We offer you three weeks of time for project work in teams. You should use this time to develop and execute a research objective in a guided setting. We will iteratively give feedback. The overall goal is to strengthen your competence in problem-solving and thus to increase your confidence in working with remote sensing and other geospatial datasets.
Project phase I
Goals
- Get familiar with the project topic
- Develop specific research questions and associated objectives
- Take a first look at study area and provided remote sensing data
Today you will start working on your projects! As a first step, we need to define the problem the topic deals with and develop a clear research question and associated objective(s). Based on this, you can construct a workflow (diagram) that illustrates the necessary methodological steps that are required to answer the research question(s).
The outcome of this block will be a brief project proposal, shortly summarizing …
- rationale & motivation
- overview of study area and time period assessed
- available + needed data (image data, training/validation)
- research question(s)
- likely objectives (+ methods) to achieve answering the research questions
Some of this information has already been laid out in the project topics, but you should refine this further and modify the research goals as you see fit.
Practical guidelines
Here is how you get there in three broad steps:
1) Specifying the scope of your project
Specify a research question (RQ) (= statements that identify the phenomenon to be studied) or hypotheses (= specific predictions about the nature and direction of the relationship between two variables) around which you can develop one or two main objectives (e.g., one related to methods, one related to LULC or global change processes). You may wish to refine objectives presented to you with the topic descriptions. Ask yourself: Why is this important? What is state-of-the-art? What pieces of information are missing?
Search for relevant literature in your project context to refine your RQs and objectives. First, you may start with the literature provided to you in the descriptions. Stick to recent publications in established journals, (e.g. Remote Sensing of Environment, Nature, Applied Earth Observation and Geoinformation, IEEE JSTARS, Global Change Biology, …).
2) Defining data requirements and methods for meeting your objectives
Once you have a first idea or even your established set of RQs, you need to define data requirements and methods for meeting your objectives. Of course, this is also very specific to your individual topic but may generally inlcude:
- Developing a class catalog including clear and precise class definitions. You may consider a hierarchical approach and aggregate thematically irrelevant classes wherever it appears useful
- Define the required temporal resolution (e.g. 5-yearly, annual, intra-annual) at which the phenomenon must ideally be observed
- Choosing a suitable (pre-)processing method (e.g. compositing, spectral-temporal metrics, time series analysis)
If your project descriptions comes with preprocessed data (e.g., STMs), your focus will most likely be on how to implement a higher level methodology and what steps are required to arrive at a desired product.
3) Investigate study area and screen data
Look at your study site in Google Earth and investigate the data you were provided with. Get familiar with the study area, e.g. the prevalence of different vegetation types and patterns, potential change over time. You may also search online for other relevant data sources which may provide further context to your study, e.g. climate maps, fire frequency, or existing land cover maps.
Browse through the available data for your study region and time frame. What is the image availability for your time period? How about cloudiness in the study region? Any other limiting factors?
Developing a research idea is an iterative process. Running into problems and realizing things don´t work as expected is part of research. In case you notice that your project idea will not work out, try to identify alternative pathways out of “the cloud”.
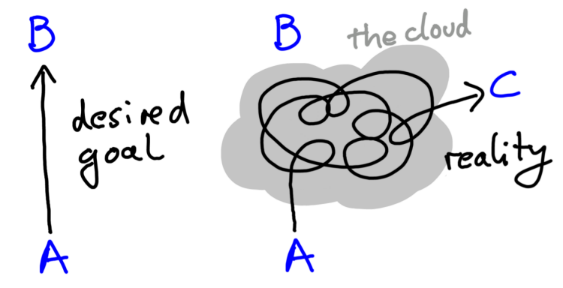
“The cloud” (Alon 2009)
Until Tuesday, 25 June 14:00PM:
Summarize your project in a maximum of 4 slides, summarising 1) the scope of your project (background + RQs), 2) study area and data, 3) objectives/methods (of course this can be your current ideas and must not be final thoughts!), 4) potential questions that already came up. Please upload your slides/PDF onto Moodle.
Project phase II-IV
Practical guidelines
Until here, you successfully managed to develop a research idea and acquired remote sensing datasets for further analyses. The next steps will vary largely depending on the specific project workflow and the following guidelines might therefore not suit every project. Feel free to follow, modify, or ignore them as you like.
Produce analysis-ready data (ARD)
In this step, you should perform the necessary (pre-)processing steps to prepare your data for subsequent analyses. Producing meaningful features for classification or regression is a critical step towards achieving your research objectives. Make use of the methods and skills you acquired during the course and take enough time to discuss the necessary data products you need and how to achieve this in your team before making a final choice. Some points to consider:
- Pre-processing (cloud masking, calibration, temporal filtering, data manipulation)
- Feature generation (indices, spectral transformations)
- Temporal domain: What is the process/phenomena of interest and how can it be adequately captured in the image data?
Reference/training data collection
You have already done this a couple of times by now. Here are some guidelines that can make your life easier.
- Make sure your classes are clearly defined. Aggregate thematically irrelevant classes wherever it appears useful.
- Define a minimum number of samples per class.
- Set up an efficient work environment, e.g., a QGIS project containing your image data, other ancillary datasets, and a VHR baselayer (e.g., using the QuickMapServices plugin).
- Make use of VHR data from Google Earth, but always consult the
historic imagery toolbar to verify the acquisition dates of these
data.
- Save your progress after each collected point or polygon.
- Explore the spectral and/or temporal characteristics of your training locations. Do they behave as expected? Are there outliers? Are your image features good discriminators for your classes of interest?
Classification or regression
Depending on your problem, choose a suitable classification / regression algorithm. Most of you will probably see Random Forest as the logical option. If it is of interest to you, try other classifiers, e.g., Support Vector Machines, Boosted Regression Trees, …. Aim to make informed decisions during the parameterization of the algorithm, e.g., by conducting sensitivity analysis based on OOB errors or cross-validation. Avoid overfitting of the models.
Once your model is trained, perform a prediction. Write your results to disk and take some time for visual assessment of the result in a GIS environment. Some of you may encounter frequently occurring errors, such as misclassification of specific land surfaces. To overcome these, try to understand where the errors come from.
- Is the error a result of erroneous or incomplete training data?
- Can you think about additional input features which allow the classifier to better separate your classes?
- Could you revise your class nomenclature in order to aggregate the confused classes while still being able to answer your research questions?
- Is post-processing a useful idea? You could, e.g., remove illogical class-transitions in change analyses, or use a spatial filter in order to remove “salt and pepper” effects?
In some of the above cases, it will be necessary to train a new model and conduct another prediction. Re-iterate if necessary.
Validation
Perform an accuracy assessment following the method for area-adjusted accuracy assessment if possible. The materials from session 6 contain a lot of information on the broad steps.
Broadly speaking, you can perform an area-adjusted accuracy assessment in case you are able to generate reference information at any random location of your study area from available datasets. If you can, the use of a stratified random sample is advised in order to control for the number of samples used per class. A method by Cochran (1977) can help you decide how many samples should overall be collected. See the second tab of the Excel spreadsheet used earlier.
Feel free to use any software environment or tool for the area-adjusted accuracy assessment, including the Excel spreadsheet. Remember that it was designed for a four class-problem, so you need to adjust it if necessary. If you do, please share the adjusted tables with the other groups.
In some cases, area-adjusted accuracy assessment is not applicable, e.g., when the classes of interest cannot be identified from available data sources. A common example are crop types or tree species. In these cases, you have two options:
Split your reference (e.g., field) data into training and validation datasets. Make sure to make the two datasets as independent as possible, e.g., by introducing a minimum distance criterion, or by avoiding training and validation samples from the same polygon.
Rely on cross-validation, e.g., k-fold cross-validation. This could be beneficial if, e.g., the number of reference datapoints is too small to allow for splitting.
Most importantly, be aware of which validation strategy is appropriate and justiy your decision.
Presentation
During the final session of Earth Observation, we will organize a mini-symposium. We kindly ask the presenting groups to upload their presentation in advance. Presentations must consist of at most 10 slides and inform about the project background and research questions (and study area), a comprehensive graph of the proposed methodological workflow, preliminary results, associated discussion points, and open questions.
The schedule is tight and presenters are urged to stay within pre-defined time slots. For every group, we schedule an oral presentation time of 10 minutes, as well as additional 10 minutes for discussions.
Until 16 July 23:59PM: Prepare your presentation using the conference slide template and upload it to Moodle.
Concerning the final project paper
Your project work will result in a written seminar paper in the style of a scientific research article. Accordingly, the seminar paper should follow the typical structure of a scientific paper, i.e. Abstract, 1) Introduction, 2) Data & Methods, 3) Results, 4) Discussion, and 5) Conclusion. We aim for full reproducibility of your work, thus please append your .R-code, additional (necessary) descriptions or plots, etc. as supplementary materials. Feel free to screen online materials for scientific writing guidelines.
The core text work should contain a maximum of 6,000 words (i.e., not counting references and appendix/supplementary materials). A fairly recent paper on How to shorten scientific manuscripts in case you are struggeling with condensing your work.
We grade the following components of your work individually and using these weights:
| Component | Weight |
|---|---|
| Abstract + Introduction + Literature | 20 % |
| Methods + Results | 30 % |
| Discussion + Conclusion | 30 % |
| Analyses (Code / Documentation) | 10 % |
| Form / figures / language | 10 % |
The submission deadline for the MAP is 30 September 2024 23:59. Please send your MAP paper (or a link to download the paper+suppl. material from HU-Box) to us via e-mail.
Copyright © 2020 Humboldt-Universität zu Berlin. Department of Geography.
![]()