_start:1599732960726
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200913T101629_20200913T102037_T32UQD
- system:time_start:1599992773269
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200913T101629_20200913T102037_T32UQE
- system:time_start:1599992758912
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200913T101629_20200913T102037_T33UUU
- system:time_start:1599992772429
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200913T101629_20200913T102037_T33UUV
- system:time_start:1599992758362
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.772888096433922
- 1:53.18992684362845
- 0:12.772807872127087
- 1:53.18991201641614
- 0:12.77171188179229
- 1:53.18776654109799
- 0:12.559073564304793
- 1:52.70214894660481
- 0:12.351344349141991
- 1:52.21603719177179
- 0:12.351303078422566
- 1:52.215489327679066
- 0:12.351321931749455
- 1:52.2154374618244
- 0:12.351898480364321
- 1:52.21504898478459
- 0:12.351972030439846
- 1:52.215020449072554
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.772949454149359
- 1:53.1899559993205
- 0:12.772888096433922
- 1:53.18992684362845
- system:index:20200915T101031_20200915T101550_T32UQD
- system:time_start:1600164978132
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.727982910449253
- 1:54.00783900641115
- 0:13.727349928870856
- 1:54.00826533079221
- 0:13.724455217876768
- 1:54.008963290196455
- 0:13.379497087917205
- 1:54.05602234146072
- 0:13.30258903580143
- 1:54.06635962810363
- 0:13.269093068618814
- 1:54.07079358184732
- 0:13.25187318508151
- 1:54.07302486951107
- 0:13.171261582984751
- 1:54.07585186911367
- 0:13.167729200324477
- 1:54.06834691570555
- 0:13.00553221519775
- 1:53.712814238987654
- 0:12.846194972277534
- 1:53.35700080566035
- 0:12.81228787875479
- 1:53.28037636806806
- 0:12.738084197229789
- 1:53.11111249110095
- 0:12.734680602046184
- 1:53.10307679191295
- 0:12.73534065656124
- 1:53.1026357543057
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.649875580042226
- 1:53.30555828176344
- 0:13.675544429890842
- 1:53.539657383908974
- 0:13.701576471876571
- 1:53.77373859391713
- 0:13.727982910449253
- 1:54.00783900641115
- system:index:20200915T101031_20200915T101550_T32UQE
- system:time_start:1600164963403
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.359641086698401
- 1:52.23310410788643
- 0:12.359687673546164
- 1:52.23310155253788
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790252576440476
- 1:53.229231165558666
- 0:12.790204928363787
- 1:53.229204430866744
- 0:12.790134972078334
- 1:53.229197422318755
- 0:12.78927273650194
- 1:53.22807735395234
- 0:12.78685298181914
- 1:53.22263036726486
- 0:12.575400918450413
- 1:52.73970764856926
- 0:12.368418430386926
- 1:52.25643434979444
- 0:12.359943079326225
- 1:52.23627866216085
- 0:12.359188941009041
- 1:52.23409084064184
- 0:12.35923758834168
- 1:52.23327153331405
- 0:12.359281469318907
- 1:52.233243172495655
- 0:12.359293144644694
- 1:52.23320135442415
- 0:12.359641086698401
- 1:52.23310410788643
- system:index:20200915T101031_20200915T101550_T33UUU
- system:time_start:1600164977273
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.174350634391597
- 1:54.082573343350404
- 0:13.173234932765626
- 1:54.08042169878567
- 0:12.96060586985222
- 1:53.61303939486375
- 0:12.870084405600014
- 1:53.41079476312826
- 0:12.842525387831419
- 1:53.34880352564775
- 0:12.811015679143088
- 1:53.27756154685554
- 0:12.77800730325541
- 1:53.20250536710417
- 0:12.753670281892786
- 1:53.146653704236435
- 0:12.751541426880289
- 1:53.14157544342185
- 0:12.751621859951667
- 1:53.140035807746635
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.637177539736683
- 1:53.58784358830575
- 0:13.623018997046938
- 1:54.022107801224664
- 0:13.621386925797113
- 1:54.022721801056434
- 0:13.618597523795506
- 1:54.02323396055714
- 0:13.402207198612983
- 1:54.052913570366314
- 0:13.351521117328375
- 1:54.05978017547875
- 0:13.181852141946631
- 1:54.08214546774124
- 0:13.17722651113372
- 1:54.08261692645621
- 0:13.174350634391597
- 1:54.082573343350404
- system:index:20200915T101031_20200915T101550_T33UUV
- system:time_start:1600164963165
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200918T102031_20200918T102401_T32UQD
- system:time_start:1600424775893
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200918T102031_20200918T102401_T32UQE
- system:time_start:1600424761531
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200918T102031_20200918T102401_T33UUU
- system:time_start:1600424775052
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200918T102031_20200918T102401_T33UUV
- system:time_start:1600424760980
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.354782769249859
- 1:52.21503053706143
- 0:12.354889426563327
- 1:52.2149374297044
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.777312537321633
- 1:53.18981758887346
- 0:12.77619197109222
- 1:53.18762469861242
- 0:12.761713838601185
- 1:53.155701078487596
- 0:12.61200513111006
- 1:52.81576686421944
- 0:12.464735716684654
- 1:52.47559055872282
- 0:12.436645641120577
- 1:52.410031847604365
- 0:12.382852948847185
- 1:52.28368451795941
- 0:12.378561817491107
- 1:52.27355377409457
- 0:12.354973050202455
- 1:52.2175529566109
- 0:12.354782769249859
- 1:52.21503053706143
- system:index:20200920T100649_20200920T100649_T32UQD
- system:time_start:1600596975796
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.739529010208015
- 1:53.10250764136147
- 0:12.739575940168152
- 1:53.10250254705097
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.174129191270419
- 1:54.07575224960105
- 0:13.17406621515989
- 1:54.0757233026614
- 0:13.17398406335169
- 1:54.07570875373703
- 0:13.172842126322486
- 1:54.07356793265694
- 0:12.959771021596838
- 1:53.6034313202221
- 0:12.75163538510837
- 1:53.13281257070392
- 0:12.739261528083125
- 1:53.10405072605087
- 0:12.73914386779627
- 1:53.102696164289526
- 0:12.739184267271973
- 1:53.10266558865694
- 0:12.739189935498196
- 1:53.10262335241303
- 0:12.739529010208015
- 1:53.10250764136147
- system:index:20200920T100649_20200920T100649_T32UQE
- system:time_start:1600596960925
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.361858933831531
- 1:52.233625324544235
- 0:12.361876823467359
- 1:52.23355123842134
- 0:12.36255213972577
- 1:52.23316564107286
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.794743319258213
- 1:53.229314396484966
- 0:12.794625703689277
- 1:53.22928065850543
- 0:12.793764287175392
- 1:53.22816177283815
- 0:12.792945599682609
- 1:53.226520918350744
- 0:12.643015281926711
- 1:52.886737897231825
- 0:12.495337450809064
- 1:52.54677813589216
- 0:12.432227205900212
- 1:52.399745739169084
- 0:12.379567547654036
- 1:52.27610709003198
- 0:12.365704524367356
- 1:52.24288410736449
- 0:12.361858933831531
- 1:52.233625324544235
- system:index:20200920T100649_20200920T100649_T33UUU
- system:time_start:1600596974940
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.20144232421594
- 1:54.13472775556927
- 0:13.201421828826753
- 1:54.134708788650926
- 0:13.200546132827856
- 1:54.13361126969503
- 0:13.198846901633955
- 1:54.13034245831506
- 0:13.182895183613864
- 1:54.09612224199529
- 0:12.96955368204451
- 1:53.625058548031824
- 0:12.760789183627825
- 1:53.15363086000954
- 0:12.7551881687429
- 1:53.14057791430343
- 0:12.75521654771733
- 1:53.140544453186855
- 0:12.755205789391084
- 1:53.14050397774794
- 0:12.755846849977468
- 1:53.14014198224379
- 0:12.755925414592447
- 1:53.140117005235375
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20155707068725
- 1:54.13476060723407
- 0:13.2015082251008
- 1:54.134734046054
- 0:13.20144232421594
- 1:54.13472775556927
- system:index:20200920T100649_20200920T100649_T33UUV
- system:time_start:1600596960340
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200923T101649_20200923T102104_T32UQD
- system:time_start:1600856773586
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200923T101649_20200923T102104_T32UQE
- system:time_start:1600856759223
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200923T101649_20200923T102104_T33UUU
- system:time_start:1600856772742
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200923T101649_20200923T102104_T33UUV
- system:time_start:1600856758673
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.347769210937697
- 1:52.21522994808967
- 0:12.34787576926018
- 1:52.215136859065275
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.76836104166709
- 1:53.19010145241951
- 0:12.767281558137338
- 1:53.188451560411494
- 0:12.76619440547257
- 1:53.1863227712147
- 0:12.761760857710788
- 1:53.176747193208115
- 0:12.674818091795187
- 1:52.97924728435259
- 0:12.516456594054869
- 1:52.61410745731838
- 0:12.360844359350487
- 1:52.24869534672774
- 0:12.349001451602136
- 1:52.21988985750956
- 0:12.347918423233976
- 1:52.21721341603828
- 0:12.347769210937697
- 1:52.21522994808967
- system:index:20200925T101031_20200925T101421_T32UQD
- system:time_start:1601028979136
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.166812503769583
- 1:54.0760062435302
- 0:13.166747701605761
- 1:54.075976565621964
- 0:13.166669997609345
- 1:54.07596075615255
- 0:13.166655441238731
- 1:54.07593995816858
- 0:13.056191104678318
- 1:53.834834385744585
- 0:12.9470568600264
- 1:53.593597972871876
- 0:12.732670766185048
- 1:53.11074291255418
- 0:12.73041166280243
- 1:53.1054079507449
- 0:12.730193361399712
- 1:53.102887418253026
- 0:12.730250584102496
- 1:53.102844095229145
- 0:12.730301280007529
- 1:53.10279397351804
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- system:index:20200925T101031_20200925T101421_T32UQE
- system:time_start:1601028964255
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.78576190974339
- 1:53.229147840192944
- 0:12.78564420302394
- 1:53.229114104051284
- 0:12.784783071933427
- 1:53.227995150495786
- 0:12.783150230422235
- 1:53.224720716631
- 0:12.763030077522062
- 1:53.17956784051042
- 0:12.734143465938308
- 1:53.114285187701874
- 0:12.675040610057847
- 1:52.9798923363241
- 0:12.517121759029617
- 1:52.615488542711155
- 0:12.361713348613419
- 1:52.250888351835876
- 0:12.355586461911756
- 1:52.2356410494703
- 0:12.354819376531784
- 1:52.233414697308476
- 0:12.355531149713546
- 1:52.23300849057115
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.78576190974339
- 1:53.229147840192944
- system:index:20200925T101031_20200925T101421_T33UUU
- system:time_start:1601028978276
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.746243966727993
- 1:53.14033798246312
- 0:12.74626791330633
- 1:53.14032061137235
- 0:12.746884159479345
- 1:53.1399726340833
- 0:12.74696272187911
- 1:53.13994766392143
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.194214264617418
- 1:54.134650661851175
- 0:13.194127166247771
- 1:54.1346352134902
- 0:13.19319500477349
- 1:54.1340591699634
- 0:13.19317559193162
- 1:54.13403161603816
- 0:13.174713338368027
- 1:54.09438038448693
- 0:12.961782382430288
- 1:53.6262750032665
- 0:12.753391343174437
- 1:53.15780684927289
- 0:12.746225061804365
- 1:53.1404077156468
- 0:12.7462537842714
- 1:53.14037472096942
- 0:12.746243966727993
- 1:53.14033798246312
- system:index:20200925T101031_20200925T101421_T33UUV
- system:time_start:1601028963662
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20200928T102031_20200928T102456_T32UQD
- system:time_start:1601288776725
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20200928T102031_20200928T102456_T32UQE
- system:time_start:1601288762377
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20200928T102031_20200928T102456_T33UUU
- system:time_start:1601288775885
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20200928T102031_20200928T102456_T33UUV
- system:time_start:1601288761826
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.774620233723212
- 1:53.18990299019484
- 0:12.771238438983877
- 1:53.18238328657202
- 0:12.565844626753853
- 1:52.71435774903248
- 0:12.365027343509759
- 1:52.24587805208128
- 0:12.36074416687327
- 1:52.2357462912391
- 0:12.354302902016299
- 1:52.22027889410958
- 0:12.353219553521646
- 1:52.21760240202994
- 0:12.353029402116249
- 1:52.215080468805354
- 0:12.353136062108002
- 1:52.214987363124145
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20200930T100729_20200930T101030_T32UQD
- system:time_start:1601460976932
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.172235257855526
- 1:54.07578606928755
- 0:13.172152119274287
- 1:54.07576926036386
- 0:13.167459383440292
- 1:54.06565753611301
- 0:13.129970048162772
- 1:53.98383749791901
- 0:12.932229713090365
- 1:53.54632434505639
- 0:12.738744903099322
- 1:53.108393302618865
- 0:12.736488781304043
- 1:53.10306716067803
- 0:12.736514940002683
- 1:53.10303663016535
- 0:12.73649982850077
- 1:53.10299998557563
- 0:12.737087638242237
- 1:53.1026072296976
- 0:12.737162393301833
- 1:53.102578431294155
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.17229995181673
- 1:54.07581575655729
- 0:13.172235257855526
- 1:54.07578606928755
- system:index:20200930T100729_20200930T101030_T32UQE
- system:time_start:1601460962060
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.791924667229788
- 1:53.229220859458565
- 0:12.791909433982129
- 1:53.2292002897686
- 0:12.790279054339825
- 1:53.22593200164999
- 0:12.574782329439497
- 1:52.73483934824595
- 0:12.36391702932725
- 1:52.24338392180257
- 0:12.360070583918588
- 1:52.234122176697305
- 0:12.360067326498303
- 1:52.2340994747708
- 0:12.360115302024456
- 1:52.233291183890124
- 0:12.360159072997467
- 1:52.23326283434352
- 0:12.360170747368857
- 1:52.23322101618224
- 0:12.360518690927819
- 1:52.23312376663776
- 0:12.360565278249885
- 1:52.23312121088361
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792048871934362
- 1:53.229264495186534
- 0:12.791995024195552
- 1:53.22923425782585
- 0:12.791924667229788
- 1:53.229220859458565
- system:index:20200930T100729_20200930T101030_T33UUU
- system:time_start:1601460976075
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.199626401311399
- 1:54.1347317170917
- 0:13.198710454341796
- 1:54.13358381354836
- 0:13.197859045169764
- 1:54.13194586053298
- 0:13.191973916433835
- 1:54.119451245175135
- 0:13.189456180123429
- 1:54.114019695711804
- 0:12.987823820589858
- 1:53.670137859480455
- 0:12.790278453120576
- 1:53.225930479451286
- 0:12.757343431117471
- 1:53.1508687616434
- 0:12.753338245277535
- 1:53.1416194552939
- 0:12.753334668484982
- 1:53.14159672643144
- 0:12.753409667311587
- 1:53.14015957038269
- 0:12.753530299579868
- 1:53.140071857335464
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20200930T100729_20200930T101030_T33UUV
- system:time_start:1601460961474
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201003T101759_20201003T102147_T32UQD
- system:time_start:1601720774626
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201003T101759_20201003T102147_T32UQE
- system:time_start:1601720760261
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201003T101759_20201003T102147_T33UUU
- system:time_start:1601720773783
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201003T101759_20201003T102147_T33UUV
- system:time_start:1601720759710
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201008T102031_20201008T102029_T32UQD
- system:time_start:1602152777033
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201008T102031_20201008T102029_T32UQE
- system:time_start:1602152762688
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201008T102031_20201008T102029_T33UUU
- system:time_start:1602152776195
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201008T102031_20201008T102029_T33UUV
- system:time_start:1602152762136
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.770140859337571
- 1:53.19004500632048
- 0:12.767891164113628
- 1:53.185188242173936
- 0:12.754503932006246
- 1:53.15538905910845
- 0:12.556414827332059
- 1:52.70222881891643
- 0:12.362599204571454
- 1:52.248645509213084
- 0:12.351875472120954
- 1:52.223046338791974
- 0:12.349712502642081
- 1:52.217702123720095
- 0:12.349522587445177
- 1:52.21518009579693
- 0:12.349629178592993
- 1:52.21508708362194
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20201010T101029_20201010T101151_T32UQD
- system:time_start:1602324977500
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.732030051959736
- 1:53.10289044302415
- 0:12.732035728826796
- 1:53.10284820684405
- 0:12.732386459807953
- 1:53.10272850145278
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.168641764479014
- 1:54.07594282072079
- 0:13.16858920060164
- 1:54.07591871952263
- 0:13.16851695361111
- 1:54.075915500408534
- 0:13.167467196946422
- 1:54.074843730225346
- 0:12.95861818928751
- 1:53.61534281684999
- 0:12.754503744730838
- 1:53.15538866208953
- 0:12.734319562894733
- 1:53.10907205924055
- 0:12.732060426712852
- 1:53.10373715855983
- 0:12.731989649131725
- 1:53.102921016060286
- 0:12.732030051959736
- 1:53.10289044302415
- system:index:20201010T101029_20201010T101151_T32UQE
- system:time_start:1602324962624
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.787446100866191
- 1:53.229147979791705
- 0:12.787426212076529
- 1:53.22912891921724
- 0:12.786578347968806
- 1:53.228027330940286
- 0:12.781743588294631
- 1:53.21714075586315
- 0:12.567227179588716
- 1:52.72686141002901
- 0:12.357310033402651
- 1:52.23621981932162
- 0:12.356556056899471
- 1:52.23403189763418
- 0:12.356604731063994
- 1:52.23321251233006
- 0:12.356648538498673
- 1:52.23318424281931
- 0:12.356660216687768
- 1:52.23314242501717
- 0:12.357008154225118
- 1:52.23304518749984
- 0:12.357054849420377
- 1:52.23304262172512
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.787558174922678
- 1:53.22918115744251
- 0:12.787510530626257
- 1:53.22915442145759
- 0:12.787446100866191
- 1:53.229147979791705
- system:index:20201010T101029_20201010T101151_T33UUU
- system:time_start:1602324976642
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.195132098279165
- 1:54.134664473899086
- 0:13.195083222021983
- 1:54.134637829332696
- 0:13.1950173670958
- 1:54.13463161495007
- 0:13.194996837360668
- 1:54.134612566443494
- 0:13.194120359912077
- 1:54.1335138377716
- 0:13.191598192396315
- 1:54.128074952203285
- 0:12.971381427441049
- 1:53.64369916127444
- 0:12.756025321753826
- 1:53.158935986729354
- 0:12.752020705105021
- 1:53.149689006797274
- 0:12.748828470532008
- 1:53.142073623703034
- 0:12.748824971846881
- 1:53.14205105325359
- 0:12.748928381781933
- 1:53.14007488158833
- 0:12.748991421839444
- 1:53.14003465444556
- 0:12.74904901897767
- 1:53.13998717370841
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20201010T101029_20201010T101151_T33UUV
- system:time_start:1602324962034
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201013T101909_20201013T101905_T32UQD
- system:time_start:1602584774950
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201013T101909_20201013T101905_T32UQE
- system:time_start:1602584760593
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201013T101909_20201013T101905_T33UUU
- system:time_start:1602584774109
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201013T101909_20201013T101905_T33UUV
- system:time_start:1602584760041
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:12.766677065088482
- 1:53.19015471959899
- 0:12.766614056903457
- 1:53.19012482172612
- 0:12.766538190740658
- 1:53.19010884857498
- 0:12.766524052462355
- 1:53.19008800340627
- 0:12.554659136858628
- 1:52.70794821986032
- 0:12.34765345824532
- 1:52.22532514107676
- 0:12.344411376198115
- 1:52.21731289682122
- 0:12.344262303392304
- 1:52.21532950632163
- 0:12.344318808454517
- 1:52.21528640711187
- 0:12.34436897677078
- 1:52.21523640902108
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- system:index:20201015T101031_20201015T101211_T32UQD
- system:time_start:1602756979544
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.163949111563708
- 1:54.07610555207069
- 0:13.162782515666906
- 1:54.07391768394221
- 0:13.160467910589976
- 1:54.069138997125485
- 0:13.155643694780812
- 1:54.05888089837814
- 0:13.125399551867714
- 1:53.99316983244795
- 0:13.059020025837404
- 1:53.8475564068123
- 0:13.034684033152434
- 1:53.79386899667656
- 0:13.003483769338605
- 1:53.72475604767374
- 0:12.945976428378847
- 1:53.596601857545
- 0:12.739627353233601
- 1:53.128873223920536
- 0:12.731729256243877
- 1:53.110231686031796
- 0:12.729424080068299
- 1:53.104358847854705
- 0:12.729291243089765
- 1:53.10282562519421
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.163949111563708
- 1:54.07610555207069
- system:index:20201015T101031_20201015T101211_T32UQE
- system:time_start:1602756964651
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.351346092336334
- 1:52.23331857868771
- 0:12.351369554158152
- 1:52.23330127560153
- 0:12.35197609864331
- 1:52.23295514231432
- 0:12.352053257440266
- 1:52.23293041758327
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.784863641922332
- 1:53.22913110253703
- 0:12.784778617771227
- 1:53.22911545221166
- 0:12.783872127930719
- 1:53.22853672605174
- 0:12.783853174866493
- 1:53.228509541483604
- 0:12.772538253554943
- 1:53.204022334944575
- 0:12.571873640231777
- 1:52.74718873169962
- 0:12.37522544404924
- 1:52.290039757171456
- 0:12.365959411633684
- 1:52.26825019257978
- 0:12.351327455162028
- 1:52.23338953016948
- 0:12.351355476447196
- 1:52.2333558578962
- 0:12.351346092336334
- 1:52.23331857868771
- system:index:20201015T101031_20201015T101211_T33UUU
- system:time_start:1602756978684
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.184516095683456
- 1:54.122035838996936
- 0:13.179483123642276
- 1:54.11117245186098
- 0:13.122656337463015
- 1:53.98732499223284
- 0:13.031428483227732
- 1:53.78683275662604
- 0:13.0017620942731
- 1:53.721074959032535
- 0:12.974649252025424
- 1:53.660745775157416
- 0:12.918908985623347
- 1:53.53607458175456
- 0:12.799064299766318
- 1:53.26493384041684
- 0:12.76611398734093
- 1:53.189335682895674
- 0:12.746083553348347
- 1:53.1431016490454
- 0:12.745295708004182
- 1:53.14091636433483
- 0:12.745347952912045
- 1:53.13991709819787
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619101223501275
- 1:54.14027497552418
- 0:13.19139704401529
- 1:54.13460840154566
- 0:13.190433960588182
- 1:54.13401309411085
- 0:13.187881130196018
- 1:54.12909942681998
- 0:13.184516095683456
- 1:54.122035838996936
- system:index:20201015T101031_20201015T101211_T33UUV
- system:time_start:1602756964057
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201018T102041_20201018T102429_T32UQD
- system:time_start:1603016776799
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201018T102041_20201018T102429_T32UQE
- system:time_start:1603016762447
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201018T102041_20201018T102429_T33UUU
- system:time_start:1603016775961
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201018T102041_20201018T102429_T33UUV
- system:time_start:1603016761896
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.7674802725699
- 1:53.19012929803857
- 0:12.766434782957914
- 1:53.1890230498917
- 0:12.75308936539252
- 1:53.15975141249281
- 0:12.652046762272777
- 1:52.93191942810865
- 0:12.529199247079896
- 1:52.6512352006269
- 0:12.466141672152988
- 1:52.50469128833946
- 0:12.41105004837709
- 1:52.375695574200265
- 0:12.378774081898815
- 1:52.29945168465693
- 0:12.349812855294347
- 1:52.230660337785814
- 0:12.344411376198115
- 1:52.21731289682122
- 0:12.344264887295536
- 1:52.21536371069512
- 0:12.34465974951047
- 1:52.21522814171874
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20201020T100949_20201020T100943_T32UQD
- system:time_start:1603188977455
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.165833455930095
- 1:54.07600839219092
- 0:13.165750327796799
- 1:54.07599183156708
- 0:13.158745712538565
- 1:54.061102383686915
- 0:12.947358276416544
- 1:53.59682615804955
- 0:12.740803041854036
- 1:53.1320745846032
- 0:12.731822933108619
- 1:53.11130902480791
- 0:12.72844025464409
- 1:53.10331985892267
- 0:12.72846630530846
- 1:53.103289342469225
- 0:12.728451317119173
- 1:53.10325268409541
- 0:12.729039206436834
- 1:53.102860050540116
- 0:12.729113924408946
- 1:53.102831178431714
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16589798332256
- 1:54.076038016493854
- 0:13.165833455930095
- 1:54.07600839219092
- system:index:20201020T100949_20201020T100943_T32UQE
- system:time_start:1603188962559
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.783833796039422
- 1:53.229067422526455
- 0:12.591503016963843
- 1:52.79425726382119
- 0:12.532418423214544
- 1:52.65870113320502
- 0:12.525355600306119
- 1:52.642367827338056
- 0:12.465146817933748
- 1:52.50243184714556
- 0:12.409956271438876
- 1:52.37336059082728
- 0:12.377479441492454
- 1:52.29656453237312
- 0:12.352043868862644
- 1:52.23610163589883
- 0:12.351290212860171
- 1:52.23391376117127
- 0:12.351342322444006
- 1:52.2330388786527
- 0:12.351754277566911
- 1:52.23292375950425
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- system:index:20201020T100949_20201020T100943_T33UUU
- system:time_start:1603188976594
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.744451453105611
- 1:53.1403040007153
- 0:12.744475286854078
- 1:53.14028664232511
- 0:12.74509165093512
- 1:53.139938663376746
- 0:12.745170250305895
- 1:53.13991377397505
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.193296481127124
- 1:54.13463692183664
- 0:13.193209266998384
- 1:54.134621485729525
- 0:13.19227901478411
- 1:54.13404649390586
- 0:13.192259065302766
- 1:54.13402035413957
- 0:13.19056369549095
- 1:54.130757482089855
- 0:13.185527641584843
- 1:54.11989335761589
- 0:12.962494209060743
- 1:53.63033273021657
- 0:12.744433105082496
- 1:53.14037517495662
- 0:12.744461341319758
- 1:53.14034139913528
- 0:12.744451453105611
- 1:53.1403040007153
- system:index:20201020T100949_20201020T100943_T33UUV
- system:time_start:1603188961967
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201023T102029_20201023T102450_T32UQD
- system:time_start:1603448774697
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201023T102029_20201023T102450_T32UQE
- system:time_start:1603448760344
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201023T102029_20201023T102450_T33UUU
- system:time_start:1603448773857
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201023T102029_20201023T102450_T33UUV
- system:time_start:1603448759793
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.763092871220705
- 1:53.19026814165076
- 0:12.763031452995492
- 1:53.1902390714676
- 0:12.762956680256355
- 1:53.1902251486507
- 0:12.762941258902996
- 1:53.19020460965387
- 0:12.76185574453387
- 1:53.188078576806795
- 0:12.55266204691617
- 1:52.71070638777197
- 0:12.348221294393058
- 1:52.23286474824756
- 0:12.343943283135134
- 1:52.222731996851735
- 0:12.34178118684302
- 1:52.21738750914008
- 0:12.341632129123935
- 1:52.21540404221279
- 0:12.341688635824905
- 1:52.2153609443527
- 0:12.341738806516933
- 1:52.21531094742687
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- system:index:20201025T101121_20201025T101419_T32UQD
- system:time_start:1603620979130
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.725721892419093
- 1:53.10302762351784
- 0:12.725829818206178
- 1:53.102934183059716
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.161214576864792
- 1:54.07620037090388
- 0:13.160094048952699
- 1:54.07455336660248
- 0:13.133171321807456
- 1:54.016109943664325
- 0:12.953768122260303
- 1:53.62170986626355
- 0:12.896615065764975
- 1:53.49406305629232
- 0:12.804733270084444
- 1:53.286554382291335
- 0:12.739434444767145
- 1:53.13697457055871
- 0:12.728198493583212
- 1:53.11088305768382
- 0:12.725939994059502
- 1:53.10554824516258
- 0:12.725721892419093
- 1:53.10302762351784
- system:index:20201025T101121_20201025T101419_T32UQE
- system:time_start:1603620964237
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.349109570044238
- 1:52.23286796906207
- 0:12.3491562609599
- 1:52.232865406945926
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780372953412835
- 1:53.22904757588839
- 0:12.780325432758708
- 1:53.22902082410421
- 0:12.780255373712338
- 1:53.22901382107825
- 0:12.77939436848695
- 1:53.22789483174634
- 0:12.778576195913594
- 1:53.226253888935865
- 0:12.768919706117012
- 1:53.20449365290357
- 0:12.556538530239195
- 1:52.719358093116334
- 0:12.348661227908618
- 1:52.233866410578344
- 0:12.348657907637918
- 1:52.2338435511073
- 0:12.348706149804894
- 1:52.23303526265844
- 0:12.348749959291572
- 1:52.2330069965133
- 0:12.348761646069764
- 1:52.232965179519965
- 0:12.349109570044238
- 1:52.23286796906207
- system:index:20201025T101121_20201025T101419_T33UUU
- system:time_start:1603620978269
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.187789414253729
- 1:54.134554120659864
- 0:13.187734038855233
- 1:54.13452404854737
- 0:13.187662049483745
- 1:54.1345108936469
- 0:13.18764636179736
- 1:54.13449037435977
- 0:13.185951285574184
- 1:54.1312274225787
- 0:12.952187728277032
- 1:53.618289760313274
- 0:12.897478435765061
- 1:53.49597083338676
- 0:12.830134876835022
- 1:53.34426321695939
- 0:12.80349050575895
- 1:53.283896473120194
- 0:12.741658175788533
- 1:53.14193793237114
- 0:12.74165460745764
- 1:53.14191520282053
- 0:12.74175824355034
- 1:53.13993913674539
- 0:12.74182136233082
- 1:53.13989882225985
- 0:12.741878964435294
- 1:53.13985134545421
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20201025T101121_20201025T101419_T33UUV
- system:time_start:1603620963641
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201028T102141_20201028T102429_T32UQD
- system:time_start:1603880776424
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201028T102141_20201028T102429_T32UQE
- system:time_start:1603880762069
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201028T102141_20201028T102429_T33UUU
- system:time_start:1603880775585
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201028T102141_20201028T102429_T33UUV
- system:time_start:1603880761517
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.37050184822449
- 1:52.18173285290896
- 0:13.372105677263317
- 1:52.1815828285502
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.771936243330627
- 1:53.18998809281283
- 0:12.770816023385532
- 1:53.18779522212627
- 0:12.76524946996705
- 1:53.17555736667164
- 0:12.65184894487754
- 1:52.91897328385566
- 0:12.506020720466351
- 1:52.58338641037349
- 0:12.419384740309079
- 1:52.38085115191817
- 0:12.396770398780811
- 1:52.32753688692198
- 0:12.394596357449528
- 1:52.322193660394326
- 0:12.394426428948531
- 1:52.3199753309075
- 0:12.397956746824757
- 1:52.31876361927536
- 0:12.509482394543959
- 1:52.30335395625749
- 0:13.355726044979912
- 1:52.183360350034945
- 0:13.37050184822449
- 1:52.18173285290896
- system:index:20201030T101139_20201030T101142_T32UQD
- system:time_start:1604052976318
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.734163436717635
- 1:53.102676248565736
- 0:12.73421040203596
- 1:53.102671236053084
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16955630884026
- 1:54.075911023473104
- 0:13.169467398795746
- 1:54.075900014266665
- 0:13.168476622600002
- 1:54.075382340660624
- 0:13.168437644438928
- 1:54.07535402261921
- 0:13.150842852848019
- 1:54.03708851091151
- 0:12.939977509280219
- 1:53.57116458592331
- 0:12.733942333683752
- 1:53.10475776870652
- 0:12.733778211233762
- 1:53.10286484394234
- 0:12.733818613223864
- 1:53.10283427025707
- 0:12.733824287930727
- 1:53.10279203406094
- 0:12.734163436717635
- 1:53.102676248565736
- system:index:20201030T101139_20201030T101142_T32UQE
- system:time_start:1604052961878
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.78924610020559
- 1:53.229212535684496
- 0:12.786770139405228
- 1:53.22424852066212
- 0:12.654744209733991
- 1:52.92554418887611
- 0:12.596896652563714
- 1:52.793287529731934
- 0:12.503347330349214
- 1:52.577161538234904
- 0:12.419232543416143
- 1:52.38057794888244
- 0:12.394448126357524
- 1:52.32229827314188
- 0:12.393677502486414
- 1:52.320071598755625
- 0:12.395589623774038
- 1:52.31898137090115
- 0:12.471508434905278
- 1:52.30848540216869
- 0:12.546899619394274
- 1:52.298205839231734
- 0:12.598323370496532
- 1:52.29116999693625
- 0:12.763564895022649
- 1:52.268518531529175
- 0:12.940126803135238
- 1:52.24475334609435
- 0:12.9467358026076
- 1:52.24477837182783
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- system:index:20201030T101139_20201030T101142_T33UUU
- system:time_start:1604052975693
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19604990286127
- 1:54.13467819748574
- 0:13.196001064951137
- 1:54.134651633614766
- 0:13.195935169493893
- 1:54.1346453395772
- 0:13.195914795786361
- 1:54.13462635846661
- 0:13.195039106754708
- 1:54.13352881572118
- 0:13.193340456219286
- 1:54.13025999786156
- 0:13.184940046100769
- 1:54.11233371330071
- 0:12.968219737130276
- 1:53.6339361122742
- 0:12.756222059399407
- 1:53.155163266515565
- 0:12.750621216082857
- 1:53.14210760627187
- 0:12.750617528010293
- 1:53.14208488941601
- 0:12.750720871580338
- 1:53.14010879674193
- 0:12.75078398670272
- 1:53.14006847682912
- 0:12.750841469374514
- 1:53.14002100740641
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20201030T101139_20201030T101142_T33UUV
- system:time_start:1604052961287
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201102T102159_20201102T102502_T32UQD
- system:time_start:1604312773812
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201102T102159_20201102T102502_T32UQE
- system:time_start:1604312759457
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201102T102159_20201102T102502_T33UUU
- system:time_start:1604312772970
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201102T102159_20201102T102502_T33UUV
- system:time_start:1604312758906
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.762088605236439
- 1:53.19029992829557
- 0:12.76100856859534
- 1:53.188648724358224
- 0:12.74988342385962
- 1:53.164169992181286
- 0:12.746539637275427
- 1:53.1567195835545
- 0:12.54383926765082
- 1:52.69505059589608
- 0:12.345590205462823
- 1:52.23293945755283
- 0:12.341312682841163
- 1:52.22280661238154
- 0:12.339150963101364
- 1:52.21746206476813
- 0:12.339001955966916
- 1:52.21547859993954
- 0:12.339108637374071
- 1:52.21538550766826
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20201104T101211_20201104T101418_T32UQD
- system:time_start:1604484978620
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.158581207954619
- 1:54.07629158574562
- 0:13.15849227245626
- 1:54.076280486718765
- 0:13.157467951519692
- 1:54.075745058500765
- 0:13.153958953911875
- 1:54.06828432730165
- 0:13.118850282071223
- 1:53.991775687718665
- 0:12.930761183986375
- 1:53.57443651918019
- 0:12.746539412673387
- 1:53.156719107103
- 0:12.724104843291661
- 1:53.105066263753066
- 0:12.72393336962833
- 1:53.10308366671144
- 0:12.724041298286535
- 1:53.1029902279641
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.158581207954619
- 1:54.07629158574562
- system:index:20201104T101211_20201104T101418_T32UQE
- system:time_start:1604484963717
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.346127854205575
- 1:52.232909316782425
- 0:12.346159064506205
- 1:52.23289744937118
- 0:12.346476767965262
- 1:52.23280871764712
- 0:12.346523347694891
- 1:52.23280616838189
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.77857670716757
- 1:53.22901406440335
- 0:12.778521898738658
- 1:53.228983258050285
- 0:12.778445322952296
- 1:53.22896752028133
- 0:12.775207011117095
- 1:53.221874325344345
- 0:12.559057801946816
- 1:52.72993067024721
- 0:12.347559660510997
- 1:52.23762118749464
- 0:12.346028292357186
- 1:52.233806991197966
- 0:12.34602497075842
- 1:52.233784378890725
- 0:12.346073274456174
- 1:52.23297609100887
- 0:12.346117049116767
- 1:52.2329477474403
- 0:12.346127854205575
- 1:52.232909316782425
- system:index:20201104T101211_20201104T101418_T33UUU
- system:time_start:1604484977759
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.184940804514028
- 1:54.13451122172273
- 0:13.18402537382218
- 1:54.13336311189858
- 0:13.182327531615725
- 1:54.13009406652412
- 0:13.177293660112413
- 1:54.119229607369604
- 0:13.120462877871216
- 1:53.9953810810578
- 0:13.08886239107864
- 1:53.925843139537854
- 0:12.915659409808782
- 1:53.54025225502483
- 0:12.745491442959095
- 1:53.15442114502365
- 0:12.74148943857984
- 1:53.14517389141049
- 0:12.739889671494183
- 1:53.14135481426059
- 0:12.739963904104046
- 1:53.139939335243994
- 0:12.740383758161366
- 1:53.13982292419575
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20201104T101211_20201104T101418_T33UUV
- system:time_start:1604484963119
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201107T102231_20201107T102337_T32UQD
- system:time_start:1604744775672
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201107T102231_20201107T102337_T32UQE
- system:time_start:1604744761323
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201107T102231_20201107T102337_T33UUU
- system:time_start:1604744774835
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201107T102231_20201107T102337_T33UUV
- system:time_start:1604744760771
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.771094324550164
- 1:53.18998292866453
- 0:12.77101305172623
- 1:53.18996587585015
- 0:12.758697262184427
- 1:53.16227235367552
- 0:12.75422186181191
- 1:53.15215976045286
- 0:12.553941787098406
- 1:52.69366836957713
- 0:12.358031371962662
- 1:52.234743974463534
- 0:12.350467494463807
- 1:52.216061616308714
- 0:12.350406000409583
- 1:52.21524500448177
- 0:12.350445905956233
- 1:52.21521452364345
- 0:12.35045189068122
- 1:52.21517233370591
- 0:12.350796687962411
- 1:52.21505389958939
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.771157339912396
- 1:53.19001282361873
- 0:12.771094324550164
- 1:53.18998292866453
- system:index:20201109T101239_20201109T101557_T32UQD
- system:time_start:1604916975316
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.6618661864499
- 1:53.41532301118579
- 0:13.661730559055208
- 1:53.4156322704343
- 0:13.661255050505707
- 1:53.41595612701641
- 0:13.630066427709004
- 1:53.420415855256074
- 0:13.570339489864095
- 1:53.42885069806247
- 0:13.459055855036848
- 1:53.4442098177743
- 0:12.989436870478286
- 1:53.50725799873637
- 0:12.950978646012517
- 1:53.51231514584983
- 0:12.92861080644637
- 1:53.51521220509373
- 0:12.916865984775459
- 1:53.51668757450463
- 0:12.915800929635788
- 1:53.51557540328233
- 0:12.914693720596535
- 1:53.51344170013042
- 0:12.836405899651389
- 1:53.33842747784324
- 0:12.810444187550452
- 1:53.27989574701614
- 0:12.743019384892886
- 1:53.12660809493946
- 0:12.735167319656824
- 1:53.10850569576762
- 0:12.732892010488959
- 1:53.103132980301964
- 0:12.733552151277788
- 1:53.10269186179156
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.6618661864499
- 1:53.41532301118579
- system:index:20201109T101239_20201109T101557_T32UQE
- system:time_start:1604916964879
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35748949913392
- 1:52.23345630814721
- 0:12.35751299524745
- 1:52.23343908220483
- 0:12.35811941611142
- 1:52.23309292422743
- 0:12.358196576669535
- 1:52.23306819483536
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.788456247501115
- 1:53.2291978959799
- 0:12.788402405460927
- 1:53.22916765667079
- 0:12.788332053127737
- 1:53.229154255796104
- 0:12.788316936355251
- 1:53.2291336731765
- 0:12.785872143289488
- 1:53.22423185723062
- 0:12.783455817853445
- 1:53.218790967420176
- 0:12.568144889917033
- 1:52.7263407439205
- 0:12.3574709444746
- 1:52.233527417706384
- 0:12.35749885212109
- 1:52.23349375543374
- 0:12.35748949913392
- 1:52.23345630814721
- system:index:20201109T101239_20201109T101557_T33UUU
- system:time_start:1604916974457
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.752133301806646
- 1:53.1475334203472
- 0:12.750536923790543
- 1:53.14372506526218
- 0:12.749748845312487
- 1:53.141540041003296
- 0:12.749829353607915
- 1:53.14000190845017
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.642605325610754
- 1:53.418300195580166
- 0:13.638613773550393
- 1:53.41920166638647
- 0:13.601964400573362
- 1:53.42436610861789
- 0:13.559321058440366
- 1:53.43033179782792
- 0:13.491251997261017
- 1:53.43973953550152
- 0:13.013982492579498
- 1:53.50395931259683
- 0:12.919258391172121
- 1:53.51637514729379
- 0:12.916433297965431
- 1:53.5163259240857
- 0:12.915321480221278
- 1:53.514897744670705
- 0:12.869128531815804
- 1:53.411856640525215
- 0:12.835893343600496
- 1:53.337355093858704
- 0:12.808428459951756
- 1:53.275356236179206
- 0:12.783455742665199
- 1:53.21879080849969
- 0:12.752133301806646
- 1:53.1475334203472
- system:index:20201109T101239_20201109T101557_T33UUV
- system:time_start:1604916964418
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201112T102259_20201112T102318_T32UQD
- system:time_start:1605176772172
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201112T102259_20201112T102318_T32UQE
- system:time_start:1605176757806
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201112T102259_20201112T102318_T33UUU
- system:time_start:1605176771329
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201112T102259_20201112T102318_T33UUV
- system:time_start:1605176757255
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.762975637641551
- 1:53.19027186084791
- 0:12.760771157427437
- 1:53.18595426047417
- 0:12.617609732022931
- 1:52.8617378662393
- 0:12.576947661696726
- 1:52.768529652220444
- 0:12.428969625719624
- 1:52.42482595194615
- 0:12.376221051865832
- 1:52.30060406852305
- 0:12.356905252804385
- 1:52.254744007107085
- 0:12.351542667548783
- 1:52.24194443452933
- 0:12.344024140812545
- 1:52.22380891704067
- 0:12.340767653782507
- 1:52.21575877928177
- 0:12.341419002855602
- 1:52.215320061274284
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20201114T101301_20201114T101418_T32UQD
- system:time_start:1605348977357
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.159495820980238
- 1:54.07625994475034
- 0:13.15943095151011
- 1:54.07623010158484
- 0:13.159353140144074
- 1:54.076214299447535
- 0:13.159338706442147
- 1:54.07619348727044
- 0:13.049357146390944
- 1:53.83493056951388
- 0:12.940701114612272
- 1:53.59353782995718
- 0:12.727257583853055
- 1:53.11037306941138
- 0:12.724999175439674
- 1:53.105038031937895
- 0:12.72482764558999
- 1:53.10305568870727
- 0:12.724884871855402
- 1:53.10301236844161
- 0:12.724935572812791
- 1:53.10296224910445
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- system:index:20201114T101301_20201114T101418_T32UQE
- system:time_start:1605348962458
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780264659775597
- 1:53.22904556725041
- 0:12.777789975222518
- 1:53.224081603028885
- 0:12.768919705272866
- 1:53.20449390358952
- 0:12.620394009022023
- 1:52.86821328249309
- 0:12.565882472177268
- 1:52.74301946240901
- 0:12.428991899823208
- 1:52.425034587191234
- 0:12.377880672999485
- 1:52.30466706045602
- 0:12.356285332220699
- 1:52.25346503768006
- 0:12.348596949152205
- 1:52.23494400144525
- 0:12.348593699927045
- 1:52.23492129870144
- 0:12.348711444508785
- 1:52.232945478640815
- 0:12.348830410995706
- 1:52.232858050319095
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20201114T101301_20201114T101418_T33UUU
- system:time_start:1605348976496
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.740912498166937
- 1:53.139944966476754
- 0:12.740944269707937
- 1:53.13993308993349
- 0:12.741267903893888
- 1:53.139843307044224
- 0:12.74131544378898
- 1:53.13984065130719
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.185953731615303
- 1:54.13452646324274
- 0:13.185898359116438
- 1:54.13449639011354
- 0:13.185820816716507
- 1:54.134482243423214
- 0:13.184962800203074
- 1:54.132830493118604
- 0:12.960355696059304
- 1:53.63703881960439
- 0:12.74081843108885
- 1:53.14084310680595
- 0:12.740814826009252
- 1:53.14082029816503
- 0:12.740857268990482
- 1:53.14001187985001
- 0:12.740901856765294
- 1:53.1399835076998
- 0:12.740912498166937
- 1:53.139944966476754
- system:index:20201114T101301_20201114T101418_T33UUV
- system:time_start:1605348961860
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201117T102321_20201117T102427_T32UQD
- system:time_start:1605608774209
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201117T102321_20201117T102427_T32UQE
- system:time_start:1605608759865
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201117T102321_20201117T102427_T33UUU
- system:time_start:1605608773371
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201117T102321_20201117T102427_T33UUV
- system:time_start:1605608759313
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.351275923202813
- 1:52.21513030329841
- 0:12.351382585872479
- 1:52.21503719929329
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.773728295885327
- 1:53.18993134663458
- 0:12.772607973560685
- 1:53.187738328810454
- 0:12.76925764214205
- 1:53.180287406973925
- 0:12.568918728892536
- 1:52.7247887907358
- 0:12.37292649964182
- 1:52.26885811165166
- 0:12.364353902271944
- 1:52.24859549583864
- 0:12.358989996544008
- 1:52.23579624078704
- 0:12.352549379872531
- 1:52.22032881584851
- 0:12.351466048459317
- 1:52.217652232978196
- 0:12.351275923202813
- 1:52.21513030329841
- system:index:20201119T101319_20201119T101320_T32UQD
- system:time_start:1605780974472
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.167476379918266
- 1:54.074853113718
- 0:13.167461940236361
- 1:54.074832303156235
- 0:12.952960897769696
- 1:53.598529649246885
- 0:12.74349246246505
- 1:53.12173573978707
- 0:12.7355945014784
- 1:53.10309522884516
- 0:12.735620660737254
- 1:53.10306469853201
- 0:12.735605587727475
- 1:53.10302813312812
- 0:12.73619340216454
- 1:53.10263538202335
- 0:12.736268044170751
- 1:53.10260659651975
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.168641764479014
- 1:54.07594282072079
- 0:13.16858920060164
- 1:54.07591871952263
- 0:13.16851695361111
- 1:54.075915500408534
- 0:13.167476379918266
- 1:54.074853113718
- system:index:20201119T101319_20201119T101320_T32UQE
- system:time_start:1605780959597
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.791096948158653
- 1:53.229217630049774
- 0:12.791021107478974
- 1:53.22920324043717
- 0:12.788566314676922
- 1:53.224281890799425
- 0:12.584478970520049
- 1:52.76039464529187
- 0:12.384542514539273
- 1:52.29618185594488
- 0:12.363693308731571
- 1:52.24715599451592
- 0:12.359847552971003
- 1:52.23789659383419
- 0:12.35831530897816
- 1:52.234082765750905
- 0:12.35831197858626
- 1:52.23406015394082
- 0:12.358359995136032
- 1:52.23325186343159
- 0:12.358403766570408
- 1:52.23322351463223
- 0:12.3584154783947
- 1:52.23318177519117
- 0:12.358775338151453
- 1:52.233081127164496
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.791150680901357
- 1:53.22924788026149
- 0:12.791096948158653
- 1:53.229217630049774
- system:index:20201119T101319_20201119T101320_T33UUU
- system:time_start:1605780973615
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.195132098279165
- 1:54.134664473899086
- 0:13.195083222021983
- 1:54.134637829332696
- 0:13.1950173670958
- 1:54.13463161495007
- 0:13.194996837360668
- 1:54.134612566443494
- 0:13.194121305700389
- 1:54.133515002344765
- 0:13.19327009213956
- 1:54.131876847184465
- 0:13.19075092465132
- 1:54.12644409558488
- 0:12.971562495203065
- 1:53.63992621617124
- 0:12.757231019148954
- 1:53.15302445948212
- 0:12.753226041153546
- 1:53.14377616972123
- 0:12.75243776067992
- 1:53.14159091822959
- 0:12.752513403914296
- 1:53.14014268021809
- 0:12.75257651830457
- 1:53.14010235921986
- 0:12.752633999732321
- 1:53.140054888816344
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20201119T101319_20201119T101320_T33UUV
- system:time_start:1605780959006
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201122T102339_20201122T102335_T32UQD
- system:time_start:1606040771630
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201122T102339_20201122T102335_T32UQE
- system:time_start:1606040757277
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201122T102339_20201122T102335_T33UUU
- system:time_start:1606040770790
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201122T102339_20201122T102335_T33UUV
- system:time_start:1606040756726
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:12.763092871220705
- 1:53.19026814165076
- 0:12.763029868778156
- 1:53.1902382414433
- 0:12.762953893958235
- 1:53.19022227788378
- 0:12.762939758495056
- 1:53.190201432135034
- 0:12.551113721123496
- 1:52.7080545427186
- 0:12.344145828030873
- 1:52.22542469868609
- 0:12.340904388831511
- 1:52.21741234630386
- 0:12.340755384541932
- 1:52.21542887620287
- 0:12.340811891789077
- 1:52.21538577879267
- 0:12.340862063272986
- 1:52.2153357822552
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- system:index:20201124T101341_20201124T101416_T32UQD
- system:time_start:1606212975333
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.160299948843099
- 1:54.07623202711182
- 0:13.159179477620043
- 1:54.07458501115303
- 0:13.093764343978679
- 1:53.93218748091374
- 0:13.058892186600454
- 1:53.85565621565239
- 0:13.027601254811723
- 1:53.786551677719714
- 0:12.995256284902508
- 1:53.71477686829736
- 0:12.838632318551877
- 1:53.363181034498
- 0:12.740563416759121
- 1:53.139637443063606
- 0:12.728198493583212
- 1:53.11088305768382
- 0:12.725939994059502
- 1:53.10554824516258
- 0:12.725714109202334
- 1:53.1029378048664
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20201124T101341_20201124T101416_T32UQE
- system:time_start:1606212960436
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.780261010229578
- 1:53.22901437786359
- 0:12.780241089756851
- 1:53.22899523635428
- 0:12.779393426369044
- 1:53.22789359724922
- 0:12.575401045335655
- 1:52.763716241703634
- 0:12.37556247753233
- 1:52.299219975235026
- 0:12.347783632273828
- 1:52.233846660264454
- 0:12.347780312637587
- 1:52.233823800757904
- 0:12.347828465552668
- 1:52.23301552413117
- 0:12.347872385028063
- 1:52.23298724672701
- 0:12.347884072760488
- 1:52.23294542982361
- 0:12.348231995226595
- 1:52.23284822237209
- 0:12.34827857590576
- 1:52.23284567229584
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780372953412835
- 1:53.22904757588839
- 0:12.780325432758708
- 1:53.22902082410421
- 0:12.780261010229578
- 1:53.22901437786359
- system:index:20201124T101341_20201124T101416_T33UUU
- system:time_start:1606212974472
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.740848010673597
- 1:53.14030696939146
- 0:12.740865472872924
- 1:53.140232637934844
- 0:12.741551978750078
- 1:53.13984510703108
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.187725672183095
- 1:54.13455316996697
- 0:13.186762580504947
- 1:54.133957840073
- 0:13.184210134253307
- 1:54.12904376492756
- 0:13.166603407868076
- 1:54.091020891884305
- 0:13.089874096629915
- 1:53.92370189484349
- 0:13.056702246176139
- 1:53.85089262124517
- 0:13.024476542531744
- 1:53.77970628411036
- 0:12.952161526534985
- 1:53.618828629365254
- 0:12.839851690990727
- 1:53.36601720927044
- 0:12.740848010673597
- 1:53.14030696939146
- system:index:20201124T101341_20201124T101416_T33UUV
- system:time_start:1606212959840
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201127T102401_20201127T102424_T32UQD
- system:time_start:1606472771948
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201127T102401_20201127T102424_T32UQE
- system:time_start:1606472757597
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201127T102401_20201127T102424_T33UUU
- system:time_start:1606472771109
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201127T102401_20201127T102424_T33UUV
- system:time_start:1606472757045
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.770199960291185
- 1:53.19001210631245
- 0:12.770119702054256
- 1:53.18999719750515
- 0:12.769023842360808
- 1:53.18785177864442
- 0:12.556524445470476
- 1:52.70357482775164
- 0:12.348920497902956
- 1:52.218813164335444
- 0:12.347837435873322
- 1:52.21613635959843
- 0:12.347796217770979
- 1:52.21558898640418
- 0:12.347815185452808
- 1:52.215537109379014
- 0:12.348391641300296
- 1:52.215148662523
- 0:12.348465191336654
- 1:52.215120129257784
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.770261276279463
- 1:53.19004118427518
- 0:12.770199960291185
- 1:53.19001210631245
- system:index:20201129T101359_20201129T101355_T32UQD
- system:time_start:1606644973435
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16670208283728
- 1:54.076010142227425
- 0:13.165581371223277
- 1:54.07436327509052
- 0:13.16089721674581
- 1:54.06426593947956
- 0:13.105919003631994
- 1:53.94418510644955
- 0:13.08146071225583
- 1:53.8905099772636
- 0:12.911334928795148
- 1:53.51139114381382
- 0:12.744382448062339
- 1:53.13196166840116
- 0:12.733094746951584
- 1:53.10532374856023
- 0:12.732876122369643
- 1:53.102803241578165
- 0:12.732984112400624
- 1:53.10270970265352
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20201129T101359_20201129T101355_T32UQE
- system:time_start:1606644958552
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.355848081084241
- 1:52.23301842077826
- 0:12.355872336922316
- 1:52.23301609523498
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.787558174922678
- 1:53.22918115744251
- 0:12.787504334307213
- 1:53.22915091764642
- 0:12.787433907179514
- 1:53.22913760797453
- 0:12.787418791132769
- 1:53.22911702521373
- 0:12.784974120196056
- 1:53.22421510639067
- 0:12.78255789273315
- 1:53.218774285045036
- 0:12.566783445902074
- 1:52.72685235142545
- 0:12.355650276802294
- 1:52.234562898156234
- 0:12.355646951460228
- 1:52.234540038786584
- 0:12.355732446442019
- 1:52.23310303528809
- 0:12.355794602066517
- 1:52.233062943029246
- 0:12.355848081084241
- 1:52.23301842077826
- system:index:20201129T101359_20201129T101355_T33UUU
- system:time_start:1606644972577
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.194214264617418
- 1:54.134650661851175
- 0:13.194127166247771
- 1:54.1346352134902
- 0:13.193187469483027
- 1:54.134054421299396
- 0:13.191481656057586
- 1:54.13077163642898
- 0:13.18811573058138
- 1:54.12370809991309
- 0:13.112924294838123
- 1:53.959664750416216
- 0:13.080523505361787
- 1:53.888493217747744
- 0:13.058162656866244
- 1:53.83904968582343
- 0:13.022658826255764
- 1:53.7602580935651
- 0:12.74882854538616
- 1:53.14207378248648
- 0:12.748824971846881
- 1:53.14205105325359
- 0:12.748928381781933
- 1:53.14007488158833
- 0:12.74904901897767
- 1:53.13998717370841
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.194214264617418
- 1:54.134650661851175
- system:index:20201129T101359_20201129T101355_T33UUV
- system:time_start:1606644957962
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201202T102409_20201202T102422_T32UQD
- system:time_start:1606904770340
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201202T102409_20201202T102422_T32UQE
- system:time_start:1606904755985
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201202T102409_20201202T102422_T33UUU
- system:time_start:1606904769500
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201202T102409_20201202T102422_T33UUV
- system:time_start:1606904755434
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.766677065088482
- 1:53.19015471959899
- 0:12.766615754685976
- 1:53.19012563936433
- 0:12.766540977459957
- 1:53.19011171923249
- 0:12.7665255532733
- 1:53.19009118085971
- 0:12.765439803528421
- 1:53.18796527407601
- 0:12.556782488723972
- 1:52.71220171448064
- 0:12.35285027633222
- 1:52.23597111297223
- 0:12.347491219494412
- 1:52.223170899385366
- 0:12.345328731203624
- 1:52.21782659993941
- 0:12.345139045960408
- 1:52.215304563442444
- 0:12.345195550476138
- 1:52.21526146378286
- 0:12.345245608300726
- 1:52.215211476929646
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- system:index:20201204T101411_20201204T101413_T32UQD
- system:time_start:1607076972458
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.164068809945578
- 1:54.076101470931754
- 0:13.163944125837071
- 1:54.07607413194085
- 0:13.162895982655156
- 1:54.0750039288296
- 0:13.161759945327114
- 1:54.07287317296027
- 0:13.157078406592131
- 1:54.06277900963183
- 0:12.97352490618905
- 1:53.65802355698112
- 0:12.793644102858558
- 1:53.252908355401075
- 0:12.729567763479844
- 1:53.10598309580114
- 0:12.728420599651812
- 1:53.10327328076316
- 0:12.729080691059844
- 1:53.10283228068051
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164068809945578
- 1:54.076101470931754
- system:index:20201204T101411_20201204T101413_T32UQE
- system:time_start:1607076957566
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35262005065044
- 1:52.2329467890473
- 0:12.352666743468452
- 1:52.232944225305175
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.783918010213545
- 1:53.22908767398449
- 0:12.783847947235747
- 1:53.22908067344593
- 0:12.782986782390521
- 1:53.22796171620125
- 0:12.78135404075254
- 1:53.22468726342214
- 0:12.565580417867071
- 1:52.73249259001126
- 0:12.354453113273083
- 1:52.23993423902325
- 0:12.352921359587896
- 1:52.236120877131356
- 0:12.352167850981617
- 1:52.233933480883316
- 0:12.352216629109822
- 1:52.23311409652528
- 0:12.352260437684798
- 1:52.2330858288843
- 0:12.352272120645715
- 1:52.233044011531376
- 0:12.35262005065044
- 1:52.2329467890473
- system:index:20201204T101411_20201204T101413_T33UUU
- system:time_start:1607076971598
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.190542880403852
- 1:54.134595518088794
- 0:13.190494050171086
- 1:54.134568951527584
- 0:13.190428199755917
- 1:54.134562734186666
- 0:13.190407673806062
- 1:54.13454368472045
- 0:13.18953222607973
- 1:54.13344609210807
- 0:13.188681170263246
- 1:54.13180790833926
- 0:13.181128888455124
- 1:54.115512136444394
- 0:12.987391085802273
- 1:53.688739981241
- 0:12.797432716972297
- 1:53.26166707658272
- 0:12.745243407415552
- 1:53.142005948190224
- 0:12.7452397990636
- 1:53.141983139405255
- 0:12.745343340786802
- 1:53.140007060229685
- 0:12.745406458104528
- 1:53.13996674357317
- 0:12.745463944507522
- 1:53.13991927709296
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20201204T101411_20201204T101413_T33UUV
- system:time_start:1607076956970
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201207T102411_20201207T102440_T32UQD
- system:time_start:1607336768771
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201207T102411_20201207T102440_T32UQE
- system:time_start:1607336754419
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201207T102411_20201207T102440_T33UUU
- system:time_start:1607336767931
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201207T102411_20201207T102440_T33UUV
- system:time_start:1607336753868
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.768347851467668
- 1:53.1901018006045
- 0:12.764967184020316
- 1:53.18258197763183
- 0:12.648196047348659
- 1:52.91800628522155
- 0:12.60518706068903
- 1:52.81948218877046
- 0:12.578814849293673
- 1:52.75875910545408
- 0:12.533929598236758
- 1:52.654871662120605
- 0:12.457808217486008
- 1:52.47741233907961
- 0:12.381244845733187
- 1:52.29722221365861
- 0:12.356562051557862
- 1:52.238563741902155
- 0:12.350121709827816
- 1:52.22309615671976
- 0:12.347958954771382
- 1:52.21775190556992
- 0:12.347762378589895
- 1:52.215140073927536
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20201209T101409_20201209T101555_T32UQD
- system:time_start:1607508971438
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.652057779032736
- 1:53.325588395395684
- 0:13.65052901719416
- 1:53.32622208132926
- 0:13.629243787392324
- 1:53.32975419749934
- 0:13.608818850175812
- 1:53.332706251783726
- 0:13.432807211979432
- 1:53.3572015872401
- 0:12.923962774795067
- 1:53.425776124426896
- 0:12.879299242770891
- 1:53.43155588176614
- 0:12.876475392984624
- 1:53.43164772870412
- 0:12.875384530071125
- 1:53.42999797085104
- 0:12.873139381924187
- 1:53.42520874750698
- 0:12.843739025758708
- 1:53.359778636133434
- 0:12.789666441356442
- 1:53.23846402669796
- 0:12.739253315202633
- 1:53.12456803427484
- 0:12.733658625646541
- 1:53.1117912408748
- 0:12.730271852004433
- 1:53.103793302231146
- 0:12.730196268406871
- 1:53.10292163347871
- 0:12.73059793287861
- 1:53.10278464885393
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20201209T101409_20201209T101555_T32UQE
- system:time_start:1607508961727
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.785653494850123
- 1:53.229145849660874
- 0:12.784807166579988
- 1:53.227448795642665
- 0:12.679849108578127
- 1:52.99023671698752
- 0:12.606025253088161
- 1:52.821526615722135
- 0:12.578395217378691
- 1:52.75784267998789
- 0:12.500662827525716
- 1:52.57764442601611
- 0:12.464760099356937
- 1:52.49379072059792
- 0:12.378676789262244
- 1:52.29119546804838
- 0:12.359399786258136
- 1:52.245441111678396
- 0:12.35555456790883
- 1:52.23618029452112
- 0:12.354800684291373
- 1:52.23399252715427
- 0:12.354852705074116
- 1:52.23311764382573
- 0:12.355264777101148
- 1:52.23300249879705
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20201209T101409_20201209T101555_T33UUU
- system:time_start:1607508970579
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.645522574396423
- 1:53.32645601646053
- 0:13.64533175384498
- 1:53.326674037984795
- 0:13.643911913436733
- 1:53.32721772158817
- 0:13.62939126726891
- 1:53.329753254882554
- 0:13.604946380710999
- 1:53.33324614562637
- 0:13.569637413114489
- 1:53.3382219198989
- 0:13.473632967696377
- 1:53.35159591117275
- 0:12.991865148414703
- 1:53.41674298454298
- 0:12.8791472970638
- 1:53.43151894989965
- 0:12.876327838900181
- 1:53.431468838985424
- 0:12.875435526092195
- 1:53.43031858110056
- 0:12.87461009002942
- 1:53.428678205590245
- 0:12.791242209399048
- 1:53.242132361739436
- 0:12.78640818427095
- 1:53.23125344543276
- 0:12.746202772184242
- 1:53.14035739303837
- 0:12.746929451490418
- 1:53.13994702015168
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20201209T101409_20201209T101555_T33UUV
- system:time_start:1607508961279
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201212T102329_20201212T102356_T32UQD
- system:time_start:1607768768092
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201212T102329_20201212T102356_T32UQE
- system:time_start:1607768753727
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201212T102329_20201212T102356_T33UUU
- system:time_start:1607768767250
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201212T102329_20201212T102356_T33UUV
- system:time_start:1607768753176
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201217T102431_20201217T102432_T32UQD
- system:time_start:1608200769121
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201217T102431_20201217T102432_T32UQE
- system:time_start:1608200754759
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201217T102431_20201217T102432_T33UUU
- system:time_start:1608200768277
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201217T102431_20201217T102432_T33UUV
- system:time_start:1608200754208
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.782713053154616
- 1:53.18964595197851
- 0:12.78166827366903
- 1:53.18854106330814
- 0:12.780577006120328
- 1:53.186405841107366
- 0:12.570236177873307
- 1:52.708289088514455
- 0:12.364681335186244
- 1:52.229697895708455
- 0:12.360399915498919
- 1:52.21956578345196
- 0:12.359316019133633
- 1:52.21688914833231
- 0:12.359166222059246
- 1:52.21490571010593
- 0:12.359272908207144
- 1:52.214812677078754
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20201219T101329_20201219T101331_T32UQD
- system:time_start:1608372969618
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.179552991406052
- 1:54.07556359177047
- 0:13.178503520145842
- 1:54.07501530194997
- 0:13.176175155752414
- 1:54.07021263191004
- 0:13.118789723109813
- 1:53.9448231114725
- 0:12.94123737813306
- 1:53.550614744047486
- 0:12.76713279792518
- 1:53.156068600068885
- 0:12.745806197886552
- 1:53.10709163546913
- 0:12.744674007929516
- 1:53.10441989883924
- 0:12.744501605640378
- 1:53.10243759522567
- 0:12.744609501262776
- 1:53.10234413680809
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20201219T101329_20201219T101331_T32UQE
- system:time_start:1608372954752
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.800132273537326
- 1:53.22941400928025
- 0:12.800084611601811
- 1:53.229387279330716
- 0:12.8000202827751
- 1:53.22938083329877
- 0:12.800000383642763
- 1:53.22936177528467
- 0:12.7991530262902
- 1:53.22826151958272
- 0:12.7975191213562
- 1:53.2249871823651
- 0:12.592148921308993
- 1:52.758392644257775
- 0:12.390980035708234
- 1:52.29146825024798
- 0:12.36781046749157
- 1:52.236994176482916
- 0:12.367055914719604
- 1:52.234806300530316
- 0:12.367141694239294
- 1:52.233358264357875
- 0:12.367203845658409
- 1:52.23331816520175
- 0:12.367260532090347
- 1:52.23327082643053
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20201219T101329_20201219T101331_T33UUU
- system:time_start:1608372968762
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.760594196683927
- 1:53.14064556820512
- 0:12.760583506021446
- 1:53.140605252194675
- 0:12.761224438706272
- 1:53.14024323582241
- 0:12.761303004647617
- 1:53.14021825470593
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.206146335473987
- 1:54.13482913537251
- 0:13.206091048253777
- 1:54.13479906037719
- 0:13.206013478309666
- 1:54.13478492908298
- 0:13.203459067800848
- 1:54.12987193609531
- 0:13.115724632438813
- 1:53.938133878533115
- 0:13.090805518310637
- 1:53.88326340972672
- 0:13.075057207848472
- 1:53.84849152167199
- 0:12.767765899706308
- 1:53.15753823489568
- 0:12.763758757174562
- 1:53.148291672778775
- 0:12.760565558095564
- 1:53.140678725519464
- 0:12.760594196683927
- 1:53.14064556820512
- system:index:20201219T101329_20201219T101331_T33UUV
- system:time_start:1608372954173
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201222T102339_20201222T102337_T32UQD
- system:time_start:1608632767722
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201222T102339_20201222T102337_T32UQE
- system:time_start:1608632753349
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201222T102339_20201222T102337_T33UUU
- system:time_start:1608632766874
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201222T102339_20201222T102337_T33UUV
- system:time_start:1608632752799
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.350445905956233
- 1:52.21521452364345
- 0:12.35045189068122
- 1:52.21517233370591
- 0:12.350796687962411
- 1:52.21505389958939
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.772949454149359
- 1:53.1899559993205
- 0:12.772862491649839
- 1:53.189944577401285
- 0:12.771897556823447
- 1:53.18942322690292
- 0:12.771859856607458
- 1:53.189394922643274
- 0:12.564225387010149
- 1:52.71629532294649
- 0:12.361273641038311
- 1:52.24274690249971
- 0:12.354831105045646
- 1:52.22727960906655
- 0:12.350508104014926
- 1:52.216600173256715
- 0:12.350406000409583
- 1:52.21524500448177
- 0:12.350445905956233
- 1:52.21521452364345
- system:index:20201224T101431_20201224T101431_T32UQD
- system:time_start:1608804972989
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.169391189263207
- 1:54.07535062565756
- 0:13.169352170441744
- 1:54.075322227794366
- 0:12.954091869075981
- 1:53.600920944983514
- 0:12.743867293444234
- 1:53.12604170861612
- 0:12.736014942285058
- 1:53.107939342633706
- 0:12.734883347417922
- 1:53.10526756453952
- 0:12.734664695858061
- 1:53.10274705412164
- 0:12.734772569932963
- 1:53.102653525755564
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.170470900668464
- 1:54.075879298328516
- 0:13.170381949958214
- 1:54.07586820972608
- 0:13.169391189263207
- 1:54.07535062565756
- system:index:20201224T101431_20201224T101431_T32UQE
- system:time_start:1608804958105
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35748949913392
- 1:52.23345630814721
- 0:12.35751299524745
- 1:52.23343908220483
- 0:12.35811941611142
- 1:52.23309292422743
- 0:12.358196576669535
- 1:52.23306819483536
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790252576440476
- 1:53.229231165558666
- 0:12.790167430407873
- 1:53.22921553214035
- 0:12.789260370158681
- 1:53.228636482718315
- 0:12.789241564018281
- 1:53.22860886478841
- 0:12.771525991829938
- 1:53.1888980697907
- 0:12.57096698736304
- 1:52.73152411864929
- 0:12.374424144466108
- 1:52.27383464407166
- 0:12.359001925707853
- 1:52.23733822190526
- 0:12.357470482432987
- 1:52.2335263966679
- 0:12.357498748643295
- 1:52.23349327254195
- 0:12.35748949913392
- 1:52.23345630814721
- system:index:20201224T101431_20201224T101431_T33UUU
- system:time_start:1608804972130
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.750771301811552
- 1:53.140131693984856
- 0:12.750803187038228
- 1:53.14011980210586
- 0:12.751126721912343
- 1:53.14003000043828
- 0:12.751174266962886
- 1:53.14002734009454
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19696787477602
- 1:54.13469198006072
- 0:13.1969188787976
- 1:54.134665349435764
- 0:13.196847312327534
- 1:54.13465858670992
- 0:13.195955853600612
- 1:54.1335412155917
- 0:13.174997213558543
- 1:54.087912292765274
- 0:12.96092915502967
- 1:53.61574188420615
- 0:12.751461594919125
- 1:53.14320351071441
- 0:12.750673382080345
- 1:53.14101810139914
- 0:12.750716198727762
- 1:53.14019860015889
- 0:12.75076074626071
- 1:53.140170144402134
- 0:12.750771301811552
- 1:53.140131693984856
- system:index:20201224T101431_20201224T101431_T33UUV
- system:time_start:1608804957513
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20201227T102431_20201227T102434_T32UQD
- system:time_start:1609064770820
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20201227T102431_20201227T102434_T32UQE
- system:time_start:1609064756464
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20201227T102431_20201227T102434_T33UUU
- system:time_start:1609064769979
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20201227T102431_20201227T102434_T33UUV
- system:time_start:1609064755914
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77821758577903
- 1:53.18978886405824
- 0:12.777136780539866
- 1:53.18813758536533
- 0:12.699167228332405
- 1:53.013030732868415
- 0:12.669266730814506
- 1:52.945419775312615
- 0:12.517749434006337
- 1:52.59706958576421
- 0:12.368740592429004
- 1:52.2484702683455
- 0:12.358013483957425
- 1:52.22287169906996
- 0:12.355849783442766
- 1:52.21752752596671
- 0:12.355659428259093
- 1:52.21500560488291
- 0:12.355766084233498
- 1:52.21491249668796
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20201229T101329_20201229T101330_T32UQD
- system:time_start:1609236971672
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.174129191270419
- 1:54.07575224960105
- 0:13.174040235881767
- 1:54.075741164206605
- 0:13.173015257596695
- 1:54.075205672585724
- 0:13.122632450407911
- 1:53.96520002276405
- 0:13.115619914501883
- 1:53.949789213419855
- 0:12.926543571703817
- 1:53.528971438230165
- 0:12.741381250662998
- 1:53.107770631095605
- 0:12.740249232125484
- 1:53.10509883690176
- 0:12.740030273479645
- 1:53.10257834072726
- 0:12.740138289371739
- 1:53.102484874308956
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.174129191270419
- 1:54.07575224960105
- system:index:20201229T101329_20201229T101330_T32UQE
- system:time_start:1609236956796
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.362764316374774
- 1:52.233609918359214
- 0:12.36275442975186
- 1:52.23357079900345
- 0:12.363385168478946
- 1:52.23321075129476
- 0:12.363462330544499
- 1:52.23318601790734
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.795641476845292
- 1:53.22933107145998
- 0:12.795586451994236
- 1:53.229300127965324
- 0:12.79550970111367
- 1:53.22928408530309
- 0:12.699187348542484
- 1:53.0132711996247
- 0:12.671277501928017
- 1:52.95014675686021
- 0:12.66889052585386
- 1:52.94470495602633
- 0:12.515777879767745
- 1:52.592260386583725
- 0:12.365018237363929
- 1:52.23963112837022
- 0:12.363485605171462
- 1:52.235817833763974
- 0:12.362735271135678
- 1:52.233641316039055
- 0:12.362764316374774
- 1:52.233609918359214
- system:index:20201229T101329_20201229T101330_T33UUU
- system:time_start:1609236970816
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.756112777701627
- 1:53.14056116056398
- 0:12.75610209305903
- 1:53.14052084400874
- 0:12.756743037970889
- 1:53.14015885527888
- 0:12.756821602807012
- 1:53.14013387758587
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.200639202843606
- 1:54.13474693293676
- 0:13.200583924312603
- 1:54.13471685489546
- 0:13.200506322235725
- 1:54.13470263915681
- 0:13.198800196994116
- 1:54.13142040721839
- 0:13.191244047175472
- 1:54.1151252693528
- 0:13.126053356994388
- 1:53.9728150438419
- 0:13.11274074830239
- 1:53.9434806862231
- 0:12.93358465831999
- 1:53.54406963668589
- 0:12.757680427636032
- 1:53.14440114908013
- 0:12.756084173733232
- 1:53.14059439606091
- 0:12.756112777701627
- 1:53.14056116056398
- system:index:20201229T101329_20201229T101330_T33UUV
- system:time_start:1609236956211
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210720T101559_20210720T101617_T32UQD
- system:time_start:1626776773282
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210720T101559_20210720T101617_T32UQE
- system:time_start:1626776758931
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210720T101559_20210720T101617_T33UUU
- system:time_start:1626776772443
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210720T101559_20210720T101617_T33UUV
- system:time_start:1626776758379
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.772827975615117
- 1:53.189959856102426
- 0:12.758273579491073
- 1:53.157428732147196
- 0:12.565265735904955
- 1:52.71815289571979
- 0:12.376297001608894
- 1:52.27847567475176
- 0:12.36772080080858
- 1:52.25821336889191
- 0:12.35163194723558
- 1:52.21981530878688
- 0:12.350548678562888
- 1:52.217138655939664
- 0:12.350399305994973
- 1:52.215155197526926
- 0:12.350505860298801
- 1:52.21506210599126
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20210722T101031_20210722T101419_T32UQD
- system:time_start:1626948977220
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.170407382985173
- 1:54.075881538601685
- 0:13.169357423280395
- 1:54.07533289405379
- 0:13.165846454193288
- 1:54.067872538605975
- 0:13.154121230064115
- 1:54.04237229041722
- 0:13.123696128658516
- 1:53.975957692614436
- 0:12.939124865465724
- 1:53.566875127362145
- 0:12.758273392153068
- 1:53.15742833512515
- 0:12.751538570505247
- 1:53.14199019693685
- 0:12.73695601977645
- 1:53.108449481306714
- 0:12.734680602046184
- 1:53.10307679191295
- 0:12.73534065656124
- 1:53.1026357543057
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20210722T101031_20210722T101419_T32UQE
- system:time_start:1626948962329
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.357498748643295
- 1:52.23349327254195
- 0:12.357488555246212
- 1:52.23345295119355
- 0:12.35811941611142
- 1:52.23309292422743
- 0:12.358196576669535
- 1:52.23306819483536
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790252576440476
- 1:53.229231165558666
- 0:12.790198731550948
- 1:53.22920092722376
- 0:12.790122892118433
- 1:53.229186536935416
- 0:12.788482902528463
- 1:53.22589873011103
- 0:12.579657100297641
- 1:52.751124556201546
- 0:12.375175262277207
- 1:52.276009693935656
- 0:12.370542463129278
- 1:52.265114971113285
- 0:12.364379404644176
- 1:52.2504085358439
- 0:12.359001819060508
- 1:52.2373379862698
- 0:12.357470482432987
- 1:52.2335263966679
- 0:12.357498748643295
- 1:52.23349327254195
- system:index:20210722T101031_20210722T101419_T33UUU
- system:time_start:1626948976361
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.751617113714017
- 1:53.14012570274559
- 0:12.751737747953547
- 1:53.14003799176532
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.196872856303191
- 1:54.13469053746887
- 0:13.195956995882309
- 1:54.13354252759554
- 0:13.195105555223249
- 1:54.13190440213837
- 0:13.192586303744188
- 1:54.12647175451726
- 0:13.120713404980156
- 1:53.96949544427469
- 0:13.086639372178047
- 1:53.894524027484955
- 0:12.92089666935665
- 1:53.525779175257995
- 0:12.757931002443186
- 1:53.15681401423597
- 0:12.753926190177781
- 1:53.14756711472271
- 0:12.752329608756813
- 1:53.14375886998265
- 0:12.751541432444375
- 1:53.14157394061097
- 0:12.751617113714017
- 1:53.14012570274559
- system:index:20210722T101031_20210722T101419_T33UUV
- system:time_start:1626948961738
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210725T102031_20210725T102548_T32UQD
- system:time_start:1627208774618
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.670585062123195
- 1:53.49468447883149
- 0:13.71779001635009
- 1:53.91787123848316
- 0:13.718094094643787
- 1:53.9259589208516
- 0:13.718050417272353
- 1:53.92598944565958
- 0:13.71804125781661
- 1:53.9260290660159
- 0:13.71800935008452
- 1:53.926041481931065
- 0:13.649792153225073
- 1:53.94598470405573
- 0:13.14694816153489
- 1:54.042150040717054
- 0:12.97350616719785
- 1:54.069602685528444
- 0:12.857599325913188
- 1:54.086334206092204
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058830880593415
- 1:54.10924624101911
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- system:index:20210725T102031_20210725T102548_T32UQE
- system:time_start:1627208760611
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210725T102031_20210725T102548_T33UUU
- system:time_start:1627208773776
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010870575835755
- 1:53.123733817593966
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.625866544722232
- 1:53.93568198442586
- 0:13.624914503435619
- 1:53.946099657612386
- 0:13.624865310341008
- 1:53.94612917509182
- 0:13.624847965997674
- 1:53.94616922434166
- 0:13.624813963268378
- 1:53.94617948738762
- 0:13.509657108153744
- 1:53.970694232446085
- 0:13.303095618042269
- 1:54.011102644468416
- 0:12.999142825994399
- 1:54.066836798057395
- 0:12.770538758424244
- 1:54.105968343358185
- 0:12.630054228168207
- 1:54.12270253738187
- 0:12.620813083189988
- 1:54.12359977057458
- 0:12.607894236824679
- 1:54.12442368730819
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940251452605162
- 1:54.10922292267334
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- system:index:20210725T102031_20210725T102548_T33UUV
- system:time_start:1627208760264
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.765688258052938
- 1:53.19018602651122
- 0:12.764642810640039
- 1:53.189079928980554
- 0:12.762421039616603
- 1:53.184281875683574
- 0:12.572473574540632
- 1:52.751934846999994
- 0:12.386444285010715
- 1:52.31919956065164
- 0:12.350016054151007
- 1:52.233353478470136
- 0:12.345737502125605
- 1:52.22322081008805
- 0:12.34357515728587
- 1:52.21787631750534
- 0:12.343385643399108
- 1:52.21535435145997
- 0:12.34349220841784
- 1:52.2152612666215
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20210727T100559_20210727T100556_T32UQD
- system:time_start:1627380975740
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.162239628994309
- 1:54.07616481278918
- 0:13.16217659384411
- 1:54.07613595137732
- 0:13.162100118013747
- 1:54.07612237102548
- 0:13.162084124317868
- 1:54.0761019015563
- 0:13.160953087975498
- 1:54.07398045002097
- 0:13.136338759516434
- 1:54.02031839018393
- 0:12.93084060911851
- 1:53.56552900661938
- 0:12.729940823963254
- 1:53.11028886849048
- 0:12.727682143063545
- 1:53.104953881842896
- 0:12.727510485305968
- 1:53.10297162837818
- 0:12.727567709790337
- 1:53.10292830673336
- 0:12.727618370889822
- 1:53.10287810685113
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- system:index:20210727T100559_20210727T100556_T32UQE
- system:time_start:1627380960851
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.350515905135145
- 1:52.23300796349085
- 0:12.350547225465617
- 1:52.23299608309973
- 0:12.350864826050767
- 1:52.23290734928472
- 0:12.35091140815388
- 1:52.23290479799191
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.782169318157482
- 1:53.22908096376881
- 0:12.782114201600372
- 1:53.22905002516284
- 0:12.78203743264964
- 1:53.22903389276472
- 0:12.579204443825182
- 1:52.76730076704378
- 0:12.38048604082438
- 1:52.30526458094878
- 0:12.351166211186412
- 1:52.23608199427479
- 0:12.350412475681637
- 1:52.23389404543513
- 0:12.350461330918693
- 1:52.23307474000143
- 0:12.350505214191577
- 1:52.23304638292878
- 0:12.350515905135145
- 1:52.23300796349085
- system:index:20210727T100559_20210727T100556_T33UUU
- system:time_start:1627380974880
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.743956582564907
- 1:53.139894306765065
- 0:12.744004237083393
- 1:53.139891637482144
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.189625021956498
- 1:54.13458175825475
- 0:13.189537930558492
- 1:54.134566305965386
- 0:13.188598249441077
- 1:54.13398548352077
- 0:13.186892830149953
- 1:54.130702547988
- 0:13.18352776119486
- 1:54.12363896488957
- 0:13.175979440188737
- 1:54.10734392558414
- 0:12.957327149361321
- 1:53.62458070053749
- 0:12.743479058446969
- 1:53.14143302547998
- 0:12.74347545140442
- 1:53.141410216787044
- 0:12.743546097874644
- 1:53.1400629573672
- 0:12.743590647472907
- 1:53.14003450467493
- 0:12.743602204682283
- 1:53.13999260886355
- 0:12.743956582564907
- 1:53.139894306765065
- system:index:20210727T100559_20210727T100556_T33UUV
- system:time_start:1627380960257
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210730T101559_20210730T102410_T32UQD
- system:time_start:1627640772940
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210730T101559_20210730T102410_T32UQE
- system:time_start:1627640758588
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210730T101559_20210730T102410_T33UUU
- system:time_start:1627640772101
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210730T101559_20210730T102410_T33UUV
- system:time_start:1627640758037
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.349569220879685
- 1:52.2152395008982
- 0:12.349575171142432
- 1:52.21519723244888
- 0:12.349919967976357
- 1:52.21507880121461
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77205341171535
- 1:53.189984455111734
- 0:12.771966450391053
- 1:53.18997303241654
- 0:12.771001501724651
- 1:53.189451593481834
- 0:12.770963802648655
- 1:53.1894232888626
- 0:12.562785841174417
- 1:52.71498949049733
- 0:12.359315656040577
- 1:52.240104572370214
- 0:12.355034362528102
- 1:52.229972305235044
- 0:12.34963134654502
- 1:52.2166250738422
- 0:12.349529279441619
- 1:52.2152699028951
- 0:12.349569220879685
- 1:52.2152395008982
- system:index:20210801T101031_20210801T101419_T32UQD
- system:time_start:1627812976995
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.169461520584756
- 1:54.0759143711319
- 0:13.168381974238223
- 1:54.07481225234485
- 0:13.164878064186546
- 1:54.067366381888704
- 0:12.951453395594495
- 1:53.59696061107041
- 0:12.859059171937869
- 1:53.38950566265113
- 0:12.742925748212931
- 1:53.1255316680337
- 0:12.735073940944371
- 1:53.107429277614365
- 0:12.733942297363823
- 1:53.10475743900705
- 0:12.73377339104298
- 1:53.102809400294376
- 0:12.734175019481304
- 1:53.10267232274587
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20210801T101031_20210801T101419_T32UQE
- system:time_start:1627812962110
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.788329751306811
- 1:53.22915191585306
- 0:12.788315694986704
- 1:53.229131050687265
- 0:12.570862046920736
- 1:52.733410287937495
- 0:12.35812426478182
- 1:52.23731862968367
- 0:12.356592903104316
- 1:52.23350671144665
- 0:12.356621060078233
- 1:52.23347359920031
- 0:12.35661184717904
- 1:52.23343671325592
- 0:12.356635417700879
- 1:52.23341939732925
- 0:12.357241840545095
- 1:52.23307324454122
- 0:12.35731900085175
- 1:52.233048515815
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.788456247501115
- 1:53.2291978959799
- 0:12.788401083119464
- 1:53.229166881394725
- 0:12.788329751306811
- 1:53.22915191585306
- system:index:20210801T101031_20210801T101419_T33UUU
- system:time_start:1627812976136
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.19604990286127
- 1:54.13467819748574
- 0:13.195917075397237
- 1:54.134633977913325
- 0:13.194211226988786
- 1:54.131351608333404
- 0:13.044328490350349
- 1:53.80322552141913
- 0:12.953048284188144
- 1:53.60050376285552
- 0:12.858566343366975
- 1:53.38847164457295
- 0:12.770628516002597
- 1:53.18888099034408
- 0:12.764207371936468
- 1:53.17419491359453
- 0:12.752189590629193
- 1:53.146455401085376
- 0:12.750593282290149
- 1:53.14264718270963
- 0:12.749791179013402
- 1:53.140423324161375
- 0:12.750514595526058
- 1:53.140014864968485
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19604990286127
- 1:54.13467819748574
- system:index:20210801T101031_20210801T101419_T33UUV
- system:time_start:1627812961519
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210804T102031_20210804T102026_T32UQD
- system:time_start:1628072774209
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210804T102031_20210804T102026_T32UQE
- system:time_start:1628072759848
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210804T102031_20210804T102026_T33UUU
- system:time_start:1628072773368
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210804T102031_20210804T102026_T33UUV
- system:time_start:1628072759297
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.7674802725699
- 1:53.19012929803857
- 0:12.766434857996037
- 1:53.18902320876214
- 0:12.764213009545484
- 1:53.18422543003603
- 0:12.758649454310074
- 1:53.171988294039174
- 0:12.558265585465012
- 1:52.714045993908655
- 0:12.362251646221608
- 1:52.25567110967213
- 0:12.356887353719607
- 1:52.242871691243835
- 0:12.348286908242713
- 1:52.222068884159896
- 0:12.346124435810259
- 1:52.21672467880098
- 0:12.346018343926668
- 1:52.21531398591329
- 0:12.346413207171087
- 1:52.21517841033532
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20210806T100559_20210806T101207_T32UQD
- system:time_start:1628244974971
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.164920391971815
- 1:54.07604084152188
- 0:13.164838369081727
- 1:54.07602627215396
- 0:13.163696787520076
- 1:54.07388536647363
- 0:13.052897149806322
- 1:53.831437742255865
- 0:12.943439950589637
- 1:53.58886019100786
- 0:12.728440590656339
- 1:53.103320573146156
- 0:12.728466454647423
- 1:53.10328965990171
- 0:12.728451317119173
- 1:53.10325268409541
- 0:12.729039206436834
- 1:53.102860050540116
- 0:12.729113924408946
- 1:53.102831178431714
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164983314447332
- 1:54.076069714156716
- 0:13.164920391971815
- 1:54.07604084152188
- system:index:20210806T100559_20210806T101207_T32UQE
- system:time_start:1628244960090
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.783839053072475
- 1:53.22906843824738
- 0:12.78382488679554
- 1:53.229047584777874
- 0:12.568432569222894
- 1:52.73713706534776
- 0:12.357676105172997
- 1:52.24486300509725
- 0:12.35383120559621
- 1:52.235602055727526
- 0:12.353081194244739
- 1:52.233425089696354
- 0:12.353110244775616
- 1:52.23339369470399
- 0:12.353101314026826
- 1:52.2333579312759
- 0:12.353124811020983
- 1:52.23334070633341
- 0:12.353731351551815
- 1:52.23299456266477
- 0:12.353808510852286
- 1:52.23296983660201
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.783910378826993
- 1:53.22908340696904
- 0:12.783839053072475
- 1:53.22906843824738
- system:index:20210806T100559_20210806T101207_T33UUU
- system:time_start:1628244974111
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.745338540563603
- 1:53.14009687588418
- 0:12.745394682282837
- 1:53.14002660583153
- 0:12.745761298331546
- 1:53.1399249663481
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.192314922830455
- 1:54.1346221455201
- 0:13.191351695032688
- 1:54.13402685999693
- 0:13.19049311646598
- 1:54.13237443637691
- 0:13.166185788703512
- 1:54.079688068638745
- 0:12.97599742353264
- 1:53.66103829831693
- 0:12.789445277112925
- 1:53.24209885598524
- 0:12.758097165672643
- 1:53.1708432631804
- 0:12.75008678187477
- 1:53.15234977510759
- 0:12.745299850472902
- 1:53.140927931980926
- 0:12.745296203735663
- 1:53.14090529461551
- 0:12.745338540563603
- 1:53.14009687588418
- system:index:20210806T100559_20210806T101207_T33UUV
- system:time_start:1628244959498
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210809T101559_20210809T102307_T32UQD
- system:time_start:1628504772061
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210809T101559_20210809T102307_T32UQE
- system:time_start:1628504757705
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210809T101559_20210809T102307_T33UUU
- system:time_start:1628504771222
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210809T101559_20210809T102307_T33UUV
- system:time_start:1628504757153
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77285662559716
- 1:53.18995891189564
- 0:12.77181066824118
- 1:53.18885249954112
- 0:12.596586752112795
- 1:52.79087121035703
- 0:12.424702076959285
- 1:52.392569795925155
- 0:12.395644060729062
- 1:52.324331846841055
- 0:12.369884413750897
- 1:52.26354810387
- 0:12.352671057592563
- 1:52.22194429424183
- 0:12.350508104014926
- 1:52.216600173256715
- 0:12.350401822149935
- 1:52.21518949167075
- 0:12.350796687962411
- 1:52.21505389958939
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20210811T101031_20210811T101411_T32UQD
- system:time_start:1628676976406
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.169496899431925
- 1:54.075883792577415
- 0:13.169417744315451
- 1:54.07587355983293
- 0:13.168324924401007
- 1:54.074267932557895
- 0:12.954142163417629
- 1:53.601458935736844
- 0:12.744949372422774
- 1:53.12816603869584
- 0:12.735920900971545
- 1:53.106861334932915
- 0:12.734743205372506
- 1:53.103651440407155
- 0:12.734672429346595
- 1:53.10283671260084
- 0:12.734712868269694
- 1:53.10280621794602
- 0:12.734718617624784
- 1:53.10276389011676
- 0:12.735069273731886
- 1:53.10264426746488
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16955630884026
- 1:54.075911023473104
- 0:13.169496899431925
- 1:54.075883792577415
- system:index:20210811T101031_20210811T101411_T32UQE
- system:time_start:1628676961520
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790159595111053
- 1:53.22922950462824
- 0:12.78927303816266
- 1:53.22807773892989
- 0:12.781994437462028
- 1:53.212290696725915
- 0:12.602511958066728
- 1:52.80446117362973
- 0:12.426248631759998
- 1:52.396378343503166
- 0:12.39680244783737
- 1:52.32720828737661
- 0:12.368226809766375
- 1:52.2596673778359
- 0:12.364379262344048
- 1:52.25040822161236
- 0:12.358251292339757
- 1:52.23516052808763
- 0:12.35824792641028
- 1:52.23513783737251
- 0:12.358365374543164
- 1:52.23316206754682
- 0:12.358484221386755
- 1:52.23307463973299
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20210811T101031_20210811T101411_T33UUU
- system:time_start:1628676975547
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.195920231680592
- 1:54.13463261063349
- 0:13.195905629597172
- 1:54.13461180177147
- 0:13.193386695476011
- 1:54.12918052626212
- 0:13.17243639039798
- 1:54.083558573895054
- 0:12.959673417750219
- 1:53.61356280039855
- 0:12.751461594919125
- 1:53.14320351071441
- 0:12.750673382080345
- 1:53.14101810139914
- 0:12.750716198727762
- 1:53.14019860015889
- 0:12.75076074626071
- 1:53.140170144402134
- 0:12.750772219724773
- 1:53.14012833958154
- 0:12.751126721912343
- 1:53.14003000043828
- 0:12.751174266962886
- 1:53.14002734009454
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19604990286127
- 1:54.13467819748574
- 0:13.195993298034564
- 1:54.13464741878207
- 0:13.195920231680592
- 1:54.13463261063349
- system:index:20210811T101031_20210811T101411_T33UUV
- system:time_start:1628676960928
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.95947494745978
- 1:52.70183419208591
- 0:11.959504938997455
- 1:52.7018209474377
- 0:11.961253104942818
- 1:52.70123415003687
- 0:11.967105457733087
- 1:52.70000604010934
- 0:11.996911111546112
- 1:52.694219091488456
- 0:13.548172515193444
- 1:52.39472880980929
- 0:13.552956765154201
- 1:52.39400386698187
- 0:13.553005920806696
- 1:52.39401940834825
- 0:13.55305957499193
- 1:52.394011086624296
- 0:13.553089962886562
- 1:52.394023766625146
- 0:13.553245749983105
- 1:52.394107656953494
- 0:13.553293500341287
- 1:52.39415208043515
- 0:13.593208514972124
- 1:52.776821870625255
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.99449220197749
- 1:53.21201700633866
- 0:11.959428494378097
- 1:52.70190334078307
- 0:11.959468959101587
- 1:52.70187304954444
- 0:11.95947494745978
- 1:52.70183419208591
- system:index:20210814T102031_20210814T102250_T32UQD
- system:time_start:1628936770886
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210814T102031_20210814T102250_T32UQE
- system:time_start:1628936759376
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.04062043635402
- 1:52.68804209046128
- 0:12.040637776965712
- 1:52.68801547216338
- 0:12.040969306725088
- 1:52.68765099055018
- 0:12.041306998080977
- 1:52.68746195541274
- 0:12.04374686645375
- 1:52.68661787654218
- 0:12.062539659040388
- 1:52.680245509177986
- 0:12.852933248676349
- 1:52.52941850607469
- 0:13.637957577397778
- 1:52.37328620808986
- 0:13.672074159022806
- 1:52.368006128067634
- 0:13.674736986715583
- 1:52.36803598911102
- 0:13.674820748734628
- 1:52.368051044684655
- 0:13.674984638853628
- 1:52.36815515581643
- 0:13.675026305646474
- 1:52.368201812337965
- 0:13.661782301286745
- 1:52.80510788620289
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004609348085067
- 1:53.211994482054486
- 0:12.04062043635402
- 1:52.68804209046128
- system:index:20210814T102031_20210814T102250_T33UUU
- system:time_start:1628936770466
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210814T102031_20210814T102250_T33UUV
- system:time_start:1628936758825
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.765663843042015
- 1:53.19018684272034
- 0:12.76454385219265
- 1:53.18799358243105
- 0:12.594322889179502
- 1:52.80119356892312
- 0:12.42725272506757
- 1:52.414082460302964
- 0:12.369191767615815
- 1:52.277599514895314
- 0:12.364904312562947
- 1:52.26746811147585
- 0:12.34561591460265
- 1:52.22160523016054
- 0:12.343453746263242
- 1:52.21626077022627
- 0:12.343388152170101
- 1:52.21538864603858
- 0:12.343783088080741
- 1:52.21525299021247
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20210816T100559_20210816T101300_T32UQD
- system:time_start:1629108973683
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.165787523865488
- 1:54.07604183401416
- 0:13.164666868927783
- 1:54.074394955217876
- 0:13.147134287238744
- 1:54.036677215337384
- 0:13.137791279211
- 1:54.016490533048156
- 0:13.11212082843916
- 1:53.96070368223078
- 0:12.919539665207745
- 1:53.536487578041815
- 0:12.730975265755806
- 1:53.11187553195349
- 0:12.727588900401054
- 1:53.1038775171143
- 0:12.727513502536798
- 1:53.10300583151978
- 0:12.727915015612506
- 1:53.102868789975695
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20210816T100559_20210816T101300_T32UQE
- system:time_start:1629108958788
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783067440516646
- 1:53.22909773761695
- 0:12.78301360702536
- 1:53.22906749538586
- 0:12.782943261642453
- 1:53.22905409075062
- 0:12.782928035661886
- 1:53.22903351963882
- 0:12.782112904721247
- 1:53.227398745349724
- 0:12.766815427241403
- 1:53.19312555531386
- 0:12.596627862849175
- 1:52.80623036901916
- 0:12.429336984580148
- 1:52.41910701988548
- 0:12.36586351957051
- 1:52.26986671191523
- 0:12.352011705106083
- 1:52.236640413498236
- 0:12.351258078262987
- 1:52.234452599818916
- 0:12.351344299647732
- 1:52.23300459292479
- 0:12.351406456887718
- 1:52.2329645033189
- 0:12.351463298967857
- 1:52.23291724010892
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- system:index:20210816T100559_20210816T101300_T33UUU
- system:time_start:1629108972821
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.193232734661416
- 1:54.13463597456668
- 0:13.1922695967915
- 1:54.13404068487966
- 0:13.191411160830484
- 1:54.13238867089303
- 0:13.183834411023746
- 1:54.116632472011446
- 0:13.180471448618345
- 1:54.10956968501936
- 0:12.982535789477273
- 1:53.676252124363955
- 0:12.788519126765179
- 1:53.2426211376298
- 0:12.757172167193813
- 1:53.171365295763174
- 0:12.745159085700507
- 1:53.14362363210352
- 0:12.744371150142525
- 1:53.141438256090495
- 0:12.744447059872936
- 1:53.13999011108546
- 0:12.744567664581254
- 1:53.13990232898189
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20210816T100559_20210816T101300_T33UUV
- system:time_start:1629108958197
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210819T101559_20210819T101556_T32UQD
- system:time_start:1629368770609
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210819T101559_20210819T101556_T32UQE
- system:time_start:1629368756245
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210819T101559_20210819T101556_T33UUU
- system:time_start:1629368769767
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210819T101559_20210819T101556_T33UUV
- system:time_start:1629368755693
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.772887202890749
- 1:53.18995800863772
- 0:12.771864546837254
- 1:53.18940535307576
- 0:12.743914295396966
- 1:53.126580280321654
- 0:12.597719319136328
- 1:52.79380496347871
- 0:12.426712868389007
- 1:52.39574935941923
- 0:12.363272632013846
- 1:52.24592775778265
- 0:12.353588573144988
- 1:52.222457806423776
- 0:12.35142545890154
- 1:52.217113746899436
- 0:12.351275923202813
- 1:52.21513030329841
- 0:12.351382585872479
- 1:52.21503719929329
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20210821T101031_20210821T101418_T32UQD
- system:time_start:1629540976052
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.733818398551668
- 1:53.103087603520144
- 0:12.733839762058759
- 1:53.10306910440257
- 0:12.73440480411973
- 1:53.10269159611227
- 0:12.734479559262756
- 1:53.102662799592956
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16955630884026
- 1:54.075911023473104
- 0:13.16949146282058
- 1:54.075881267186695
- 0:13.169408132146758
- 1:54.07586430859634
- 0:12.954142201847397
- 1:53.60145901553359
- 0:12.743914108400457
- 1:53.126579883436875
- 0:12.736061703495116
- 1:53.10847754663404
- 0:12.733806003734742
- 1:53.10315142105523
- 0:12.733832051033374
- 1:53.103120903410385
- 0:12.733818398551668
- 1:53.103087603520144
- system:index:20210821T101031_20210821T101418_T32UQE
- system:time_start:1629540961173
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.358376098754166
- 1:52.23351165827636
- 0:12.358366253347464
- 1:52.23347261697416
- 0:12.35899711215372
- 1:52.23311258460888
- 0:12.359074272963237
- 1:52.233087854550874
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790252576440476
- 1:53.229231165558666
- 0:12.790167430407873
- 1:53.22921553214035
- 0:12.789251606272998
- 1:53.22863083515829
- 0:12.777137832119175
- 1:53.201950242484735
- 0:12.595386073048475
- 1:52.78840124857301
- 0:12.56779105889681
- 1:52.72471488900456
- 0:12.425555962823818
- 1:52.39312576312943
- 0:12.362161149695618
- 1:52.24334425743885
- 0:12.359097203251176
- 1:52.23571967521295
- 0:12.358347086653579
- 1:52.23354313327575
- 0:12.358376098754166
- 1:52.23351165827636
- system:index:20210821T101031_20210821T101418_T33UUU
- system:time_start:1629540975194
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19696787477602
- 1:54.13469198006072
- 0:13.196934609465563
- 1:54.134673926406
- 0:13.196889967473137
- 1:54.13467813471911
- 0:13.196860324022667
- 1:54.134663910741764
- 0:13.195948492095898
- 1:54.134100436052925
- 0:13.195929076310557
- 1:54.1340728826848
- 0:13.193410090840326
- 1:54.128641484776985
- 0:12.983050772515057
- 1:53.665472565072434
- 0:12.77713760675288
- 1:53.20194976581656
- 0:12.750649371793546
- 1:53.14156876073176
- 0:12.750645759522303
- 1:53.14154595235957
- 0:12.750720871580338
- 1:53.14010879674193
- 0:12.75078398670272
- 1:53.14006847682912
- 0:12.750841469374514
- 1:53.14002100740641
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20210821T101031_20210821T101418_T33UUV
- system:time_start:1629540960582
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210824T102031_20210824T102025_T32UQD
- system:time_start:1629800773248
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210824T102031_20210824T102025_T32UQE
- system:time_start:1629800758896
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210824T102031_20210824T102025_T33UUU
- system:time_start:1629800772407
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210824T102031_20210824T102025_T33UUV
- system:time_start:1629800758346
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77205341171535
- 1:53.189984455111734
- 0:12.772002205964496
- 1:53.18996012467941
- 0:12.771937251174231
- 1:53.1899569154461
- 0:12.771914785187224
- 1:53.18993889709054
- 0:12.770914817890517
- 1:53.18888101132375
- 0:12.757519371884987
- 1:53.15907160154548
- 0:12.556173894076544
- 1:52.69926794915328
- 0:12.359234050686926
- 1:52.23902711339935
- 0:12.350589253615272
- 1:52.21767714288178
- 0:12.350399305994973
- 1:52.215155197526926
- 0:12.35045580723186
- 1:52.215112095168315
- 0:12.350505860298801
- 1:52.21506210599126
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- system:index:20210826T100549_20210826T100809_T32UQD
- system:time_start:1629972971925
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.16947684389189
- 1:54.07590116355663
- 0:13.16944517527756
- 1:54.07588844313454
- 0:13.168476622600002
- 1:54.075382340660624
- 0:13.168437604946524
- 1:54.07535394242134
- 0:12.960051031703294
- 1:53.616104874680175
- 0:12.756388528662521
- 1:53.156408464236755
- 0:12.733942409418525
- 1:53.1047576770793
- 0:12.73377044288631
- 1:53.10277510595105
- 0:12.73387835574944
- 1:53.102681657795024
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16955630884026
- 1:54.075911023473104
- 0:13.16947684389189
- 1:54.07590116355663
- system:index:20210826T100549_20210826T100809_T32UQE
- system:time_start:1629972957046
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.788456247501115
- 1:53.2291978959799
- 0:12.788401083119464
- 1:53.229166881394725
- 0:12.788329751306811
- 1:53.22915191585306
- 0:12.788315694986704
- 1:53.229131050687265
- 0:12.785899410339006
- 1:53.223691533424734
- 0:12.570094205292254
- 1:52.731236447161244
- 0:12.358937914453097
- 1:52.23841603634971
- 0:12.357405556712958
- 1:52.23460193931534
- 0:12.357402336728974
- 1:52.234579315644936
- 0:12.357487684547298
- 1:52.23314240166912
- 0:12.357549839525365
- 1:52.23310230834912
- 0:12.357606532289704
- 1:52.23305497486679
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20210826T100549_20210826T100809_T33UUU
- system:time_start:1629972971067
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.19604990286127
- 1:54.13467819748574
- 0:13.195917075397237
- 1:54.134633977913325
- 0:13.193363815215957
- 1:54.12972086848746
- 0:13.190844953910672
- 1:54.12428816301616
- 0:13.06749197380637
- 1:53.854303147784805
- 0:13.035245306241695
- 1:53.78311959197394
- 0:12.787500847049506
- 1:53.22749734401159
- 0:12.759387256895067
- 1:53.16331495165592
- 0:12.755381547873895
- 1:53.15406819341011
- 0:12.750593282290149
- 1:53.14264718270963
- 0:12.749791179013402
- 1:53.140423324161375
- 0:12.750514595526058
- 1:53.140014864968485
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19604990286127
- 1:54.13467819748574
- system:index:20210826T100549_20210826T100809_T33UUV
- system:time_start:1629972956458
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210829T101559_20210829T102531_T32UQD
- system:time_start:1630232768671
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210829T101559_20210829T102531_T32UQE
- system:time_start:1630232754304
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210829T101559_20210829T102531_T33UUU
- system:time_start:1630232767828
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210829T101559_20210829T102531_T33UUV
- system:time_start:1630232753753
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.34780069150096
- 1:52.21560727381952
- 0:12.347811833223517
- 1:52.21553935733922
- 0:12.348432715878253
- 1:52.21512102098351
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.771095089786643
- 1:53.19001483184527
- 0:12.770074709758475
- 1:53.189463334951796
- 0:12.768976802284765
- 1:53.187314063605946
- 0:12.76675903713032
- 1:53.18252558233881
- 0:12.649418601960054
- 1:52.916619510059256
- 0:12.533581911771487
- 1:52.650564759054305
- 0:12.41758332972574
- 1:52.38036364534727
- 0:12.357439160689664
- 1:52.23853887375957
- 0:12.34780069150096
- 1:52.21560727381952
- system:index:20210831T101031_20210831T101200_T32UQD
- system:time_start:1630404975155
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.732029823654152
- 1:53.103143776785146
- 0:12.73205118772988
- 1:53.10312527800619
- 0:12.73261623881379
- 1:53.10274777889371
- 0:12.732690994012112
- 1:53.10271898363051
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.166812503769583
- 1:54.0760062435302
- 0:13.166747858010984
- 1:54.075976632826254
- 0:13.166664727065614
- 1:54.075959819365465
- 0:13.149122682216106
- 1:54.038227512288046
- 0:12.941030740397435
- 1:53.57760606436811
- 0:12.737657106804955
- 1:53.11652266025414
- 0:12.732017425649582
- 1:53.103207594228884
- 0:12.732043474070188
- 1:53.10317707698114
- 0:12.732029823654152
- 1:53.103143776785146
- system:index:20210831T101031_20210831T101200_T32UQE
- system:time_start:1630404960264
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.787504334307213
- 1:53.22915091764642
- 0:12.787428498615848
- 1:53.22913652533112
- 0:12.786603356197336
- 1:53.22748221048957
- 0:12.591209530342406
- 1:52.78346092076439
- 0:12.499261863773174
- 1:52.57114045667261
- 0:12.414389962890048
- 1:52.37291821065596
- 0:12.384976714261825
- 1:52.303745430000205
- 0:12.356432275950981
- 1:52.23620014511878
- 0:12.355678365241973
- 1:52.234012216224855
- 0:12.355727060200536
- 1:52.23319283110955
- 0:12.35577097763295
- 1:52.23316455033117
- 0:12.35578265677635
- 1:52.23312273261885
- 0:12.356142437634166
- 1:52.233022184104584
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.787558174922678
- 1:53.22918115744251
- 0:12.787504334307213
- 1:53.22915091764642
- system:index:20210831T101031_20210831T101200_T33UUU
- system:time_start:1630404974296
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.748968176464528
- 1:53.14013632168159
- 0:12.748979727710358
- 1:53.14009442534873
- 0:12.749346349496808
- 1:53.139992773064314
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.194214264617418
- 1:54.134650661851175
- 0:13.194127166247771
- 1:54.1346352134902
- 0:13.193187469483027
- 1:54.134054421299396
- 0:13.192328938460692
- 1:54.13240233546893
- 0:13.183081789139594
- 1:54.1128452055158
- 0:13.175535541194483
- 1:54.09655011064221
- 0:12.96353075185315
- 1:53.62765321217023
- 0:12.756053170122062
- 1:53.15839645863407
- 0:12.748884950994826
- 1:53.14099567415492
- 0:12.748881339086193
- 1:53.14097311634152
- 0:12.748923628414975
- 1:53.14016477667224
- 0:12.748968176464528
- 1:53.14013632168159
- system:index:20210831T101031_20210831T101200_T33UUV
- system:time_start:1630404959670
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210903T102021_20210903T102024_T32UQD
- system:time_start:1630664772154
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210903T102021_20210903T102024_T32UQE
- system:time_start:1630664757803
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210903T102021_20210903T102024_T33UUU
- system:time_start:1630664771314
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210903T102021_20210903T102024_T33UUV
- system:time_start:1630664757252
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.353415418245932
- 1:52.214982999848424
- 0:12.353461495278061
- 1:52.21497811330349
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.773845542288115
- 1:53.18992761511224
- 0:12.77378297549832
- 1:53.18989792320381
- 0:12.773701961644512
- 1:53.18988142861605
- 0:12.77147492583675
- 1:53.18507451272145
- 0:12.57193106149148
- 1:52.72901517400642
- 0:12.376724223041638
- 1:52.27252701305144
- 0:12.353138349242876
- 1:52.216525763315694
- 0:12.353036177978616
- 1:52.21517018517357
- 0:12.353076008170598
- 1:52.21513979353879
- 0:12.353081954255183
- 1:52.215097525043284
- 0:12.353415418245932
- 1:52.214982999848424
- system:index:20210905T100549_20210905T100551_T32UQD
- system:time_start:1630836970236
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.17229995181673
- 1:54.07581575655729
- 0:13.172161380140544
- 1:54.07577829672754
- 0:13.171068904791081
- 1:54.07417323893675
- 0:13.168751748142258
- 1:54.069391236767366
- 0:13.164069524724061
- 1:54.05929857617818
- 0:12.973689568870046
- 1:53.64047812348658
- 0:12.787247164160439
- 1:53.22127105372632
- 0:12.737850457345118
- 1:53.10842139587737
- 0:12.735574834883638
- 1:53.10304865243609
- 0:12.736234884125833
- 1:53.10260760946902
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.17229995181673
- 1:54.07581575655729
- system:index:20210905T100549_20210905T100551_T32UQE
- system:time_start:1630836955369
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.361396305859065
- 1:52.23314341772878
- 0:12.361442893655408
- 1:52.23314086156901
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.791150680901357
- 1:53.22924788026149
- 0:12.791096948158653
- 1:53.229217630049774
- 0:12.791021107478974
- 1:53.22920324043717
- 0:12.788566277063346
- 1:53.2242818113354
- 0:12.581448338967506
- 1:52.75089121428906
- 0:12.378625498835541
- 1:52.27716533271892
- 0:12.362448810124766
- 1:52.23849440815406
- 0:12.360916199963615
- 1:52.23468059297776
- 0:12.360912977471141
- 1:52.23465796944583
- 0:12.360992881084535
- 1:52.23331075991158
- 0:12.361036687378123
- 1:52.233282488531124
- 0:12.361048360795088
- 1:52.23324067028006
- 0:12.361396305859065
- 1:52.23314341772878
- system:index:20210905T100549_20210905T100551_T33UUU
- system:time_start:1630836969379
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.198748183507801
- 1:54.134689400394564
- 0:13.198670583939876
- 1:54.13467518325532
- 0:13.197812182421202
- 1:54.13302359166283
- 0:13.003373123040529
- 1:53.70626836355994
- 0:12.812731389223151
- 1:53.279211364213516
- 0:12.788565562405426
- 1:53.224280301518995
- 0:12.758043293238114
- 1:53.154658214421964
- 0:12.754038646664757
- 1:53.145411342563854
- 0:12.752441906048292
- 1:53.141602485636746
- 0:12.752438367343666
- 1:53.14157983612419
- 0:12.752513403914296
- 1:53.14014268021809
- 0:12.752633999732321
- 1:53.140054888816344
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19880357630092
- 1:54.13471946640517
- 0:13.198748183507801
- 1:54.134689400394564
- system:index:20210905T100549_20210905T100551_T33UUV
- system:time_start:1630836954783
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210908T101559_20210908T102114_T32UQD
- system:time_start:1631096767619
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210908T101559_20210908T102114_T32UQE
- system:time_start:1631096753254
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210908T101559_20210908T102114_T33UUU
- system:time_start:1631096766774
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210908T101559_20210908T102114_T33UUV
- system:time_start:1631096752702
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.7845979906323
- 1:53.189586026725024
- 0:12.78454004943315
- 1:53.18955859249947
- 0:12.784468148451797
- 1:53.18954879671805
- 0:12.784450213243652
- 1:53.18952903435611
- 0:12.783408724354096
- 1:53.18793832173226
- 0:12.77109224330907
- 1:53.160260974555925
- 0:12.56968635877951
- 1:52.701559779585615
- 0:12.372677717766758
- 1:52.24242139888099
- 0:12.361946229569938
- 1:52.21681454297782
- 0:12.361796349513142
- 1:52.21483077693869
- 0:12.361852843641332
- 1:52.21478766873311
- 0:12.36190299611126
- 1:52.2147376628786
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- system:index:20210910T101031_20210910T101503_T32UQD
- system:time_start:1631268974011
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.181445647681691
- 1:54.0754977354044
- 0:13.181356682939724
- 1:54.07548665642663
- 0:13.180331739975145
- 1:54.07495121609726
- 0:13.151007982864341
- 1:54.01117660679753
- 0:13.087973923119916
- 1:53.873017363916446
- 0:12.928706866903477
- 1:53.51810650627765
- 0:12.772223736916184
- 1:53.162923067270825
- 0:12.747501202456634
- 1:53.10595878188018
- 0:12.746368996196628
- 1:53.10328709647902
- 0:12.746318202314473
- 1:53.10270289955802
- 0:12.746966062135508
- 1:53.10226986553742
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.181445647681691
- 1:54.0754977354044
- system:index:20210910T101031_20210910T101503_T32UQE
- system:time_start:1631268959135
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.801928575554346
- 1:53.22944718883743
- 0:12.801881024682384
- 1:53.229420447374466
- 0:12.801816580468502
- 1:53.22941401486056
- 0:12.801796679858851
- 1:53.22939495721237
- 0:12.800948376800429
- 1:53.22829339118083
- 0:12.798527191183027
- 1:53.2228467016237
- 0:12.584119435714829
- 1:52.734760274581824
- 0:12.374291936895364
- 1:52.24631316190158
- 0:12.370443429268175
- 1:52.23705263339905
- 0:12.369688895681728
- 1:52.23486500305959
- 0:12.369774564964377
- 1:52.23341696590219
- 0:12.369836715411891
- 1:52.23337686515452
- 0:12.369893435692005
- 1:52.233329603477216
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20210910T101031_20210910T101503_T33UUU
- system:time_start:1631268973155
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.76391326328323
- 1:53.14029376799761
- 0:12.763991829887
- 1:53.140268784827036
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.207982130669402
- 1:54.1348564704584
- 0:13.207849150938168
- 1:54.13481227964066
- 0:13.20614241671476
- 1:54.131529981695635
- 0:13.182661552195372
- 1:54.080477402018886
- 0:13.117551608579257
- 1:53.93816254491126
- 0:13.090138986300639
- 1:53.87785901162751
- 0:12.92854024313727
- 1:53.51755077961762
- 0:12.76958693197367
- 1:53.1570325878455
- 0:12.763193318234528
- 1:53.141794997982466
- 0:12.763251961371104
- 1:53.14066736348545
- 0:12.76391326328323
- 1:53.14029376799761
- system:index:20210910T101031_20210910T101503_T33UUV
- system:time_start:1631268958556
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210913T102021_20210913T102346_T32UQD
- system:time_start:1631528772188
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210913T102021_20210913T102346_T32UQE
- system:time_start:1631528757819
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210913T102021_20210913T102346_T33UUU
- system:time_start:1631528771343
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210913T102021_20210913T102346_T33UUV
- system:time_start:1631528757268
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.766559940645989
- 1:53.190158430577235
- 0:12.765439841043708
- 1:53.1879653535105
- 0:12.746449691792552
- 1:53.145389120949076
- 0:12.64976634813994
- 1:52.92605313462084
- 0:12.624374608776732
- 1:52.86800736318719
- 0:12.594655829082285
- 1:52.79983425730405
- 0:12.47559220866967
- 1:52.52357192204414
- 0:12.358090142729546
- 1:52.24715477181372
- 0:12.34515110087098
- 1:52.21563465635341
- 0:12.345802574470953
- 1:52.215195731838925
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20210915T100629_20210915T100654_T32UQD
- system:time_start:1631700969860
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.164005849402413
- 1:54.07607251750741
- 0:13.163923710797512
- 1:54.07605796038737
- 0:13.162782239344185
- 1:54.0739171225501
- 0:12.947634533160493
- 1:53.59978528955112
- 0:12.73751044855155
- 1:53.12516206900811
- 0:12.728483196968584
- 1:53.10384942686057
- 0:12.728435808780917
- 1:53.10330232513321
- 0:12.728454679556323
- 1:53.10325048447288
- 0:12.729039206436834
- 1:53.102860050540116
- 0:12.729113924408946
- 1:53.102831178431714
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164068809945578
- 1:54.076101470931754
- 0:13.164005849402413
- 1:54.07607251750741
- system:index:20210915T100629_20210915T100654_T32UQE
- system:time_start:1631700954977
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35309954045645
- 1:52.23304402426776
- 0:12.353218502457787
- 1:52.23295659088384
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783857237140989
- 1:53.22911241924307
- 0:12.781382056659043
- 1:53.22414861692262
- 0:12.778152206175191
- 1:53.21707416649276
- 0:12.67884042354263
- 1:52.992374959356
- 0:12.59553185464661
- 1:52.801892047519075
- 0:12.53177503945056
- 1:52.654371356492604
- 0:12.387699497291782
- 1:52.317294937569265
- 0:12.359143634931936
- 1:52.24975208135772
- 0:12.355298752113635
- 1:52.2404925806441
- 0:12.35376697331556
- 1:52.23667943837516
- 0:12.353013392561532
- 1:52.23449203183343
- 0:12.35309954045645
- 1:52.23304402426776
- system:index:20210915T100629_20210915T100654_T33UUU
- system:time_start:1631700969001
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.190443378049098
- 1:54.13401890331059
- 0:13.190423313315229
- 1:54.13399277620081
- 0:13.189575437472985
- 1:54.13236066208985
- 0:13.167781538817623
- 1:54.085105845027584
- 0:12.953795023289489
- 1:53.613192738426726
- 0:12.744403582733785
- 1:53.14091106217708
- 0:12.744400012453308
- 1:53.140888333088675
- 0:12.744442370510129
- 1:53.140079914439795
- 0:12.744486919850301
- 1:53.14005146136446
- 0:12.744498513478701
- 1:53.14000964485744
- 0:12.744852892747826
- 1:53.13991133966537
- 0:12.744900510322108
- 1:53.13990859057162
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.191460789016157
- 1:54.13460934995664
- 0:13.191373577677917
- 1:54.13459391227608
- 0:13.190443378049098
- 1:54.13401890331059
- system:index:20210915T100629_20210915T100654_T33UUV
- system:time_start:1631700954384
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210918T101639_20210918T102550_T32UQD
- system:time_start:1631960767680
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650654639748673
- 1:53.344033321051505
- 0:13.627703171654789
- 1:53.34870708595429
- 0:13.422686278773858
- 1:53.38996378000875
- 0:13.33859417319995
- 1:53.406549484644856
- 0:13.2774654253308
- 1:53.41847458472978
- 0:13.217624730377038
- 1:53.43005230525413
- 0:13.155536427455958
- 1:53.44194570356025
- 0:13.095911183691765
- 1:53.45328202727542
- 0:12.716532549862883
- 1:53.52308029390458
- 0:12.683536404679485
- 1:53.52895956342635
- 0:12.628220978647377
- 1:53.53874761533927
- 0:12.561265083754279
- 1:53.550476021803085
- 0:12.520177851623288
- 1:53.55762965465081
- 0:12.452255356758197
- 1:53.569324546814144
- 0:12.037600179567645
- 1:53.63939262064835
- 0:12.02484888021836
- 1:53.64141888854698
- 0:11.988348656710595
- 1:53.12375341677546
- 0:13.6245536495862
- 1:53.07135170244597
- 0:13.653981047106988
- 1:53.34322221451009
- 0:13.650654639748673
- 1:53.344033321051505
- system:index:20210918T101639_20210918T102550_T32UQE
- system:time_start:1631960758239
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210918T101639_20210918T102550_T33UUU
- system:time_start:1631960766832
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.643976149939755
- 1:53.345007326646375
- 0:13.642430764238252
- 1:53.34553863554918
- 0:13.637878554350197
- 1:53.34656851161397
- 0:13.630615997571883
- 1:53.34810409416401
- 0:13.41747056013726
- 1:53.390996833863035
- 0:13.354456262166195
- 1:53.40340959569054
- 0:13.310792436590647
- 1:53.41196956620448
- 0:13.246177977703988
- 1:53.42452296575635
- 0:13.15238144730431
- 1:53.44252714303642
- 0:13.11046853577474
- 1:53.45050196187991
- 0:13.086772533111935
- 1:53.45497957328103
- 0:12.736295831346897
- 1:53.5195180326862
- 0:12.577187021573073
- 1:53.54768681516847
- 0:12.496650810963262
- 1:53.56167183536592
- 0:12.438942193805316
- 1:53.571597325915185
- 0:12.021614237919966
- 1:53.641958712721554
- 0:11.977509930434747
- 1:53.6489497145197
- 0:11.973709255943463
- 1:53.64885361359809
- 0:12.010754727660915
- 1:53.1237309083812
- 0:13.650969032689474
- 1:53.15362317213181
- 0:13.644952497533627
- 1:53.344444847629696
- 0:13.643976149939755
- 1:53.345007326646375
- system:index:20210918T101639_20210918T102550_T33UUV
- system:time_start:1631960757968
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.77648249315502
- 1:53.189818020226106
- 0:12.77641179087453
- 1:53.189814519992794
- 0:12.77539486768994
- 1:53.18873888061412
- 0:12.764211651572518
- 1:53.16371705035474
- 0:12.55720128212751
- 1:52.69006264428568
- 0:12.354851183186907
- 1:52.21593743134875
- 0:12.354809853443799
- 1:52.21538957077098
- 0:12.35482884734784
- 1:52.21533777134386
- 0:12.355405269312582
- 1:52.21494928738571
- 0:12.35547878390611
- 1:52.21492067070585
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.776533667193602
- 1:53.189842268854285
- 0:12.77648249315502
- 1:53.189818020226106
- system:index:20210920T101031_20210920T101056_T32UQD
- system:time_start:1632132976405
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.175043666517018
- 1:54.07572041678763
- 0:13.17489869241922
- 1:54.07567698944954
- 0:13.173756607361677
- 1:54.07353627392776
- 0:12.982201328826832
- 1:53.65368725576421
- 0:12.794619585999406
- 1:53.23344883761152
- 0:12.758603936862157
- 1:53.15094163343575
- 0:12.74062719228675
- 1:53.10941336903165
- 0:12.73836715670039
- 1:53.10407874019138
- 0:12.738244743519212
- 1:53.102668812248275
- 0:12.738646297862578
- 1:53.10253180936872
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.175043666517018
- 1:54.07572041678763
- system:index:20210920T101031_20210920T101056_T32UQE
- system:time_start:1632132961540
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.362802701125165
- 1:52.23328326314858
- 0:12.362833947990746
- 1:52.23327146916907
- 0:12.363151532267866
- 1:52.23318261839021
- 0:12.363198266347199
- 1:52.23318012830826
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792946960017524
- 1:53.22928111453111
- 0:12.792893224427674
- 1:53.229250865291675
- 0:12.792817381254375
- 1:53.22923647703053
- 0:12.791991991307233
- 1:53.2275821177816
- 0:12.575375796695782
- 1:52.73215383967217
- 0:12.363453795688121
- 1:52.236357248648794
- 0:12.362699578239214
- 1:52.23416935413057
- 0:12.362748142406726
- 1:52.23335004605291
- 0:12.362792058021082
- 1:52.23332176227532
- 0:12.362802701125165
- 1:52.23328326314858
- system:index:20210920T101031_20210920T101056_T33UUU
- system:time_start:1632132975548
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.754290490405042
- 1:53.140557601716864
- 0:12.75430949635191
- 1:53.14048710356684
- 0:12.754995849830674
- 1:53.14009949614467
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.202474988719048
- 1:54.134774353559735
- 0:13.202354412690664
- 1:54.1347409667669
- 0:13.201463968063903
- 1:54.13362494532405
- 0:13.19976474432355
- 1:54.13035613753177
- 0:13.194726299997756
- 1:54.11949237669706
- 0:12.991287621166427
- 1:53.6737022233387
- 0:12.791991389974713
- 1:53.227580595560475
- 0:12.760676925948026
- 1:53.155786560770196
- 0:12.75507496942975
- 1:53.14273196443059
- 0:12.754290490405042
- 1:53.140557601716864
- system:index:20210920T101031_20210920T101056_T33UUV
- system:time_start:1632132960954
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210923T102031_20210923T102424_T32UQD
- system:time_start:1632392774415
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210923T102031_20210923T102424_T32UQE
- system:time_start:1632392760056
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210923T102031_20210923T102424_T33UUU
- system:time_start:1632392773572
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210923T102031_20210923T102424_T33UUV
- system:time_start:1632392759506
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.772886435916584
- 1:53.18992610553391
- 0:12.772805160551382
- 1:53.18990905418264
- 0:12.582231621882865
- 1:52.75703697716163
- 0:12.395602798722223
- 1:52.32379336819678
- 0:12.372007846255785
- 1:52.268344724894035
- 0:12.36772080080858
- 1:52.25821336889191
- 0:12.350548710886308
- 1:52.21713898167375
- 0:12.350399305994973
- 1:52.215155197526926
- 0:12.350505860298801
- 1:52.21506210599126
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.772949454149359
- 1:53.1899559993205
- 0:12.772886435916584
- 1:53.18992610553391
- system:index:20210925T101019_20210925T101413_T32UQD
- system:time_start:1632564972105
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16955630884026
- 1:54.075911023473104
- 0:13.169491658731916
- 1:54.07588141458455
- 0:13.169414109141014
- 1:54.075865928027866
- 0:13.169399316772571
- 1:54.07584515649229
- 0:13.165900263059573
- 1:54.06841031959964
- 0:12.955172574219937
- 1:53.60277405950859
- 0:12.749279076927646
- 1:53.136664596483705
- 0:12.736909319348609
- 1:53.107911186616526
- 0:12.735777678606272
- 1:53.10523950046743
- 0:12.735559032742724
- 1:53.10271890284025
- 0:12.735616176155075
- 1:53.102675668684
- 0:12.735666942732971
- 1:53.10262545297374
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- system:index:20210925T101019_20210925T101413_T32UQE
- system:time_start:1632564957225
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.790128414523867
- 1:53.22918760707141
- 0:12.79011318272951
- 1:53.22916703709699
- 0:12.78929770152972
- 1:53.22753223344032
- 0:12.606514175670162
- 1:52.81263466952874
- 0:12.42706680890284
- 1:52.3974752710556
- 0:12.36669403669298
- 1:52.255856217429574
- 0:12.359001854609621
- 1:52.23733806481495
- 0:12.357470482432987
- 1:52.2335263966679
- 0:12.357498748643295
- 1:52.23349327254195
- 0:12.357488555246212
- 1:52.23345295119355
- 0:12.35811941611142
- 1:52.23309292422743
- 0:12.358196576669535
- 1:52.23306819483536
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790252576440476
- 1:53.229231165558666
- 0:12.790198731550948
- 1:53.22920092722376
- 0:12.790128414523867
- 1:53.22918760707141
- system:index:20210925T101019_20210925T101413_T33UUU
- system:time_start:1632564971247
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19696787477602
- 1:54.13469198006072
- 0:13.196934609465563
- 1:54.134673926406
- 0:13.196889967473137
- 1:54.13467813471911
- 0:13.196860324022667
- 1:54.134663910741764
- 0:13.195948492095898
- 1:54.134100436052925
- 0:13.195929076310557
- 1:54.1340728826848
- 0:13.190891919154742
- 1:54.123210139406375
- 0:12.969139424724219
- 1:53.63368200085539
- 0:12.752329720149282
- 1:53.14375935863489
- 0:12.751541432444375
- 1:53.14157394061097
- 0:12.751617113714017
- 1:53.14012570274559
- 0:12.751680265903687
- 1:53.14008546167847
- 0:12.751737747953547
- 1:53.14003799176532
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20210925T101019_20210925T101413_T33UUV
- system:time_start:1632564956636
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20210928T101719_20210928T102156_T32UQD
- system:time_start:1632824770162
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20210928T101719_20210928T102156_T32UQE
- system:time_start:1632824755802
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20210928T101719_20210928T102156_T33UUU
- system:time_start:1632824769321
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20210928T101719_20210928T102156_T33UUV
- system:time_start:1632824755251
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.346923632874544
- 1:52.21563136469713
- 0:12.346935131232668
- 1:52.215564233501745
- 0:12.347555908744091
- 1:52.215145913769874
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.769365258345445
- 1:53.190069616516375
- 0:12.769221126513886
- 1:53.190022733222456
- 0:12.743534795007953
- 1:53.13252873192045
- 0:12.638148481035175
- 1:52.89402960905124
- 0:12.580943201660585
- 1:52.763012212739895
- 0:12.378035694630418
- 1:52.28975881525454
- 0:12.350162311489521
- 1:52.22363476997292
- 0:12.346923632874544
- 1:52.21563136469713
- system:index:20210930T101031_20210930T101420_T32UQD
- system:time_start:1632996978145
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.167616610293768
- 1:54.07597836214712
- 0:13.166496195834501
- 1:54.0743319748634
- 0:13.164179465858984
- 1:54.06954988402142
- 0:13.159498405260857
- 1:54.059457015255546
- 0:12.949116837858547
- 1:53.59622834397474
- 0:12.743534607990266
- 1:53.13252833500255
- 0:12.735680972603394
- 1:53.11442594625275
- 0:12.73116609739647
- 1:53.10376528012076
- 0:12.7310906026583
- 1:53.10289360062849
- 0:12.731492117040062
- 1:53.10275654552164
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20210930T101031_20210930T101420_T32UQE
- system:time_start:1632996963263
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.787495773379822
- 1:53.22918001024985
- 0:12.786558533590924
- 1:53.228581666960594
- 0:12.78491865141756
- 1:53.225293357432484
- 0:12.781687975037356
- 1:53.21821899282776
- 0:12.768806179580888
- 1:53.1893866988753
- 0:12.638551828596803
- 1:52.89501147149407
- 0:12.585525061207415
- 1:52.77363406039577
- 0:12.580791123295716
- 1:52.762747252233126
- 0:12.492862759953624
- 1:52.55913506963403
- 0:12.377893456674006
- 1:52.289559313930326
- 0:12.355553643906667
- 1:52.23617825234528
- 0:12.354832936167409
- 1:52.23345153381524
- 0:12.354852705074116
- 1:52.23311764382573
- 0:12.355264777101148
- 1:52.23300249879705
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- system:index:20210930T101031_20210930T101420_T33UUU
- system:time_start:1632996977285
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.1940995356185
- 1:54.1346178018617
- 0:13.194079046263894
- 1:54.13459883341059
- 0:13.193203554815806
- 1:54.133501261001065
- 0:13.192352279083648
- 1:54.131863110548835
- 0:13.184798670405435
- 1:54.115567546093686
- 0:12.963504862424921
- 1:53.62819221576061
- 0:12.747121897061971
- 1:53.14042601087601
- 0:12.74715013154002
- 1:53.14039223434336
- 0:12.747139422475975
- 1:53.14035158684406
- 0:12.747780505029082
- 1:53.13998964110576
- 0:12.747859067650731
- 1:53.139964670259175
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.194214264617418
- 1:54.134650661851175
- 0:13.194165429266228
- 1:54.1346240970834
- 0:13.1940995356185
- 1:54.1346178018617
- system:index:20210930T101031_20210930T101420_T33UUV
- system:time_start:1632996962669
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211003T101851_20211003T101849_T32UQD
- system:time_start:1633256775900
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211003T101851_20211003T101849_T32UQE
- system:time_start:1633256761553
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211003T101851_20211003T101849_T33UUU
- system:time_start:1633256775060
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211003T101851_20211003T101849_T33UUV
- system:time_start:1633256761002
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.345525084803931
- 1:52.21520720235094
- 0:12.34557112322897
- 1:52.21520224084041
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.766677065088482
- 1:53.19015471959899
- 0:12.766614056903457
- 1:53.19012482172612
- 0:12.766532790433796
- 1:53.19010776525426
- 0:12.749745421950482
- 1:53.15230103761367
- 0:12.551786699406232
- 1:52.69993926695834
- 0:12.358090284948709
- 1:52.24715508604059
- 0:12.345247678223924
- 1:52.216749957321255
- 0:12.345145725866058
- 1:52.21539437125684
- 0:12.345185669226849
- 1:52.215363970850206
- 0:12.345191624712292
- 1:52.21532170245894
- 0:12.345525084803931
- 1:52.21520720235094
- system:index:20211005T101029_20211005T101024_T32UQD
- system:time_start:1633428974054
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.72846630530846
- 1:53.103289342469225
- 0:12.728451317119173
- 1:53.10325268409541
- 0:12.729039206436834
- 1:53.102860050540116
- 0:12.729113924408946
- 1:53.102831178431714
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164983314447332
- 1:54.076069714156716
- 0:13.164930911687296
- 1:54.076045678197666
- 0:13.164858667853546
- 1:54.076042456502144
- 0:13.163808954225736
- 1:54.07497065756858
- 0:12.949242631395268
- 1:53.60243057989572
- 0:12.739674209027918
- 1:53.12941166161709
- 0:12.729567726139583
- 1:53.10598301644056
- 0:12.72844025464409
- 1:53.10331985892267
- 0:12.72846630530846
- 1:53.103289342469225
- system:index:20211005T101029_20211005T101024_T32UQE
- system:time_start:1633428959172
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.7839117009891
- 1:53.22908418230497
- 0:12.783841354447798
- 1:53.22907077829644
- 0:12.783826127740516
- 1:53.22905020732677
- 0:12.781381906286864
- 1:53.22414829905497
- 0:12.771724341005667
- 1:53.20238826020274
- 0:12.56326291018561
- 1:52.72624048727071
- 0:12.359143670491834
- 1:52.24975215991698
- 0:12.352985334477797
- 1:52.23504262773355
- 0:12.352981936801303
- 1:52.2350198582582
- 0:12.35309954045645
- 1:52.23304402426776
- 0:12.353161697050451
- 1:52.23300393360066
- 0:12.353218502457787
- 1:52.23295659088384
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20211005T101029_20211005T101024_T33UUU
- system:time_start:1633428973195
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.191333413794135
- 1:54.13456612757564
- 0:13.191317723130151
- 1:54.134545608885674
- 0:13.189622443143703
- 1:54.13128269738681
- 0:13.182069902851348
- 1:54.11498700821023
- 0:12.990338009395582
- 1:53.693644164263745
- 0:12.80230048100884
- 1:53.27200664544135
- 0:12.744433067669405
- 1:53.1403750955649
- 0:12.744461303906613
- 1:53.140341319743605
- 0:12.744450598482523
- 1:53.140300671916755
- 0:12.74509165093512
- 1:53.139938663376746
- 0:12.745170250305895
- 1:53.13991377397505
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.191460789016157
- 1:54.13460934995664
- 0:13.191405407818849
- 1:54.13457927987779
- 0:13.191333413794135
- 1:54.13456612757564
- system:index:20211005T101029_20211005T101024_T33UUV
- system:time_start:1633428958580
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211008T101829_20211008T102448_T32UQD
- system:time_start:1633688771882
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211008T101829_20211008T102448_T32UQE
- system:time_start:1633688757530
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211008T101829_20211008T102448_T33UUU
- system:time_start:1633688771043
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211008T101829_20211008T102448_T33UUV
- system:time_start:1633688756978
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.343131396482702
- 1:52.21529793541269
- 0:12.343204946458702
- 1:52.215269405817686
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.766677065088482
- 1:53.19015471959899
- 0:12.766590148338272
- 1:53.19014337168467
- 0:12.765592865374334
- 1:53.18960436296038
- 0:12.763364153935912
- 1:53.18479175076315
- 0:12.564213836740773
- 1:52.73248584086518
- 0:12.369355326866069
- 1:52.27975353300613
- 0:12.344739111988389
- 1:52.221630171534805
- 0:12.342576960524847
- 1:52.21628562084866
- 0:12.342533032838398
- 1:52.215701016015146
- 0:12.343131396482702
- 1:52.21529793541269
- system:index:20211010T100941_20211010T101120_T32UQD
- system:time_start:1633860979120
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.728404756704116
- 1:53.102943539710424
- 0:12.728512678183954
- 1:53.10285009668612
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.162119972179344
- 1:54.076168972010606
- 0:13.160953166914387
- 1:54.07398061042044
- 0:13.156271757243761
- 1:54.06388643463129
- 0:13.121163075690397
- 1:53.98737860666923
- 0:13.101307196494291
- 1:53.94380314753172
- 0:13.074509802890288
- 1:53.88480968101412
- 0:12.901621257500999
- 1:53.49929626874286
- 0:12.732009699700214
- 1:53.11346197989164
- 0:12.728623031120371
- 1:53.10546406876257
- 0:12.728404756704116
- 1:53.102943539710424
- system:index:20211010T100941_20211010T101120_T32UQE
- system:time_start:1633860964220
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783067440516646
- 1:53.22909773761695
- 0:12.78301360702536
- 1:53.22906749538586
- 0:12.782943261642453
- 1:53.22905409075062
- 0:12.782928035661886
- 1:53.22903351963882
- 0:12.782112867123205
- 1:53.2273986658796
- 0:12.576868321886154
- 1:52.76131846675781
- 0:12.37581740165183
- 1:52.29490907568046
- 0:12.364234742742664
- 1:52.26767215360547
- 0:12.351134069284326
- 1:52.2366208502965
- 0:12.350380437177886
- 1:52.234432872321136
- 0:12.350466695306658
- 1:52.23298486576352
- 0:12.350528852869566
- 1:52.23294477668823
- 0:12.350585585757985
- 1:52.23289752559637
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20211010T100941_20211010T101120_T33UUU
- system:time_start:1633860978260
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.189561395570163
- 1:54.13458079566735
- 0:13.188598249441077
- 1:54.13398548352077
- 0:13.186892790551035
- 1:54.130702467741436
- 0:13.181011024151712
- 1:54.11820735276233
- 0:13.17849486447187
- 1:54.11277556594912
- 0:13.097553175707363
- 1:53.93568991046215
- 0:13.07928983935921
- 1:53.89548534228847
- 0:13.041219988217644
- 1:53.8112655141507
- 0:12.745971363535961
- 1:53.14525894191678
- 0:12.744375292291217
- 1:53.141449823864455
- 0:12.744371683614062
- 1:53.14142726568073
- 0:12.744447059872936
- 1:53.13999011108546
- 0:12.744567664581254
- 1:53.13990232898189
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20211010T100941_20211010T101120_T33UUV
- system:time_start:1633860963624
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211013T101951_20211013T102427_T32UQD
- system:time_start:1634120776586
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211013T101951_20211013T102427_T32UQE
- system:time_start:1634120762239
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211013T101951_20211013T102427_T33UUU
- system:time_start:1634120775748
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211013T101951_20211013T102427_T33UUV
- system:time_start:1634120761687
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.757425287538089
- 1:53.18876330387353
- 0:12.756338358662758
- 1:53.18663402607891
- 0:12.751882552082058
- 1:53.176714684739636
- 0:12.634160782458897
- 1:52.91034202559773
- 0:12.539764574051532
- 1:52.69409320132481
- 0:12.520130321924695
- 1:52.64880693267699
- 0:12.488584650121936
- 1:52.5758069828677
- 0:12.450631017636104
- 1:52.48733616651067
- 0:12.414972402310038
- 1:52.40364480205507
- 0:12.360127066175291
- 1:52.274080318645176
- 0:12.34084031173907
- 1:52.22821657925454
- 0:12.336520559826962
- 1:52.21753649678728
- 0:12.33636505727609
- 1:52.215463213316966
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.75850435198082
- 1:53.19041321420421
- 0:12.757425287538089
- 1:53.18876330387353
- system:index:20211015T101029_20211015T101504_T32UQD
- system:time_start:1634292975135
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.71952329753253
- 1:53.10356944640936
- 0:12.7195083580204
- 1:53.103532865719224
- 0:12.720096256899058
- 1:53.10314020055138
- 0:12.720171012478453
- 1:53.10311141408093
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.158581207954619
- 1:54.07629158574562
- 0:13.158528773965317
- 1:54.07626746615015
- 0:13.158456535658331
- 1:54.076264239937494
- 0:13.15740702453911
- 1:54.075192461155765
- 0:13.046219606074523
- 1:53.83314780037973
- 0:12.936380936236192
- 1:53.590982031929464
- 0:12.720624258434947
- 1:53.10626353667654
- 0:12.719497241260017
- 1:53.10359996087652
- 0:12.71952329753253
- 1:53.10356944640936
- system:index:20211015T101029_20211015T101504_T32UQE
- system:time_start:1634292960231
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.775819987635199
- 1:53.228962629137506
- 0:12.77488286840655
- 1:53.22836420001096
- 0:12.774057887033148
- 1:53.226709016928275
- 0:12.637320072651644
- 1:52.917645947009476
- 0:12.610359116197483
- 1:52.85614253042221
- 0:12.54249685774415
- 1:52.7004542492811
- 0:12.489955487178584
- 1:52.5790364983622
- 0:12.480576520550938
- 1:52.557255529262015
- 0:12.44393873694207
- 1:52.47176048709963
- 0:12.379594631180668
- 1:52.32035269646968
- 0:12.357990335927218
- 1:52.26915110823894
- 0:12.343359190295084
- 1:52.234276970014776
- 0:12.343443673591906
- 1:52.23286128527246
- 0:12.343855832154574
- 1:52.232746174904634
- 0:13.678395413453838
- 1:52.255238875052065
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- system:index:20211015T101029_20211015T101504_T33UUU
- system:time_start:1634292974272
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.618960486124685
- 1:54.14027336359743
- 0:13.185035769184287
- 1:54.13451259511774
- 0:13.18498694663024
- 1:54.13448602586687
- 0:13.18492110163004
- 1:54.13447980497637
- 0:13.184900580223074
- 1:54.1344607543589
- 0:13.184024271772408
- 1:54.13336188000507
- 0:12.958010434265068
- 1:53.63861724824874
- 0:12.737092160911647
- 1:53.14347071009886
- 0:12.736304532990472
- 1:53.141285130192024
- 0:12.73638078499875
- 1:53.1398369865439
- 0:12.736443905971774
- 1:53.13979667531487
- 0:12.7364981809594
- 1:53.13975198286573
- 0:12.736522896873218
- 1:53.13974963540026
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- system:index:20211015T101029_20211015T101504_T33UUV
- system:time_start:1634292959634
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211018T101939_20211018T102105_T32UQD
- system:time_start:1634552772684
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211018T101939_20211018T102105_T32UQE
- system:time_start:1634552758338
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211018T101939_20211018T102105_T33UUU
- system:time_start:1634552771846
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211018T101939_20211018T102105_T33UUV
- system:time_start:1634552757786
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:12.764884951809924
- 1:53.190211446324525
- 0:12.764821946496076
- 1:53.190181547284304
- 0:12.76474596929852
- 1:53.190165585092416
- 0:12.764731945838342
- 1:53.19014472730867
- 0:12.55277689132059
- 1:52.7066554257296
- 0:12.345697009023075
- 1:52.222682275311115
- 0:12.343534698273563
- 1:52.217337823662106
- 0:12.343385643399108
- 1:52.21535435145997
- 0:12.343442149007561
- 1:52.21531125270007
- 0:12.34349220841784
- 1:52.2152612666215
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- system:index:20211020T101041_20211020T101421_T32UQD
- system:time_start:1634724979203
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.163034499165272
- 1:54.07613731268385
- 0:13.160737646008794
- 1:54.07182906569153
- 0:12.980685575273158
- 1:53.676134979296215
- 0:12.804158865657486
- 1:53.280096673534366
- 0:12.791754143526143
- 1:53.2518892228996
- 0:12.741177580151605
- 1:53.136380098588134
- 0:12.73106850708315
- 1:53.112951773281615
- 0:12.727682143063545
- 1:53.104953881842896
- 0:12.727510485305968
- 1:53.10297162837818
- 0:12.727618370889822
- 1:53.10287810685113
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20211020T101041_20211020T101421_T32UQE
- system:time_start:1634724964313
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.782045065904459
- 1:53.229037407614626
- 0:12.782029954212417
- 1:53.229016824006884
- 0:12.77958590109354
- 1:53.22411480181662
- 0:12.777170376535047
- 1:53.21867387743836
- 0:12.561472611937674
- 1:52.726473470479
- 0:12.350416525554582
- 1:52.233905798047
- 0:12.350413239537197
- 1:52.233883017191715
- 0:12.350445240647058
- 1:52.23334411616786
- 0:12.350471216832915
- 1:52.233293458288784
- 0:12.351098414011165
- 1:52.232935510828895
- 0:12.35117557255649
- 1:52.232910786763725
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.782169318157482
- 1:53.22908096376881
- 0:12.782115486091206
- 1:53.229050721050825
- 0:12.782045065904459
- 1:53.229037407614626
- system:index:20211020T101041_20211020T101421_T33UUU
- system:time_start:1634724978343
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.189569760807998
- 1:54.1345516741236
- 0:13.189492213398026
- 1:54.13453753023197
- 0:13.18863413187849
- 1:54.13288588072742
- 0:13.186115531188639
- 1:54.12745312798577
- 0:12.992639170843113
- 1:53.70258289339255
- 0:12.802923123958278
- 1:53.277412662652594
- 0:12.7876206541842
- 1:53.242604325089594
- 0:12.746670118226978
- 1:53.149048420567006
- 0:12.743478983624307
- 1:53.14143286669343
- 0:12.74347545140442
- 1:53.141410216787044
- 0:12.743550752185834
- 1:53.139973074630234
- 0:12.743671508508523
- 1:53.139885360662255
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.189625021956498
- 1:54.13458175825475
- 0:13.189569760807998
- 1:54.1345516741236
- system:index:20211020T101041_20211020T101421_T33UUV
- system:time_start:1634724963718
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211023T102101_20211023T102426_T32UQD
- system:time_start:1634984776443
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211023T102101_20211023T102426_T32UQE
- system:time_start:1634984762094
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211023T102101_20211023T102426_T33UUU
- system:time_start:1634984775604
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211023T102101_20211023T102426_T33UUV
- system:time_start:1634984761542
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.758519733035232
- 1:53.19041271268385
- 0:12.7574754730657
- 1:53.18930760804527
- 0:12.756385675831373
- 1:53.18717252846461
- 0:12.754169347554466
- 1:53.182383986833514
- 0:12.744134832998299
- 1:53.16003340428964
- 0:12.595635054607458
- 1:52.822470665961255
- 0:12.378330293309974
- 1:52.31673374454358
- 0:12.35259910856274
- 1:52.25594587787966
- 0:12.337603078261724
- 1:52.22021328258622
- 0:12.336520559826962
- 1:52.21753649678728
- 0:12.33636505727609
- 1:52.215463213316966
- 0:13.530749715810217
- 1:52.175585354190666
- system:index:20211025T101029_20211025T101120_T32UQD
- system:time_start:1635156975389
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.720096256899058
- 1:53.10314020055138
- 0:12.720171012478453
- 1:53.10311141408093
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.15583745623104
- 1:54.07638654036605
- 0:13.155698771113762
- 1:54.07634899045525
- 0:13.154606585793989
- 1:54.074743298859104
- 0:13.137029454228324
- 1:54.036485924744674
- 0:12.926443668683504
- 1:53.571880157395164
- 0:12.72067072529575
- 1:53.10680166130071
- 0:12.719540074043426
- 1:53.10412961718084
- 0:12.719489616705289
- 1:53.10354532247407
- 0:12.720096256899058
- 1:53.10314020055138
- system:index:20211025T101029_20211025T101120_T32UQE
- system:time_start:1635156960494
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.774984152775577
- 1:53.22894705027138
- 0:12.774854627437998
- 1:53.2289023895401
- 0:12.773215778097443
- 1:53.22561438998205
- 0:12.623815596946258
- 1:52.88716434857733
- 0:12.590579208625352
- 1:52.81096326418998
- 0:12.497819076299308
- 1:52.5964682236037
- 0:12.37730717071151
- 1:52.31436667182617
- 0:12.35261282930543
- 1:52.25608077380313
- 0:12.344144757365084
- 1:52.23592407057827
- 0:12.343391473961569
- 1:52.233736154323665
- 0:12.343443673591906
- 1:52.23286128527246
- 0:12.343855832154574
- 1:52.232746174904634
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.774984152775577
- 1:53.22894705027138
- system:index:20211025T101029_20211025T101120_T33UUU
- system:time_start:1635156974528
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.735498721192478
- 1:53.140171089994425
- 0:12.735487914692412
- 1:53.14013045335708
- 0:12.73612914211683
- 1:53.13976856722634
- 0:12.736207701851079
- 1:53.13974360527968
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.182282258714546
- 1:54.134471075897274
- 0:13.182233400411178
- 1:54.13444442504936
- 0:13.182161849636016
- 1:54.13443765203689
- 0:13.181270930514394
- 1:54.133320412393395
- 0:13.170357462764798
- 1:54.109955530172975
- 0:13.162816874882672
- 1:54.093659877895924
- 0:12.950074311828727
- 1:53.6244567004461
- 0:12.741876955487294
- 1:53.15489222063852
- 0:12.735470441705461
- 1:53.14020478404874
- 0:12.735498721192478
- 1:53.140171089994425
- system:index:20211025T101029_20211025T101120_T33UUV
- system:time_start:1635156959895
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211028T102039_20211028T102038_T32UQD
- system:time_start:1635416772637
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211028T102039_20211028T102038_T32UQE
- system:time_start:1635416758297
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211028T102039_20211028T102038_T33UUU
- system:time_start:1635416771800
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211028T102039_20211028T102038_T33UUV
- system:time_start:1635416757745
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.763925828089171
- 1:53.1902098647319
- 0:12.763844565432896
- 1:53.19019280606571
- 0:12.565540458165946
- 1:52.73784249587963
- 0:12.37152025519499
- 1:52.285088254675934
- 0:12.345818454334822
- 1:52.224297813881456
- 0:12.342576960524847
- 1:52.21628562084866
- 0:12.342535830886533
- 1:52.21573824239479
- 0:12.342554805540704
- 1:52.21568636606305
- 0:12.343131396482702
- 1:52.21529793541269
- 0:12.343204946458702
- 1:52.215269405817686
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76398886948041
- 1:53.19023984379334
- 0:12.763925828089171
- 1:53.1902098647319
- system:index:20211030T101141_20211030T101420_T32UQD
- system:time_start:1635588978422
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.725757358904135
- 1:53.1034039447821
- 0:12.72576846379912
- 1:53.10333684940628
- 0:12.726397815475355
- 1:53.10291638196706
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.162239628994309
- 1:54.07616481278918
- 0:13.162094574553777
- 1:54.07612137977754
- 0:13.160953127444943
- 1:54.0739805302207
- 0:13.149228391531969
- 1:54.04847831064111
- 0:12.943037375835464
- 1:53.5942704055007
- 0:12.741458579014228
- 1:53.13960947839036
- 0:12.728012054923914
- 1:53.1087303263879
- 0:12.725757358904135
- 1:53.1034039447821
- system:index:20211030T101141_20211030T101420_T32UQE
- system:time_start:1635588963532
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.781271130469108
- 1:53.229064273801384
- 0:12.781217299827844
- 1:53.22903403059643
- 0:12.781146956762196
- 1:53.22902062470779
- 0:12.78113173223519
- 1:53.22900005331173
- 0:12.778687876467938
- 1:53.22409808719175
- 0:12.771444708628426
- 1:53.207777698562886
- 0:12.527587607975756
- 1:52.64996781854723
- 0:12.369616963875945
- 1:52.28074204126017
- 0:12.350352262765828
- 1:52.2349835581431
- 0:12.3503489412354
- 1:52.23496069837709
- 0:12.350466695306658
- 1:52.23298486576352
- 0:12.350528852869566
- 1:52.23294477668823
- 0:12.350585585757985
- 1:52.23289752559637
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20211030T101141_20211030T101420_T33UUU
- system:time_start:1635588977561
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.7417626113424
- 1:53.14025302683031
- 0:12.741786558893054
- 1:53.140235656765405
- 0:12.742402930002275
- 1:53.139887693766205
- 0:12.742481528699424
- 1:53.13986280641939
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.189625021956498
- 1:54.13458175825475
- 0:13.189537930558492
- 1:54.134566305965386
- 0:13.188607666370244
- 1:54.133991292894024
- 0:13.188587720680346
- 1:54.133965152368376
- 0:13.186892671754276
- 1:54.130702227001755
- 0:13.174310835777165
- 1:54.10354315397842
- 0:12.955631207493337
- 1:53.62212451434543
- 0:12.741744334020744
- 1:53.14032410898243
- 0:12.741772572016846
- 1:53.14029033387256
- 0:12.7417626113424
- 1:53.14025302683031
- system:index:20211030T101141_20211030T101420_T33UUV
- system:time_start:1635588962936
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211102T102201_20211102T102315_T32UQD
- system:time_start:1635848775375
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211102T102201_20211102T102315_T32UQE
- system:time_start:1635848761022
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211102T102201_20211102T102315_T33UUU
- system:time_start:1635848774535
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211102T102201_20211102T102315_T33UUV
- system:time_start:1635848760471
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.360597119577953
- 1:52.26867025127758
- 0:12.355231636518514
- 1:52.255870900024505
- 0:12.342351372734697
- 1:52.22493569777108
- 0:12.339110431938316
- 1:52.216923503967124
- 0:12.338995257527376
- 1:52.21538871271395
- 0:13.530896190790584
- 1:52.17557974653692
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.634044347435015
- 1:53.15951757193961
- 0:12.76029646225647
- 1:53.190356586949584
- 0:12.759216648816942
- 1:53.18870559905667
- 0:12.75699825817149
- 1:53.18391360003736
- 0:12.74917555644517
- 1:53.16635060439376
- 0:12.672393615169693
- 1:52.992814276848605
- 0:12.642504869145862
- 1:52.92465718273482
- 0:12.586307406791422
- 1:52.795769824252815
- 0:12.383134815050981
- 1:52.32199275346985
- 0:12.360597119577953
- 1:52.26867025127758
- system:index:20211104T101109_20211104T101445_T32UQD
- system:time_start:1636020974652
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.158461555313655
- 1:54.07629574073089
- 0:13.157295236136868
- 1:54.07410772964037
- 0:13.154981133784927
- 1:54.06932876839378
- 0:13.150302322412397
- 1:54.05923548317396
- 0:12.934373692367119
- 1:53.5840320916185
- 0:12.723493507153409
- 1:53.108332314665
- 0:12.722362663784697
- 1:53.10566023851489
- 0:12.722144766537543
- 1:53.10313969085868
- 0:12.72225269806673
- 1:53.10304625382225
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20211104T101109_20211104T101445_T32UQE
- system:time_start:1636020959761
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.777678562012442
- 1:53.228997342655745
- 0:12.77759351135894
- 1:53.22898160679885
- 0:12.776679109420803
- 1:53.22839776492055
- 0:12.775854133704765
- 1:53.22674258528691
- 0:12.673336596799707
- 1:52.994964802874854
- 0:12.585309495558247
- 1:52.79359164774707
- 0:12.381480607821304
- 1:52.31823627609304
- 0:12.359875139791265
- 1:52.26703495561764
- 0:12.353715391085977
- 1:52.2523282162191
- 0:12.34602425390878
- 1:52.23379729510144
- 0:12.346059426307484
- 1:52.23320826907606
- 0:12.346710338685938
- 1:52.23283688941743
- 0:12.346787495971476
- 1:52.23281216868141
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.777678562012442
- 1:53.228997342655745
- system:index:20211104T101109_20211104T101445_T33UUU
- system:time_start:1636020973791
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.18498694663024
- 1:54.13448602586687
- 0:13.184915392911176
- 1:54.134479254782896
- 0:13.18402537382218
- 1:54.13336311189858
- 0:13.183174492799914
- 1:54.13172506473113
- 0:13.177293778792743
- 1:54.119229848086675
- 0:13.172263125087802
- 1:54.10836628198575
- 0:12.953583380866304
- 1:53.626944180104616
- 0:12.739696848029352
- 1:53.14513998798597
- 0:12.738101280249952
- 1:53.14133079857303
- 0:12.738097751920941
- 1:53.14130814843074
- 0:12.738173279157095
- 1:53.139871007166626
- 0:12.73829392817002
- 1:53.139783311689335
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.185035769184287
- 1:54.13451259511774
- 0:13.18498694663024
- 1:54.13448602586687
- system:index:20211104T101109_20211104T101445_T33UUV
- system:time_start:1636020959163
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211107T102129_20211107T102157_T32UQD
- system:time_start:1636280771550
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211107T102129_20211107T102157_T32UQE
- system:time_start:1636280757202
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211107T102129_20211107T102157_T33UUU
- system:time_start:1636280770712
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211107T102129_20211107T102157_T33UUV
- system:time_start:1636280756650
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211112T102251_20211112T102423_T32UQD
- system:time_start:1636712773112
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211112T102251_20211112T102423_T32UQE
- system:time_start:1636712758757
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211112T102251_20211112T102423_T33UUU
- system:time_start:1636712772272
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211112T102251_20211112T102423_T33UUV
- system:time_start:1636712758206
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.341684258381287
- 1:52.215424521780626
- 0:12.341713864460019
- 1:52.21541118158311
- 0:12.342018236484806
- 1:52.21530660401331
- 0:12.342064309018197
- 1:52.2153017226101
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.763092871220705
- 1:53.19026814165076
- 0:12.76302975536901
- 1:53.190238253766445
- 0:12.762948456473605
- 1:53.19022111493086
- 0:12.549899249793814
- 1:52.70404342577647
- 0:12.341781180343778
- 1:52.217388003561354
- 0:12.341638909053339
- 1:52.21549383897766
- 0:12.341678708772568
- 1:52.21546337293818
- 0:12.341684258381287
- 1:52.215424521780626
- system:index:20211114T101159_20211114T101201_T32UQD
- system:time_start:1636884972683
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.733349026127817
- 1:54.05500661759526
- 0:13.161214576864792
- 1:54.07620037090388
- 0:13.16009511158163
- 1:54.07455502484312
- 0:13.158962656164517
- 1:54.07243055595433
- 0:13.148475505090255
- 1:54.05012371839074
- 0:13.111091727047333
- 1:53.968834493130764
- 0:13.025113868954087
- 1:53.77961924216409
- 0:12.907917480721196
- 1:53.518519069511484
- 0:12.792230758660942
- 1:53.25727082874637
- 0:12.733791354373272
- 1:53.12365987368923
- 0:12.725893477347563
- 1:53.10500996327928
- 0:12.725714109202334
- 1:53.1029378048664
- 0:13.624404108709518
- 1:53.071357494195986
- system:index:20211114T101159_20211114T101201_T32UQE
- system:time_start:1636884957796
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.780248782289588
- 1:53.229003925681155
- 0:12.780233672049208
- 1:53.22898334179119
- 0:12.77941858738611
- 1:53.22734855644153
- 0:12.766535161817181
- 1:53.19851489330179
- 0:12.761711875411935
- 1:53.187634982055265
- 0:12.562074506353829
- 1:52.73161128376425
- 0:12.36642228808306
- 1:52.27527503818996
- 0:12.34869460602452
- 1:52.233330494320974
- 0:12.348722628966408
- 1:52.23329682275181
- 0:12.348712343923282
- 1:52.23325601749672
- 0:12.349343225353035
- 1:52.23289604451834
- 0:12.349420383394529
- 1:52.23287132178483
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780372953412835
- 1:53.22904757588839
- 0:12.7803191241966
- 1:53.22901733219651
- 0:12.780248782289588
- 1:53.229003925681155
- system:index:20211114T101159_20211114T101201_T33UUU
- system:time_start:1636884971822
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.18767857844998
- 1:54.13455239878436
- 0:13.185951443960983
- 1:54.13122774356876
- 0:13.175861337629343
- 1:54.110039270128716
- 0:13.173346234329383
- 1:54.10460727764134
- 0:13.109048922198294
- 1:53.964458190458345
- 0:13.025361181927924
- 1:53.78026027049393
- 0:12.93667325555444
- 1:53.58296115833824
- 0:12.791446488193523
- 1:53.25562225295192
- 0:12.7617117253943
- 1:53.187634664312434
- 0:12.741682174307737
- 1:53.1413892056637
- 0:12.741756522598076
- 1:53.139973371917
- 0:12.742176266728972
- 1:53.13985696582617
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20211114T101159_20211114T101201_T33UUV
- system:time_start:1636884957202
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211117T102219_20211117T102218_T32UQD
- system:time_start:1637144769326
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211117T102219_20211117T102218_T32UQE
- system:time_start:1637144754970
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211117T102219_20211117T102218_T33UUU
- system:time_start:1637144768487
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211117T102219_20211117T102218_T33UUV
- system:time_start:1637144754418
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.354886503951676
- 1:52.21494037292314
- 0:12.354910433030971
- 1:52.21493684743207
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:12.775637592103482
- 1:53.18987075604691
- 0:12.775574532019466
- 1:53.18984078457958
- 0:12.775498540560514
- 1:53.189824830595
- 0:12.77548450866554
- 1:53.18980397454011
- 0:12.562750126818193
- 1:52.703657407074864
- 0:12.35493240262655
- 1:52.217014473983994
- 0:12.354782769249859
- 1:52.21503053706143
- 0:12.35483926775337
- 1:52.214987432453874
- 0:12.354886503951676
- 1:52.21494037292314
- system:index:20211119T101321_20211119T101416_T32UQD
- system:time_start:1637316973854
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.174129191270419
- 1:54.07575224960105
- 0:13.174069775198056
- 1:54.075725021486136
- 0:13.173996235155588
- 1:54.07571543611639
- 0:13.17397766293234
- 1:54.075695762018334
- 0:13.172897596057318
- 1:54.07410912870285
- 0:12.959394274819234
- 1:53.60425338506342
- 0:12.750834388194015
- 1:53.13391728837801
- 0:12.741849000844338
- 1:53.11315263034207
- 0:12.738460646556367
- 1:53.10515510257334
- 0:12.738241827961732
- 1:53.10263459755773
- 0:12.738299045318078
- 1:53.102591270397006
- 0:12.738349733642414
- 1:53.102541145125684
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- system:index:20211119T101321_20211119T101416_T32UQE
- system:time_start:1637316958983
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792946960017524
- 1:53.22928111453111
- 0:12.792891939537204
- 1:53.22925016954305
- 0:12.792820488094232
- 1:53.2292352195477
- 0:12.792806428167502
- 1:53.229214355041634
- 0:12.780728031308376
- 1:53.2020169200156
- 0:12.577326195479642
- 1:52.73704941045147
- 0:12.378065149312317
- 1:52.27175724656576
- 0:12.36342180967745
- 1:52.23689602786673
- 0:12.362667656957127
- 1:52.23470827293419
- 0:12.36275351042327
- 1:52.23326025006332
- 0:12.36281562790448
- 1:52.233220075021
- 0:12.362872352771689
- 1:52.23317281719261
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- system:index:20211119T101321_20211119T101416_T33UUU
- system:time_start:1637316972996
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.754345748632732
- 1:53.140237890479234
- 0:12.7543572939146
- 1:53.14019599362537
- 0:12.754723924300318
- 1:53.14009432213876
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.20155707068725
- 1:54.13476060723407
- 0:13.201469961166016
- 1:54.13474516515951
- 0:13.200530169121826
- 1:54.134164429199544
- 0:13.198823510493282
- 1:54.13088135061673
- 0:13.018381548669517
- 1:53.73510567133956
- 0:12.841214352098325
- 1:53.33906976739844
- 0:12.809713487753635
- 1:53.26782744290182
- 0:12.780727956165766
- 1:53.20201676112909
- 0:12.754234481908975
- 1:53.14163642933147
- 0:12.75423090446543
- 1:53.1416137005088
- 0:12.754301202133078
- 1:53.14026634776819
- 0:12.754345748632732
- 1:53.140237890479234
- system:index:20211119T101321_20211119T101416_T33UUV
- system:time_start:1637316958394
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211122T102331_20211122T102421_T32UQD
- system:time_start:1637576771284
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211122T102331_20211122T102421_T32UQE
- system:time_start:1637576756922
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211122T102331_20211122T102421_T33UUU
- system:time_start:1637576770442
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211122T102331_20211122T102421_T33UUV
- system:time_start:1637576756371
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.347800336503324
- 1:52.21560648857079
- 0:12.347811833223517
- 1:52.21553935733922
- 0:12.348432715878253
- 1:52.21512102098351
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.768469211051766
- 1:53.190097961472695
- 0:12.768324930984154
- 1:53.19005100975836
- 0:12.747063331975594
- 1:53.14213167252776
- 0:12.742592934303676
- 1:53.13201857877873
- 0:12.65583708748736
- 1:52.93450086602449
- 0:12.50159215643096
- 1:52.577850992878716
- 0:12.349959521294776
- 1:52.22094221748357
- 0:12.347800336503324
- 1:52.21560648857079
- system:index:20211124T101239_20211124T101240_T32UQD
- system:time_start:1637748969863
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.167727071677572
- 1:54.0759745426715
- 0:13.167638124476865
- 1:54.075963451663135
- 0:13.166615823937208
- 1:54.07542922126602
- 0:13.165471910786454
- 1:54.073284116810946
- 0:12.951554359324996
- 1:53.60289386558922
- 0:12.742592897890578
- 1:53.13201824895892
- 0:12.733611867767854
- 1:53.11125293063498
- 0:12.7302288803098
- 1:53.1032637360964
- 0:12.730239939389612
- 1:53.103196561207874
- 0:12.730869303285536
- 1:53.10277614756995
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.167727071677572
- 1:54.0759745426715
- system:index:20211124T101239_20211124T101240_T32UQE
- system:time_start:1637748954990
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.355682381698301
- 1:52.23402389006175
- 0:12.355678982116471
- 1:52.234001121059585
- 0:12.355730363822705
- 1:52.233137332694376
- 0:12.356142437634166
- 1:52.233022184104584
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.78576190974339
- 1:53.229147840192944
- 0:12.785632238780263
- 1:53.22910320575627
- 0:12.784807204185734
- 1:53.2274488751117
- 0:12.774333283202857
- 1:53.20405552483442
- 0:12.680684455900439
- 1:52.99133185601632
- 0:12.65522806503346
- 1:52.933106617006246
- 0:12.598199352931724
- 1:52.80194599113195
- 0:12.373386259875426
- 1:52.27650925894772
- 0:12.355682381698301
- 1:52.23402389006175
- system:index:20211124T101239_20211124T101240_T33UUU
- system:time_start:1637748969005
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.194136400681664
- 1:54.13463689464847
- 0:13.194106719778988
- 1:54.134622589609684
- 0:13.193195357936853
- 1:54.13405938462637
- 0:13.193175869273796
- 1:54.13403217776864
- 0:13.189810080406662
- 1:54.12696984180725
- 0:13.181412208242959
- 1:54.10904444681583
- 0:13.178896595540834
- 1:54.10361270795238
- 0:12.960578366548082
- 1:53.62301799155878
- 0:12.74703591722608
- 1:53.142039927020186
- 0:12.74703242079431
- 1:53.14201710602188
- 0:12.74713585872318
- 1:53.14004102644257
- 0:12.74725646046883
- 1:53.13995324123949
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.194214264617418
- 1:54.134650661851175
- 0:13.194136400681664
- 1:54.13463689464847
- system:index:20211124T101239_20211124T101240_T33UUV
- system:time_start:1637748954399
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211127T102259_20211127T102319_T32UQD
- system:time_start:1638008766805
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211127T102259_20211127T102319_T32UQE
- system:time_start:1638008752444
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211127T102259_20211127T102319_T33UUU
- system:time_start:1638008765964
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211127T102259_20211127T102319_T33UUV
- system:time_start:1638008751893
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.770168487798811
- 1:53.19004417384519
- 0:12.76912261379915
- 1:53.188937651168466
- 0:12.599297005600906
- 1:52.80212194700857
- 0:12.432619840414311
- 1:52.41500591702711
- 0:12.372376031199725
- 1:52.27319108094221
- 0:12.358438415533387
- 1:52.24012930120143
- 0:12.350917481853912
- 1:52.22199419079688
- 0:12.34875459743945
- 1:52.2166499668365
- 0:12.348648391568425
- 1:52.21523928072888
- 0:12.349043256354099
- 1:52.21510369524913
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20211129T101351_20211129T101416_T32UQD
- system:time_start:1638180973609
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.167674625897885
- 1:54.075950427985255
- 0:13.167602379696564
- 1:54.075947208225784
- 0:13.16655266301888
- 1:54.07487542760689
- 0:13.056554572219241
- 1:53.83387747237404
- 0:12.947885922253123
- 1:53.59276101735969
- 0:12.734413028975856
- 1:53.11014849105447
- 0:12.732153743177259
- 1:53.10481360548757
- 0:12.731981885770447
- 1:53.10283127775482
- 0:12.732089801506097
- 1:53.102737831309284
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.167727071677572
- 1:54.0759745426715
- 0:13.167674625897885
- 1:54.075950427985255
- system:index:20211129T101351_20211129T101416_T32UQE
- system:time_start:1638180958726
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.355734170388647
- 1:52.23341703216198
- 0:12.355757741088118
- 1:52.233399716435926
- 0:12.356364201450807
- 1:52.23305364737912
- 0:12.356441325967758
- 1:52.233028840777486
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.787558174922678
- 1:53.22918115744251
- 0:12.787473033048068
- 1:53.22916552174907
- 0:12.786565899251611
- 1:53.22858638052502
- 0:12.78654720954715
- 1:53.22855874970733
- 0:12.607804446934939
- 1:52.82156251563527
- 0:12.432262947475406
- 1:52.41431460142566
- 0:12.374201069501506
- 1:52.27760668726702
- 0:12.35877791386236
- 1:52.24111027125931
- 0:12.355715224709275
- 1:52.23348703020761
- 0:12.355743491989863
- 1:52.233453906555695
- 0:12.355734170388647
- 1:52.23341703216198
- system:index:20211129T101351_20211129T101416_T33UUU
- system:time_start:1638180972750
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.748036522900936
- 1:53.14037193253384
- 0:12.748060355867574
- 1:53.14035457332696
- 0:12.748676710572035
- 1:53.1400065731126
- 0:12.74875527341533
- 1:53.13998160158144
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.194214264617418
- 1:54.134650661851175
- 0:13.194165429266228
- 1:54.1346240970834
- 0:13.194093865737795
- 1:54.13461733242861
- 0:13.1932024126815
- 1:54.13349994896486
- 0:12.990620429822373
- 1:53.68771541366265
- 0:12.79216833376099
- 1:53.24160980929871
- 0:12.752804686978868
- 1:53.1518621301235
- 0:12.7488006955257
- 1:53.14261359699758
- 0:12.748016650193165
- 1:53.14043910092346
- 0:12.748045931936403
- 1:53.14040754708269
- 0:12.748036522900936
- 1:53.14037193253384
- system:index:20211129T101351_20211129T101416_T33UUV
- system:time_start:1638180958133
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211202T102401_20211202T102433_T32UQD
- system:time_start:1638440770753
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211202T102401_20211202T102433_T32UQE
- system:time_start:1638440756394
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211202T102401_20211202T102433_T33UUU
- system:time_start:1638440769912
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211202T102401_20211202T102433_T33UUV
- system:time_start:1638440755843
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.767511746717672
- 1:53.1900972312404
- 0:12.767431643025253
- 1:53.19008238737966
- 0:12.766335951477528
- 1:53.18793710441436
- 0:12.751864876526104
- 1:53.156012087535565
- 0:12.549888859997006
- 1:52.69298039624669
- 0:12.352362689352997
- 1:52.22950859976621
- 0:12.3469606082969
- 1:52.216161248177244
- 0:12.346899166724405
- 1:52.215344552591795
- 0:12.346939109316118
- 1:52.21531415154906
- 0:12.346945062712457
- 1:52.21527188313455
- 0:12.347289858203156
- 1:52.21515346054683
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76757320945312
- 1:53.19012637801493
- 0:12.767511746717672
- 1:53.1900972312404
- system:index:20211204T101309_20211204T101309_T32UQD
- system:time_start:1638612969085
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.729692061112678
- 1:53.10281668195683
- 0:12.729738987419529
- 1:53.102811592124695
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16589798332256
- 1:54.076038016493854
- 0:13.165833768733782
- 1:54.076008526602415
- 0:13.165750877511163
- 1:54.075992447177036
- 0:13.163426722182267
- 1:54.07119507827522
- 0:12.955300193043728
- 1:53.613833676804234
- 0:12.7518648025656
- 1:53.156011678205395
- 0:12.729470802071091
- 1:53.104898190424784
- 0:12.729306792171045
- 1:53.10300518199288
- 0:12.729347196255672
- 1:53.10297460993052
- 0:12.729352876363018
- 1:53.1029323737746
- 0:12.729692061112678
- 1:53.10281668195683
- system:index:20211204T101309_20211204T101309_T32UQE
- system:time_start:1638612954211
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.353988271813197
- 1:52.23341500446459
- 0:12.353978124971357
- 1:52.23337426672122
- 0:12.354608884299871
- 1:52.23301427298985
- 0:12.35468604385202
- 1:52.23298954626128
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.784863641922332
- 1:53.22913110253703
- 0:12.784816114971456
- 1:53.22910435290231
- 0:12.784746051010995
- 1:53.229097352985605
- 0:12.783884883867907
- 1:53.227978483233905
- 0:12.78225211147314
- 1:53.22470395426528
- 0:12.750899072336498
- 1:53.1539842821931
- 0:12.640011786529124
- 1:52.90097485349185
- 0:12.495939068198682
- 1:52.56729330649032
- 0:12.353960397485247
- 1:52.23344874434503
- 0:12.353988271813197
- 1:52.23341500446459
- system:index:20211204T101309_20211204T101309_T33UUU
- system:time_start:1638612968226
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.745393763891686
- 1:53.140029960193466
- 0:12.745425611445889
- 1:53.14001799058691
- 0:12.74574917615616
- 1:53.139928285254854
- 0:12.745796718395159
- 1:53.13992562742396
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.192378551411378
- 1:54.13462310639914
- 0:13.192321952515652
- 1:54.134592325616694
- 0:13.192243412601181
- 1:54.13457643140177
- 0:13.182164342541062
- 1:54.112831061561614
- 0:12.96210582987085
- 1:53.62897754449802
- 0:12.746895912828197
- 1:53.1447370181971
- 0:12.745299850472902
- 1:53.140927931980926
- 0:12.745296203735663
- 1:53.14090529461551
- 0:12.745338540563603
- 1:53.14009687588418
- 0:12.745383089645708
- 1:53.14006842242581
- 0:12.745393763891686
- 1:53.140029960193466
- system:index:20211204T101309_20211204T101309_T33UUV
- system:time_start:1638612953619
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211207T102319_20211207T102344_T32UQD
- system:time_start:1638872766194
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211207T102319_20211207T102344_T32UQE
- system:time_start:1638872751840
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211207T102319_20211207T102344_T33UUU
- system:time_start:1638872765355
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211207T102319_20211207T102344_T33UUV
- system:time_start:1638872751287
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.766559940645989
- 1:53.190158430577235
- 0:12.765440028620153
- 1:53.18796575068296
- 0:12.76322256820927
- 1:53.18317708363105
- 0:12.556142023123568
- 1:52.70979241234095
- 0:12.353727353684564
- 1:52.23594618934338
- 0:12.348368016501356
- 1:52.2231460228101
- 0:12.346205440363194
- 1:52.21780165705487
- 0:12.34601572268607
- 1:52.215279703124324
- 0:12.346122393387603
- 1:52.21518660414758
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20211209T101411_20211209T101415_T32UQD
- system:time_start:1639044972404
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.729039206436834
- 1:53.102860050540116
- 0:12.729113924408946
- 1:53.102831178431714
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.164983314447332
- 1:54.076069714156716
- 0:13.16489441023952
- 1:54.076058700942774
- 0:13.163872144514214
- 1:54.07552436143613
- 0:13.162728405696438
- 1:54.07337939322778
- 0:13.148691756416088
- 1:54.043099799492815
- 0:12.937866566785962
- 1:53.5777104883339
- 0:12.731869698415485
- 1:53.11184741630052
- 0:12.728483196968584
- 1:53.10384942686057
- 0:12.72843261461732
- 1:53.10326522173101
- 0:12.729039206436834
- 1:53.102860050540116
- system:index:20211209T101411_20211209T101415_T32UQE
- system:time_start:1639044957516
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.7839117009891
- 1:53.22908418230497
- 0:12.783835983850446
- 1:53.22906977493141
- 0:12.783011018727336
- 1:53.22741559978253
- 0:12.771724453643875
- 1:53.20238849854511
- 0:12.764487877799716
- 1:53.18606873435655
- 0:12.645490602008747
- 1:52.91511053562536
- 0:12.587713879823143
- 1:52.782310770030016
- 0:12.35379917761901
- 1:52.236141064897446
- 0:12.35304546428226
- 1:52.233953114391326
- 0:12.353094257147454
- 1:52.23313380838706
- 0:12.353138065494448
- 1:52.23310554037209
- 0:12.35314974750102
- 1:52.2330637229293
- 0:12.353509633452662
- 1:52.23296317210305
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.783965535905205
- 1:53.229114424049136
- 0:12.7839117009891
- 1:53.22908418230497
- system:index:20211209T101411_20211209T101415_T33UUU
- system:time_start:1639044971544
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.191460789016157
- 1:54.13460934995664
- 0:13.191373577677917
- 1:54.13459391227608
- 0:13.190432587666201
- 1:54.134012315668315
- 0:13.18705696121205
- 1:54.12692828029459
- 0:13.182022731743475
- 1:54.116064997951774
- 0:12.986611724997035
- 1:53.68602988356453
- 0:12.795041339100312
- 1:53.255688873480885
- 0:12.76448772775617
- 1:53.1860684166252
- 0:12.746055359067023
- 1:53.14364058594237
- 0:12.745267393282043
- 1:53.141455297066386
- 0:12.745343340786802
- 1:53.140007060229685
- 0:12.745463944507522
- 1:53.13991927709296
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.191460789016157
- 1:54.13460934995664
- system:index:20211209T101411_20211209T101415_T33UUV
- system:time_start:1639044956921
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211212T102431_20211212T102427_T32UQD
- system:time_start:1639304770431
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211212T102431_20211212T102427_T32UQE
- system:time_start:1639304756071
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211212T102431_20211212T102427_T33UUU
- system:time_start:1639304769587
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211212T102431_20211212T102427_T33UUV
- system:time_start:1639304755520
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.76398886948041
- 1:53.19023984379334
- 0:12.763901918737115
- 1:53.19022841411509
- 0:12.762904407438766
- 1:53.189689243251514
- 0:12.748424368553389
- 1:53.15773969028653
- 0:12.603879850106013
- 1:52.83058534635231
- 0:12.461602912458764
- 1:52.503205466566
- 0:12.408742681611347
- 1:52.38007971434895
- 0:12.377591660445885
- 1:52.307040926224694
- 0:12.339033479750173
- 1:52.215855998885445
- 0:12.339044602618555
- 1:52.215788004200945
- 0:12.339665530842824
- 1:52.21536971780287
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.76398886948041
- 1:53.19023984379334
- system:index:20211214T101329_20211214T101409_T32UQD
- system:time_start:1639476967791
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.16132503150331
- 1:54.076196558271874
- 0:13.16117731061008
- 1:54.07615020614228
- 0:13.146003795388483
- 1:54.04373251727133
- 0:13.119125042599878
- 1:53.98528985462567
- 0:12.93186728166314
- 1:53.571701736716676
- 0:12.748424106473854
- 1:53.157739134424254
- 0:12.741692677402845
- 1:53.142300385974146
- 0:12.727117707423027
- 1:53.108758325709054
- 0:12.72484333932733
- 1:53.103385443880654
- 0:12.72550356488007
- 1:53.10294445298239
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.16132503150331
- 1:54.076196558271874
- system:index:20211214T101329_20211214T101409_T32UQE
- system:time_start:1639476952884
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.780264659775597
- 1:53.22904556725041
- 0:12.777790012805296
- 1:53.22408168249724
- 0:12.774560616780521
- 1:53.21700715691414
- 0:12.62950392607202
- 1:52.889166397874185
- 0:12.486550001390933
- 1:52.561159452510005
- 0:12.457666031261398
- 1:52.494178152593186
- 0:12.412564124168536
- 1:52.3890651917806
- 0:12.373085120740182
- 1:52.29646693804373
- 0:12.353030104029529
- 1:52.24907560131609
- 0:12.346869770121115
- 1:52.23435596572105
- 0:12.346954219477697
- 1:52.232940268025196
- 0:12.347366275434231
- 1:52.232825155043265
- 0:13.678248498138956
- 1:52.25523726139369
- system:index:20211214T101329_20211214T101409_T33UUU
- system:time_start:1639476966928
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.188612242960076
- 1:54.13456644667688
- 0:13.187696566446538
- 1:54.13341846489351
- 0:13.185998678039613
- 1:54.13014978089567
- 0:13.175908639238322
- 1:54.1089612838999
- 0:13.173393668996411
- 1:54.10352927450966
- 0:13.118253590540387
- 1:53.98348054593662
- 0:13.092466040821938
- 1:53.92697928808973
- 0:12.917921411084905
- 1:53.54029181581008
- 0:12.746444437482827
- 1:53.15336030966683
- 0:12.742442373068423
- 1:53.14411305043819
- 0:12.740826114775869
- 1:53.14025493476884
- 0:12.741551978750078
- 1:53.13984510703108
- 0:13.650819022336758
- 1:53.15362149465461
- system:index:20211214T101329_20211214T101409_T33UUV
- system:time_start:1639476952291
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211217T102329_20211217T102332_T32UQD
- system:time_start:1639736764996
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211217T102329_20211217T102332_T32UQE
- system:time_start:1639736750627
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211217T102329_20211217T102332_T33UUU
- system:time_start:1639736764149
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211217T102329_20211217T102332_T33UUV
- system:time_start:1639736750077
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.775520456985076
- 1:53.189874477286715
- 0:12.774399918849577
- 1:53.18768132466733
- 0:12.580970189335217
- 1:52.747091155839456
- 0:12.391606186639569
- 1:52.306099273624966
- 0:12.365863801569871
- 1:52.24531441548724
- 0:12.356219192398246
- 1:52.22238315413533
- 0:12.354055595147912
- 1:52.21703891897508
- 0:12.35390615411611
- 1:52.21505554017183
- 0:12.35401270306102
- 1:52.21496244528783
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- system:index:20211219T101431_20211219T101431_T32UQD
- system:time_start:1639908974495
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.737981919860706
- 1:53.10257914889916
- 0:12.738056674892514
- 1:53.102550349867634
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.174129191270419
- 1:54.07575224960105
- 0:13.174004485515296
- 1:54.07572492311064
- 0:13.172954724379307
- 1:54.07465344313988
- 0:13.169450076591946
- 1:54.067207714881874
- 0:12.952005433099723
- 1:53.588307318376295
- 0:12.739686065669726
- 1:53.10890341803959
- 0:12.737426158483174
- 1:53.10356864359961
- 0:12.73737548954104
- 1:53.10298435707788
- 0:12.737981919860706
- 1:53.10257914889916
- system:index:20211219T101431_20211219T101431_T32UQE
- system:time_start:1639908959619
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.360981090781442
- 1:52.233604959119106
- 0:12.36099919232766
- 1:52.23353159163906
- 0:12.36167454634905
- 1:52.23314607860905
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.792946960017524
- 1:53.22928111453111
- 0:12.792817381254375
- 1:53.22923647703053
- 0:12.791992028933512
- 1:53.22758219724774
- 0:12.775087179509162
- 1:53.18950402501372
- 0:12.603297554730299
- 1:52.79827264533943
- 0:12.434463585247919
- 1:52.40680858265385
- 0:12.393387201506282
- 1:52.310406268570944
- 0:12.375621060164766
- 1:52.26846550304766
- 0:12.362512818636297
- 1:52.237416828356835
- 0:12.360981090781442
- 1:52.233604959119106
- system:index:20211219T101431_20211219T101431_T33UUU
- system:time_start:1639908973637
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.75442324251871
- 1:53.14009152052262
- 0:12.754448076014555
- 1:53.1400891564082
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.200639202843606
- 1:54.13474693293676
- 0:13.200583924312603
- 1:54.13471685489546
- 0:13.200511918658362
- 1:54.13470370909029
- 0:13.200496220551054
- 1:54.1346831918939
- 0:13.197952589114983
- 1:54.12978961556023
- 0:12.98422856944267
- 1:53.65982868060211
- 0:12.775087104421045
- 1:53.18950386614954
- 0:12.755018751582945
- 1:53.14381009799963
- 0:12.754230374174337
- 1:53.141624690926605
- 0:12.754305978779511
- 1:53.14017653201493
- 0:12.754369092437464
- 1:53.140136209931256
- 0:12.75442324251871
- 1:53.14009152052262
- system:index:20211219T101431_20211219T101431_T33UUV
- system:time_start:1639908959030
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211222T102441_20211222T102436_T32UQD
- system:time_start:1640168772327
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211222T102441_20211222T102436_T32UQE
- system:time_start:1640168757969
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211222T102441_20211222T102436_T33UUU
- system:time_start:1640168771485
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211222T102441_20211222T102436_T33UUV
- system:time_start:1640168757418
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.772886435916584
- 1:53.18992610553391
- 0:12.772805198089326
- 1:53.18990913361614
- 0:12.75714285859853
- 1:53.15476598210154
- 0:12.55591109012247
- 1:52.696037892151594
- 0:12.359071379351601
- 1:52.23687342470832
- 0:12.353710371487049
- 1:52.22407349038659
- 0:12.350467494463807
- 1:52.216061616308714
- 0:12.350406000409583
- 1:52.21524500448177
- 0:12.350445905956233
- 1:52.21521452364345
- 0:12.35045189068122
- 1:52.21517233370591
- 0:12.350796687962411
- 1:52.21505389958939
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.772949454149359
- 1:53.1899559993205
- 0:12.772886435916584
- 1:53.18992610553391
- system:index:20211224T101329_20211224T101331_T32UQD
- system:time_start:1640340968955
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.170470900668464
- 1:54.075879298328516
- 0:13.170332294261199
- 1:54.07584175576096
- 0:13.169239851957446
- 1:54.07423676843153
- 0:13.166922890895584
- 1:54.069454981762945
- 0:13.157615799018007
- 1:54.04980754504238
- 0:12.954569318391872
- 1:53.6011749873886
- 0:12.756012276840902
- 1:53.1521029846943
- 0:12.73695605713985
- 1:53.108449560666884
- 0:12.734680602046184
- 1:53.10307679191295
- 0:12.73534065656124
- 1:53.1026357543057
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.170470900668464
- 1:54.075879298328516
- system:index:20211224T101329_20211224T101331_T32UQE
- system:time_start:1640340954075
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.358480971053071
- 1:52.23307737154382
- 0:12.358505263098436
- 1:52.23307512390834
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.790252576440476
- 1:53.229231165558666
- 0:12.790198731550948
- 1:53.22920092722376
- 0:12.790128414523867
- 1:53.22918760707141
- 0:12.79011318272951
- 1:53.22916703709699
- 0:12.788482902528463
- 1:53.22589873011103
- 0:12.78123573679767
- 1:53.20957886537624
- 0:12.56786612384581
- 1:52.72336776060576
- 0:12.359033342032403
- 1:52.2367980251757
- 0:12.358279337349165
- 1:52.2346100887584
- 0:12.358365374543164
- 1:52.23316206754682
- 0:12.358427493653917
- 1:52.23312189515563
- 0:12.358480971053071
- 1:52.23307737154382
- system:index:20211224T101329_20211224T101331_T33UUU
- system:time_start:1640340968097
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19696787477602
- 1:54.13469198006072
- 0:13.196912484881627
- 1:54.134661913032936
- 0:13.196840483878612
- 1:54.13464876462877
- 0:13.196824788748536
- 1:54.13462824683483
- 0:13.195129244525855
- 1:54.13136572978614
- 0:13.188397934606654
- 1:54.117240232319176
- 0:13.183364496287716
- 1:54.106376917488305
- 0:12.967507242241254
- 1:53.62987848386955
- 0:12.756334480055884
- 1:53.15300759541311
- 0:12.752329795949382
- 1:53.14375926694303
- 0:12.751541432444375
- 1:53.14157394061097
- 0:12.751617113714017
- 1:53.14012570274559
- 0:12.751680265903687
- 1:53.14008546167847
- 0:12.751737747953547
- 1:53.14003799176532
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- system:index:20211224T101329_20211224T101331_T33UUV
- system:time_start:1640340953487
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:11.99449698778205
- 1:53.21201876988434
- 0:11.994491344764983
- 1:53.2120041701981
- 0:11.96060210441589
- 1:52.71923066461332
- 0:11.927685128268587
- 1:52.22640863469824
- 0:11.927741963592153
- 1:52.22636566008588
- 0:11.927789668480477
- 1:52.22631876855151
- 0:11.927813630029222
- 1:52.226315331231056
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530820936664536
- 1:52.17561928953636
- 0:13.530898432761184
- 1:52.175647461160665
- 0:13.530904492237884
- 1:52.17566201641322
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.633978294286765
- 1:53.159471540857815
- 0:13.63393142168452
- 1:53.15951916835763
- 0:13.633907090959049
- 1:53.15952292063413
- 0:11.994647235721672
- 1:53.21208275239454
- 0:11.994575520561002
- 1:53.21204795418014
- 0:11.99449698778205
- 1:53.21201876988434
- system:index:20211227T102339_20211227T102359_T32UQD
- system:time_start:1640600766721
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.058835802020626
- 1:54.10924802002459
- 0:12.058829963647693
- 1:54.10923342348372
- 0:12.023070244245325
- 1:53.616563018830966
- 0:11.988354941797661
- 1:53.12384329690895
- 0:11.98841290361927
- 1:53.12380041428173
- 0:11.988461522555125
- 1:53.123753404163416
- 0:11.988485971830267
- 1:53.12374999594657
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624476971413024
- 1:53.071391299281146
- 0:13.624556249559038
- 1:53.07141942681197
- 0:13.62456251475688
- 1:53.07143399102761
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733281374821246
- 1:54.054960691719664
- 0:13.73323372267619
- 1:54.05500832081461
- 0:13.733208938433686
- 1:54.05501213094856
- 0:12.058989396037521
- 1:54.10931192485781
- 0:12.058916067185285
- 1:54.109277173467234
- 0:12.058835802020626
- 1:54.10924802002459
- system:index:20211227T102339_20211227T102359_T32UQE
- system:time_start:1640600752358
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.648057930956336
- 1:53.24204959567913
- 0:13.648039047356248
- 1:53.24205011860283
- 0:12.004754669869694
- 1:53.21206771042417
- 0:12.004688008655881
- 1:53.21202948383028
- 0:12.004613903020092
- 1:53.21199651891384
- 0:12.004610248145692
- 1:53.211981633223765
- 0:12.038509561942993
- 1:52.71920849598536
- 0:12.071436470520608
- 1:52.2263868137535
- 0:12.071498947423871
- 1:52.22634687089817
- 0:12.071552673874363
- 1:52.22630240595803
- 0:12.071576891967828
- 1:52.22630022721864
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678315188082466
- 1:52.255274600602014
- 0:13.678388796051863
- 1:52.255306497850256
- 0:13.678392978742467
- 1:52.25532137327541
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648129873173273
- 1:53.242002601441406
- 0:13.648076362367002
- 1:53.24204770126894
- 0:13.648057930956336
- 1:53.24204959567913
- system:index:20211227T102339_20211227T102359_T33UUU
- system:time_start:1640600765878
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.61896687617674
- 1:54.140272713348935
- 0:13.61894759934395
- 1:54.140273235392854
- 0:11.94039968233344
- 1:54.10929635858776
- 0:11.940331696448316
- 1:54.10925805496081
- 0:11.940256120913341
- 1:54.10922498456894
- 0:11.940252392539296
- 1:54.10921009017219
- 0:11.976022764794806
- 1:53.616540112206856
- 0:12.010748518104222
- 1:53.12382081903657
- 0:12.010812256924543
- 1:53.12378091409624
- 0:12.010867215972695
- 1:53.12373657586139
- 0:12.010892087028454
- 1:53.123734368925646
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650886997617118
- 1:53.15365883875618
- 0:13.65096213360605
- 1:53.15369074633096
- 0:13.65096640938063
- 1:53.15370564362297
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.619040507996726
- 1:54.140225761477055
- 0:13.618985852035708
- 1:54.14027086971322
- 0:13.61896687617674
- 1:54.140272713348935
- system:index:20211227T102339_20211227T102359_T33UUV
- system:time_start:1640600751807
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.771990357382057
- 1:53.18995448130743
- 0:12.771909045752166
- 1:53.189937349790696
- 0:12.575118002659375
- 1:52.74079183856124
- 0:12.382549692085835
- 1:52.291248495626554
- 0:12.360029925718425
- 1:52.23792531956254
- 0:12.353588608666588
- 1:52.22245788495414
- 0:12.35142545890154
- 1:52.217113746899436
- 0:12.351275923202813
- 1:52.21513030329841
- 0:12.351382585872479
- 1:52.21503719929329
- 0:13.530749715810217
- 1:52.175585354190666
- 0:13.530903282853268
- 1:52.17564920565067
- 0:13.55613038275243
- 1:52.42163777596658
- 0:13.581722202501881
- 1:52.66758695490386
- 0:13.60768790378068
- 1:52.913517017611646
- 0:13.63403464064338
- 1:53.15942783116559
- 0:13.63392855064743
- 1:53.15952209643017
- 0:12.77205341171535
- 1:53.189984455111734
- 0:12.771990357382057
- 1:53.18995448130743
- system:index:20211229T101431_20211229T101430_T32UQD
- system:time_start:1640772975446
- type:Image
- id:ndvi
- crs:EPSG:32632
- 0:20
- 1:0
- 2:699960
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.73333880555003
- 1:54.05491683937858
- 0:13.733230888567407
- 1:54.05501127559762
- 0:13.17035123446678
- 1:54.07588346708196
- 0:13.169183973810362
- 1:54.073695112992645
- 0:13.16450068070495
- 1:54.063601288606854
- 0:12.952885543723422
- 1:53.597722814694606
- 0:12.746125440894527
- 1:53.131367399237746
- 0:12.739399358710221
- 1:53.11592813717332
- 0:12.734883347417922
- 1:53.10526756453952
- 0:12.734664695858061
- 1:53.10274705412164
- 0:12.734772569932963
- 1:53.102653525755564
- 0:13.624404108709518
- 1:53.071357494195986
- 0:13.624561081726936
- 1:53.07142112071907
- 0:13.651158830194037
- 1:53.317339878150804
- 0:13.678148027691043
- 1:53.56321862101742
- 0:13.705538625922783
- 1:53.80907770370645
- 0:13.73333880555003
- 1:54.05491683937858
- system:index:20211229T101431_20211229T101430_T32UQE
- system:time_start:1640772960567
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:5900040
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:12.35836708756032
- 1:52.23347598556311
- 0:12.358390693270993
- 1:52.233458747776254
- 0:12.35899711215372
- 1:52.23311258460888
- 0:12.359074272963237
- 1:52.233087854550874
- 0:13.678248498138956
- 1:52.25523726139369
- 0:13.678393418220333
- 1:52.255308432070365
- 0:13.663512502350024
- 1:52.748667540189466
- 0:13.648192242427154
- 1:53.241961831731096
- 0:13.648073175299807
- 1:53.24205050168867
- 0:12.789354406658127
- 1:53.22921453474213
- 0:12.789299240815925
- 1:53.229183520656015
- 0:12.789222574997481
- 1:53.22916738137252
- 0:12.608871682483354
- 1:52.81834697008916
- 0:12.431788798712747
- 1:52.407289984887214
- 0:12.378370931582351
- 1:52.28147637030715
- 0:12.362943228619296
- 1:52.244980881541295
- 0:12.359097271209828
- 1:52.23572007957512
- 0:12.358347086653579
- 1:52.23354313327575
- 0:12.358376098754166
- 1:52.23351165827636
- 0:12.35836708756032
- 1:52.23347598556311
- system:index:20211229T101431_20211229T101430_T33UUU
- system:time_start:1640772974588
- type:Image
- id:ndvi
- crs:EPSG:32633
- 0:20
- 1:0
- 2:300000
- 3:0
- 4:-20
- 5:6000000
- type:PixelType
- max:1
- min:-1
- precision:float
- 0:5490
- 1:5490
- type:Polygon
- 0:13.196838083734624
- 1:54.13464640743197
- 0:13.196823480910869
- 1:54.13462559870967
- 0:13.191785989451548
- 1:54.12376298951916
- 0:12.978977683753731
- 1:53.65569464381602
- 0:12.770712512743197
- 1:53.18726423046995
- 0:12.750649371793546
- 1:53.14156876073176
- 0:12.750645759522303
- 1:53.14154595235957
- 0:12.750716198727762
- 1:53.14019860015889
- 0:12.75076074626071
- 1:53.140170144402134
- 0:12.750772219724773
- 1:53.14012833958154
- 0:12.751126721912343
- 1:53.14003000043828
- 0:12.751174266962886
- 1:53.14002734009454
- 0:13.650819022336758
- 1:53.15362149465461
- 0:13.650966757544941
- 1:53.15369271757525
- 0:13.635271528022333
- 1:53.646971131206634
- 0:13.619104245456509
- 1:54.14018503345008
- 0:13.618982528076272
- 1:54.14027362541403
- 0:13.19696787477602
- 1:54.13469198006072
- 0:13.196911228834677
- 1:54.134661121630664
- 0:13.196838083734624
- 1:54.13464640743197
- system:index:20211229T101431_20211229T101430_T33UUV
- system:time_start:1640772959976
Harmonic function#
In this exercise, I fit a first-order harmonic model of the form:
\(\hat{y}(t) = \beta_0 + \beta_1 t + \beta_2 cos(2\pi \frac{t}{T}) + \beta_3 sin(2\pi \frac{t}{T})\)
The harmonic model is fitted to every pixel, i.e., we will estimate the parameters \(\beta_0\), \(\beta_1\), \(\beta_2\), and \(\beta_3\) for every pixel. The \(\beta\)´s are parameters for \(t\) and different transformations of \(t\), where \(t\) is time in days or (fractional) years and \(T\) is the period. The period \(T\) describes how many \(t\) it takes to complete a full harmonic cylce. For example, \(T\) is 1 if \(t\) is in years and 365 if \(t\) is in days. The model estimates \(\hat{y}\), which is the NDVI in our case.
The first step is to assemble the response (NDVI) and predictor variables. The function addPredictorVariables() adds four bands to an NDVI image. The four bands are the intercept and the predictors, i.e., \(t\) and its harmonic tranformations. The band constant has the pixel value 1 and is required to fit an intercept. The band time, associated with parameter \(\beta_1\), is time \(t\) expressed in years since January 1st 1970. It is a fractional value with decimal places. Now, the predictor variables do not vary for a specific NDVI image, i.e., \(t\) is constant for a specific image. However, recall that we fit time series to individual pixels. You also see that we can create an image with a scalar value simply by calling ee.Image(scalar). Earth engine will expand the scalar value in space as needed, i.e., defined by the output region.
def addPredictorVariables(image):
date = ee.Date(image.get('system:time_start'))
time = date.difference(ee.Date('1970-01-01'), 'year')
sin = time.multiply(2 * np.pi ).sin()
cos = time.multiply(2 * np.pi ).cos()
predictors = ee.Image([sin, cos, time, 1]).float()
return predictors.addBands(image.select(['ndvi'])) \
.rename(['sin', 'cos', 'time', 'constant', 'ndvi']) \
.set('system:time_start', image.get('system:time_start'))
trainingCollection = ndviS2.map(addPredictorVariables)
Fit model#
Now, we can estimate the \(\beta\)´s using linear regression. The reducer is not aware of variable names and their order in the image. It assumes the last variable to be the response variable. So, we make sure that NDVI (responseName) is selected last.
The output of the regression reduction (trend) contains two bands: coefficients and residuals. However, trend is an array image and not a standard image. An array image can store an entire vector/array in each pixel not just a scalar value. For example, an array image can store a six-band image in a single band, where each pixel would contain a vector of length six. However, pixels in an array image do not have to store vectors of the same length. In our case, the coefficients band stores the coefficients in a 4x1 array in each pixel. To turn this into a four band image, we need to apply arrayProject (removes the second axis of length 1) and arrayFlatten (puts every array element into its own band).
responseName = ee.String('ndvi')
predictorNames = ee.List(['constant', 'time', 'cos', 'sin'])
trend = trainingCollection.select(predictorNames.add(responseName)) \
.reduce(ee.Reducer.linearRegression(predictorNames.length(), 1))
coefficients = trend.select('coefficients') \
.arrayProject([0]) \
.arrayFlatten([predictorNames])
Visualizing the coefficients reveals different patterns in seasonality and trend (time) for different land cover types. The harmonic model compresse the NDVI time series into a few parameters that still represent the spectral-temporal dynamics. NOTE: the visualization of the map can take a while. The pixelwise trend fitting is processing intenstive. Keep the zoom level steady. The process restarts every time you zoom in or out.
Map.addLayer(coefficients.select(['sin']), {"min": -0.23, "max":0.1}, 'sin')
Map.addLayer(coefficients.select(['cos']), {"min": -0.23, "max":0.1}, 'cos')
Map.addLayer(coefficients.select(['time']), {"min": -0.03, "max":0.03, "palette": ['red', 'white', 'green']}, 'time')
Fitted values#
We can obtain the fitted NDVI values to better understand how our models fits the data. To do this, we need to write a funciton that takes a training image (containg NDVI, \(t\) and the harmonic terms) and applies the estimated coefficients. We then map that function to the training collection to obtain a collection of fitted NDVI images.
def linearFit(image):
fit = image.select(predictorNames) \
.multiply(coefficients) \
.reduce('sum') \
.rename('fitted')
return image.addBands(fit)
fitted = trainingCollection.map(linearFit)
Pixel observations#
Let’s evaluate the model fit for individual pixel observations. To visualize these pixels, we first extract the NDVI time series for a single pixel. Second, we extract the coefficients. And third, we extract the fitted values.
Extract NDVI time series#
pt_dbf = ee.Geometry.Point([13.18496707443565,53.06189771226909])
pt_ag1 = ee.Geometry.Point([13.134970698398053, 53.06835763719942])
pt_ag2 = ee.Geometry.Point([13.047938380282819, 53.04421500010952])
pt_ag3 = ee.Geometry.Point([13.0798673963961, 53.010351264908145])
ee_vals = ndviS2.getRegion(geometry=pt_dbf, scale=scale, crs=crs)
# use data converter to return values as python list
vals = ee.data.computeValue(ee_vals)
vals[0:3]
[['id', 'longitude', 'latitude', 'time', 'ndvi'],
['20180721T102021_20180721T102024_T32UQD',
13.184850310654017,
53.06195679914768,
1532168424461,
0.8832853025936599],
['20180721T102021_20180721T102024_T33UUU',
13.184850310654017,
53.06195679914768,
1532168424461,
0.8791130185979972]]
# convert returned list to pandas data.frame
# the first element (vals[0]) contains the column names
# the second element contains the first observation and so on
df = pd.DataFrame(vals[1:], columns=vals[0]).dropna()
# extract date string and convert it to date object
df['date'] = pd.to_datetime(df.id.str.slice(0, 8))
# copy date to row index
df.index = df.date
df.head()
| id | longitude | latitude | time | ndvi | date | |
|---|---|---|---|---|---|---|
| date | ||||||
| 2018-07-21 | 20180721T102021_20180721T102024_T32UQD | 13.18485 | 53.061957 | 1532168424461 | 0.883285 | 2018-07-21 |
| 2018-07-21 | 20180721T102021_20180721T102024_T33UUU | 13.18485 | 53.061957 | 1532168424461 | 0.879113 | 2018-07-21 |
| 2018-07-23 | 20180723T101019_20180723T101036_T32UQD | 13.18485 | 53.061957 | 1532340636891 | 0.903789 | 2018-07-23 |
| 2018-07-23 | 20180723T101019_20180723T101036_T33UUU | 13.18485 | 53.061957 | 1532340636891 | 0.909469 | 2018-07-23 |
| 2018-07-26 | 20180726T102019_20180726T102150_T32UQD | 13.18485 | 53.061957 | 1532600510652 | 0.886746 | 2018-07-26 |
The dataset may contain duplicate values due to the overlapping Sentinel-2 tiles. That is, there should only be one observation for a given day. So, let’s drop duplicate values.
df = df.drop_duplicates(subset=['date'])
df.head()
| id | longitude | latitude | time | ndvi | date | |
|---|---|---|---|---|---|---|
| date | ||||||
| 2018-07-21 | 20180721T102021_20180721T102024_T32UQD | 13.18485 | 53.061957 | 1532168424461 | 0.883285 | 2018-07-21 |
| 2018-07-23 | 20180723T101019_20180723T101036_T32UQD | 13.18485 | 53.061957 | 1532340636891 | 0.903789 | 2018-07-23 |
| 2018-07-26 | 20180726T102019_20180726T102150_T32UQD | 13.18485 | 53.061957 | 1532600510652 | 0.886746 | 2018-07-26 |
| 2018-07-31 | 20180731T102021_20180731T102024_T32UQD | 13.18485 | 53.061957 | 1533032424462 | 0.914293 | 2018-07-31 |
| 2018-08-07 | 20180807T101021_20180807T101024_T32UQD | 13.18485 | 53.061957 | 1533636624457 | 0.902853 | 2018-08-07 |
Now we can plot column ndvi against the dataframe index, which is date.
df.ndvi.plot(style='.', figsize=(5,3));
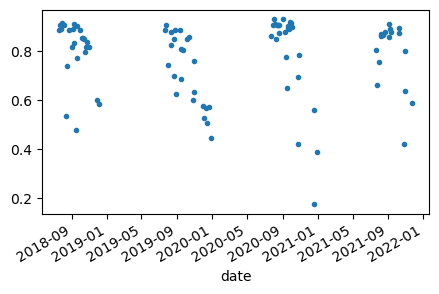
Extract coefficients#
We can extract the coefficients of the harmonic model for a single pixel using a reducer. Coefficients is an ee.Image, which has the sampleRegions reducer. You may get an exception “User memory limit exceeded”. To avoid this error, you can limit the processed area size or save intermediate results to your assets.
# returns feature collection
ee_coef = coefficients.sampleRegions(collection=pt_dbf, scale=scale,
projection=crs)
# extracts feature collection (server-side) to pandas dataFrame (client-side)
pt_coef = ee.data.computeFeatures({'expression': ee_coef, 'fileFormat': 'PANDAS_DATAFRAME'})
pt_coef.drop(columns="geo", inplace=True)
pt_coef
| constant | cos | sin | time | |
|---|---|---|---|---|
| 0 | 0.723115 | -0.162878 | -0.213892 | -0.002603 |
Extract fitted values#
Let’s extract the fitted NDVI values for a single pixel. Note, fitted is an ee.ImageCollection, which we can reduce with getRegion(). The output is a list that we can turn into a Pandas DataFrame for further analysis.
ee_fit = fitted.getRegion(geometry=pt_dbf, scale=scale, crs=crs)
pt_fit = ee.data.computeValue(ee_fit)
dfit = pd.DataFrame(pt_fit[1:], columns=pt_fit[0]).dropna() # create DataFrame and drop NA
dfit["date"] = pd.to_datetime(dfit.id.str.slice(0, 8)) # extract date from tile-id
dfit.index = dfit.date # put date into index to facilitate plotting
dfit = dfit.drop_duplicates(subset=['date']) # EE fits to duplicate values
dfit = dfit.iloc[:, np.delete(np.arange(dfit.shape[1]), 4)] # drop first 'time' column
dfit.iloc[:,4:].head(3)
| cos | time | constant | ndvi | fitted | date | |
|---|---|---|---|---|---|---|
| date | ||||||
| 2018-07-21 | -0.946117 | 48.552486 | 1 | 0.883285 | 0.820100 | 2018-07-21 |
| 2018-07-23 | -0.934459 | 48.557941 | 1 | 0.903789 | 0.825084 | 2018-07-23 |
| 2018-07-26 | -0.914793 | 48.566177 | 1 | 0.886746 | 0.832095 | 2018-07-26 |
Visualize extracted values#
dfit[["ndvi", "fitted"]].plot(style=['.', 'x'], figsize=(6,4));
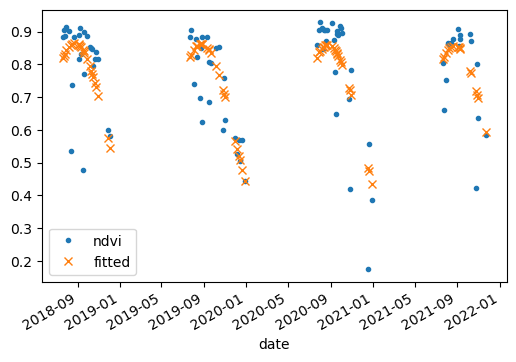
Make predictions#
def fit_harmonic(t, constant, time, sin, cos, period=1):
result = constant + time*t + \
sin*np.sin(2.0 * np.pi * (t / period)) + \
cos*np.cos(2.0 * np.pi * (t / period))
return result
def fit_trend(t, constant, time, sin, cos ):
result = constant + time*t
return result
# date difference in days
t = pd.date_range('2018-01-01', '2021-12-31', freq='D')
# date difference in yeas
td = (t - pd.to_datetime('1970-01-01')) / np.timedelta64(1, 'D') / 365.25
# convert params stored in data frame to dictionary
params = pt_coef.to_dict(orient='records')[0]
# the result is a pandas.core.indexes.numeric.Float64Index
# we can extract the values of t with t.values
fitted_harm = fit_harmonic(td.values, **params)
fitted_trend = fit_trend(td.values, **params)
dfm = pd.DataFrame({'ndvi_harm':fitted_harm,
'ndvi_trend': fitted_trend}, index=t)
ax = dfit[["ndvi", "fitted"]].plot(style=['.', 'x'], figsize=(6,4))
dfm.plot(ax=ax);
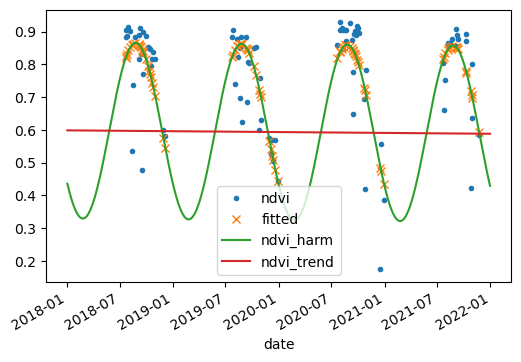
Mann-Kendall#
https://developers.google.com/earth-engine/tutorials/community/nonparametric-trends
Sen’s slope#
https://developers.google.com/earth-engine/tutorials/community/nonparametric-trends#sens_slope